







文章目录
一、介绍
在本文中:
(1)研究为什么单阶段目标检测算法精度相对较低:因为在训练过程中会有极端的前-背景类不平衡的问题(类不平衡)。
(2)提出解决类不平衡的方法:通过重新构造标准交叉熵损失来解决这种类不平衡,这样它就可以降低分配给分类良好的示例的损失。新focal损失集中训练稀疏的一组难例,并防止大量简单的负例压倒训练期间的检测器。
(3)提出RetinaNet:当使用focal损失训练时,能够达到以前单级探测器的速度,同时超过所有现有的最先进的两阶段检测器的精度。
2.1 什么是类不平衡
什么是类不平衡:
单阶段目标检测算法,会产生大量的先验边界框(anchor box),在一幅图像中,目标的数量很少,因此绝大多数的先验框都是背景类。因此背景与前景的类数量极其不平衡。
解决类不平衡的常见解决方案:
执行某种形式的难负例挖掘,在训练期间对难例进行采样,或者执行更复杂的采样/重新权衡方案;focal损失,允许有效地训练所有的示例,而不需要采样,也不会有简单负例压倒损失和计算出的梯度。
2.2 类不平衡为什么影响检测的精度
类不平衡为什么影响检测精度:
因为单阶段目标检测器先验框(anchor box)的数量庞大,其中背景类的先验框占据极大的一部分比例,因此如果分类器无脑的把所有的先验框统一分类为背景类,这样分类的精度也很高。于是,分类器的训练就失败了,结果检测精度会降低。
2.3 two-state如何解决类不平衡
two-state解决类不平衡:
两阶段目标检测算法的类不平衡是通过两级级联和采样启发来解决的。
提案阶段(候选区域生成阶段):迅速将候选区域位置的数量缩减到一个小的数量(例1-2k),这个过程中过滤掉了大部分背景样本,因此极大的减轻了类不平衡问题。 第二个分类阶段:执行采样启发,例如固定的前、背景类样本比(1:3),或在线硬示例挖掘(OHEM),以保持前景和背景类之间的平衡。
2.4 one-state为何有严重类不平衡
one-state类不平衡:
单阶段目标检测算法中,有大量的‘候选目标位置’(anchor box),这些候选目标位置是通过在图片中有规律的采样得到,实际中这会枚举约100k个位置,由于一张图片中目标的数量很少,因此这些anchor中的正负样本的比例严重失衡,引起两个问题:
1.样本类不平衡。
2.容易分类的负样本的损失主导总loss,虽然大量的负样本是easy 样本、是准确率很高的第0类,但是由于数量很多,因此加起来的loss 甚至大于正样本的loss;在单阶段检测网络中loss由负样本主导,但是负样本大多数准确率很高。会影响网络的训练。
focal损失:
focal损失函数是一个动态缩放的交叉熵损失,当对正确类的信心增加时,比例因子衰减为零,这个比例因子可以自动降低训练过程中简单例子的权重,并快速地将模型集中在困难的例子上。
实验表明,通过这种方法能够训练一个高精度的单阶段目标检测器,性能显著优于使用采样启发法或硬示例挖掘(以前的单级检测器训练技术)训练的备选方案。
二、相关工作
传统目标检测:
滑动窗口模式。滑动窗口方法是经典计算机视觉中最主要的检测范例,但是随着深度学习的复兴,两级检测器很快就开始主导对象检测。
两阶段检测器:
第一阶段生成一个稀疏的候选建议集,它应该包含所有对象,同时过滤掉大多数负面位置,第二阶段将建议分类为前景类/背景类。两阶段目标检测是精确的目标检测器,基于R-CNN推广的两阶段方法,精度目前最高,但是速度很慢。
单阶段检测器:
OverFeat是第一个基于深度网络的单阶段目标检测器。最近,SSD和YOLO重新对单阶段方法产生了兴趣。这些检测器已经调整了速度,但其准确性低于两阶段方法。单阶段目标检测算法对目标位置进行常规、密集的采样,这种单阶段检测器更快、更简单,但到目前为止,其准确度仍落后于两阶探测器。
RetinaNet检测器:
设计与之前的稠密探测器有很多相似之处,特别是RPN中引入的“anchor”的概念以及SSD和FPN中特征金字塔的使用。RetinaNet之所以能取得最好的结果,不是因为在网络设计上的创新,而是因为新损失函数。
鲁棒估计:
鲁棒损失函数通过减少具有较大错误的示例(硬示例)的损失来减少异常值的贡献。与此相反,focal损失不是处理异常值,而是通过减权来解决类不平衡,作用与鲁棒损失相反:它将训练集中在一组稀疏的硬例子上。
三、focal损失
单阶段目标检测器在训练过程中前景类和背景类数量有一个极端的不平衡(例1:1000)。
3.1 交叉熵损失:
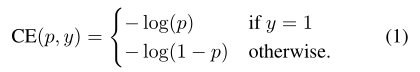
y∈{±1},p∈[0,1]是标签y = 1的类的估计概率。为了方便标记,定义pt:
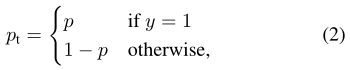
交叉熵损失:CE(p, y) = CE(pt) =−log(pt)
交叉熵损失的一个值得注意的性质:很容易分类的例子(pt>5)有非常小的损失。但当存在大量的容易分类的例子时,这些小的损失值相加后也会变很大,可以压倒其他类的损失。
3.2 平衡交叉熵损失
为类1引入权重因子α,α∈[0,1],为类-1引入1−α。为了书写便利,定义αt同定义pt一样。α-balanced CE损失为:
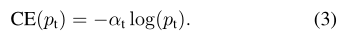
平衡交叉熵损失:是对CE(交叉熵损失)的简单扩展,只能平衡positive/negtive样本的重要性,不能区分easy/hard样本。
3.3 focal损失
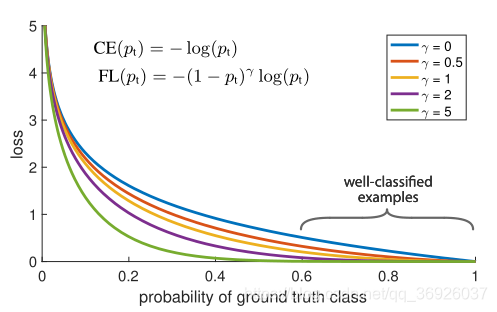
focal损失:通过重塑交叉熵损失来降低easy样本的权重,把更多注意力放在hard negtive样本的训练上:
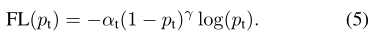
focal loss的两个性质:
(1) 调节因子(1−pt)γ减少易分类样本的损失:无论是前景类还是背景类,pt越大,调节因子(1−pt)γ就越小。也就是说easy 例可以通过权重对他们的损失进行抑制。即当某样本类别比较明确,分类比较正确时,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。
通过调节因子,损失更加关注于难以区分的样本,减少了简单(易分类)样本的影响,这样很小的难例样本叠加起来后的效应才可能有效。

(2) 平衡因子α平衡正负样本的比例:采用α在实验中,因为它比non-α-balanced形式提高了精度。
通过使用focal loss正负样本能共同主导总loss(通常单阶段目标检测算法,由于容易分类的负样本占很大的比例,因此容易分类的负样本占据了整个训练的损失,主导了梯度。)。
四、RetinaNet检测器
4.1 网络结构
RetinaNet是由一个主干网络和两个特定于任务的子网组成的统一的网络。主干网络:负责在整个输入图像上计算卷积特征图。第一子网络:对主干输出进行卷积分类;第二个子网络:执行卷积边界框回归。
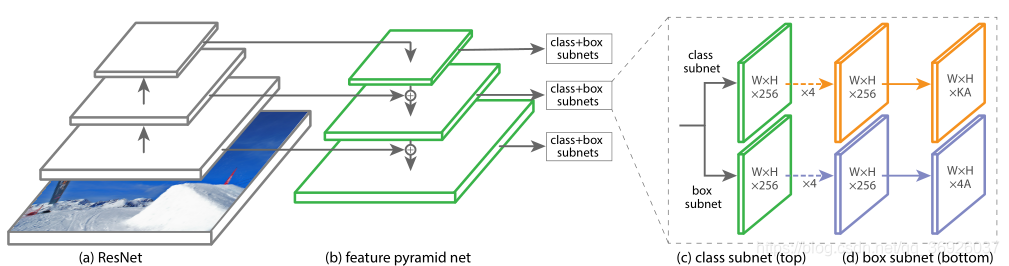
特征金字塔网络作为主干网络:
采用特征金字塔网络(FPN)作为RetinaNet的主干网络。简而言之,FPN通过自顶向下路径和横向连接扩展了一个标准的卷积网络,因此该网络从一个分辨率输入图像有效地构建了一个丰富的、多尺度的特征金字塔,如图(a)-(b)。金字塔的每一层都可以用来探测不同尺度的目标。在ResNet架构之上构建FPN,构建了一个包含P3到P7层的金字塔,(Pl分辨率比输入低2l,其中l表示金字塔级别)。
anchor:
平移不变的anchorbox,在金字塔的P3 - P7层,anchor的面积分别为32×32 - 512×512。每个金字塔层,使用三个纵横比(1:2,1:1,2:1)的anchor,对于更密集的尺度覆盖,在每一层另添加了3个纵横比{20、21/3、22/3}的anchor,因此每层总共有9个默认anchor。
每个anchor:
(1)分配一个长度为K的one-hot向量,用来分类,其中K为对象类的个数;
(2)分配一个4维向量,表示边界框回归目标。
使用RPN的赋值规则,但修改了多类检测和调整阈值,anchor使用0.5的IoU阈值,用来区分是把anchor分配给ground-truth真值框(IOU∈[0.5,1])还是背景(IOU∈[0,0.4])。每个anchor最多分配给一个真值框,将其长度K 的向量中的相应条目设置为1,而所有其他条目设置为0。如果一个anchor没有被分配,这说明IOU在[0.4,0.5],它在训练过程中被忽略。边界框回归目标被计算为每个anchor与其分配对象框之间的偏移量,如果没有分配则省略。
分类子网:
分类子网为每个空间位置的A个anchor,都预测K个对象类概率。这个子网是一个小的FCN附加到每个FPN层,这个子网的参数在所有金字塔层上共享。
从一个给定的金字塔层上取一个带有C通道的输入特征图,子网应用4个3×3的conv层,每个层有C个过滤器,每个层后面有ReLU激活函数,每个层后面有一个带有KA过滤器的3×3的conv层。最后,sigmoid激活被附加到每个空间位置输出的KA二元预测,图 ©。
与RPN相比,分类子网更深,只使用3×3 convs,并且不与边界框回归子网共享参数。这些更高级的设计决策比超参数的特定值更重要。
边界框回归子网:
与分类子网并行,在每个金字塔层附加另一个小FCN,目的是将每个anchor的偏移量回归到附近的ground-truth对象(如果存在的话)。对于每个anchor/空间位置,输出四个预测,表示与groundtruth框之间的相对偏移量。
使用的是一个类无关的边界框回归器,它使用的参数更少,并且效率是一样的。对象分类子网和边界框回归子网虽然具有相同的结构,但使用不同的参数。
4.2 推断和训练
推断:
推理只涉及通过网络处理一个图像。为了提高速度,只对每个FPN层最多1k的最高得分预测的边界框进行解码。将所有层的最高预测合并,并使用阈值为0.5的非最大抑制来产生最终的检测。
focal loss:
使用focal loss作为分类子网输出的损失。训练RetinaNet时,focal 损失应用于每个采样图像中的所有约100k个anchor。与通常启发式抽样(RPN)或硬示例挖掘(OHEM, SSD)为每个小批选择一小组anchor(例如,256)的做法形成了对比。
图像的总focal损失计算为所有约100k个anchor的focal损失之和,并由分配给ground-truth框的anchor数量进行标准化。由于绝大多数anchor都是简单负样本,且在focal的损失值可以忽略不计,所以用分配的anchor个数来进行归一化,而不是全部anchor。
初始化:
使用ResNet-50-FPN和ResNet-101-FPN作为主干网进行了实验。在ImageNet上对基础ResNet-50和ResNet-101模型进行预训练。
初始化时:为FPN添加的新层,所有RetinaNet子网中的新conv层(除了最后一层),偏差初始化为b = 0,权重初始化为高斯分布且σ= 0.01。分类子网的最后conv层,偏差初始化成一个特殊的值 :
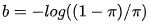
在论文中π取0.01 。在训练初始阶段因为positivie和negative的分类概率基本一致,会造成focal loss起不到抑制easy例的作用,为了打破这种情况,作者对最后一级用于分类的卷积的bias作了修改,这样做能在训练初始阶段提高positive的分类概率。
优化:
用随机梯度下降(SGD)训练RetinaNet。在8个GPU上使用同步SGD,每个minibatch总共有16张图片(每个GPU 2张)。所有模型都经过90k迭代的训练,初始学习率为0.01,然后在60k时除以10,在80k迭代时再除以10。水平图像翻转作为唯一的数据增强形式。使用0.0001的权重衰减和0.9的动量。训练损失是边界框回归的L1平滑损失和的分类的focal损失的总和。
五、实验
5.1 训练密集检测器
进行了大量的实验来分析用于稠密检测的损失函数的行为以及各种优化策略。在所有实验中,我们使用深度为50或101的ResNets,并在其上构建一个特征金字塔网络(FPN)。对于所有消融研究,使用600像素的图像尺度进行训练和测试。
标准交叉熵损失:
第一次尝试训练RetinaNet使用标准交叉熵损失(CE),而不修改初始化或学习策略。这种方法很快就会失败,因为在训练过程中网络发生了分散。简单初始化最后一层(上述设计的偏差进行初始化最后一层π= . 01),使得学习有效。使用ResNet-50对RetinaNet进行训练,这个初始化已经在COCO上生成了可观的AP 30.2。
平衡交叉熵:
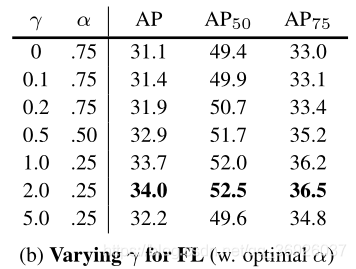
尝试改善学习涉及使用α-balanced CE损失。各种α的结果如表所示。
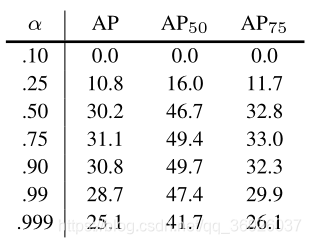
focal损失:
使用focal损失的结果如表所示。当γ= 0时,损失相当于CE损失。随着γ增加,损失的形状变化,这样“简单”的例子损失会得到进一步打折。
分析focal损失:
采用ResNet101 600像素模型,γ= 2。将这个模型应用于大量随机图像,并对10* *7正样本和∼10**5负样本窗口进行采样。接下来,分别计算这些为正、负窗口样本的focal损失,并将损失归一化,使其和为1。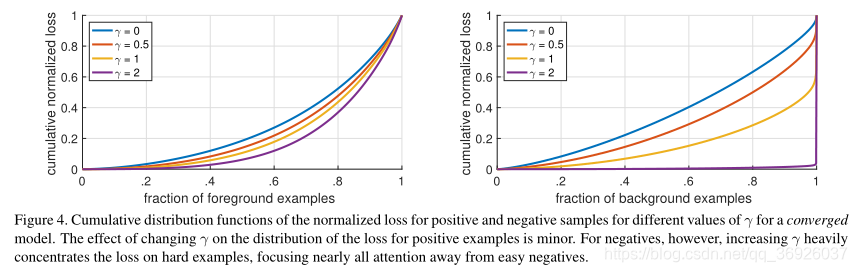
正、负样本的累积分布函数如图所示:
正样本:γ的值不同CDF看起来非常相似。例如,大约20%的难正样本占了大约一半所有正样本的损失,随着γ增加更多的损失会集中在前20%的例子,但这种影响是微不足道的。
负样本:γ在负样本的效果是截然不同的。随着γ的增加,更多的权重就集中在负面的例子,因此focal损失可以有效地忽略简单的负样本带来的损失影响,将所有的注意力集中在难的负面例子上。
在线难例挖掘(OHEM):
通过使用较大损失的例子构造小批量来改进两阶段检测器的训练。具体地说,在OHEM中,每个示例都按照其损失进行评分,然后应用非最大抑制,并使用损失最高的示例构建一个迷你批处理。nms阈值和批大小是可调参数。OHEM更强调错误分类的例子,但 OHEM完全抛弃简单的例子。
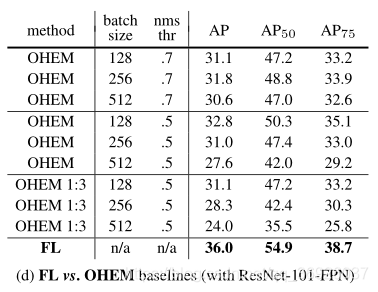
实验对比focal损失比OHEM更有效地训练稠密探测器。尝试了OHEM的其他参数设置和变体,没有取得更好的结果。
5.2 模型架构设计
速度VS精度:
较大的骨干网络产生较高的精度,但也较慢的推理速度。同样,输入图像大小也是这种情况。表中显示了这两个因素的影响。

在图中绘制了RetinaNet的速度/精度权衡曲线,并将其与最近的方法进行了比较。

5.3 对比
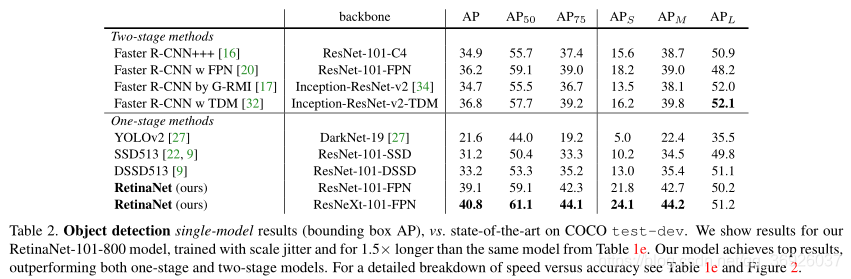
在COCO数据集上评估RetinaNet,并将测试开发结果与最新的最先进的方法(包括单阶段和两阶段模型)进行比较。
六、结论
在这项工作中,确定了类不平衡是阻止单阶段目标检测器超越性能最好的两阶段方法的主要障碍。为了解决这个问题,出了focal损失,它应用调制项交叉熵损失,以便集中学习硬的负面例子。方法简单而高效,大量的实验分析表明它达到了最先进的精度和速度。















 2869
2869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









