







文章目录
引言
卷积,是卷积神经网络中最重要的组件之一。不同的卷积结构有着不一样的功能,但本质上都是用于提取特征。比如,在传统图像处理中,人们通过设定不同的算子来提取诸如边缘、水平、垂直等固定的特征。而在卷积神经网络中,仅需要随机初始化一个固定卷积核大小的滤波器,并通过诸如反向传播的技术来实现卷积核参数的自动更新即可。其中,浅层的滤波器对诸如点、线、面等底层特征比较敏感,深层的滤波器则可以用于提取更加抽象的高级语义特征,以完成从低级特征到高级特征的映射。本文将从背景、原理、特性及改进四个维度分别梳理10篇影响力深远的经典卷积模块以及10篇具有代表性的卷积变体,使读者对卷积的发展脉络有一个更加清晰的认知。
原始卷积 (Vanilla Convolution)
背景
学习过信号与系统的同学们应该对卷积不陌生,从物理意义上来说,卷积可以定义为一个单位响应(蓝色方波)函数在另一个输入信号(红色方波)函数上的加权输出:
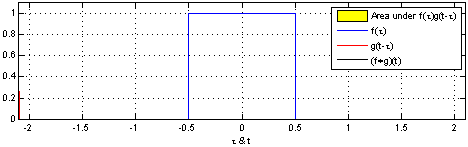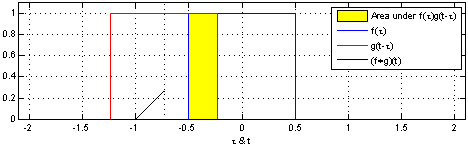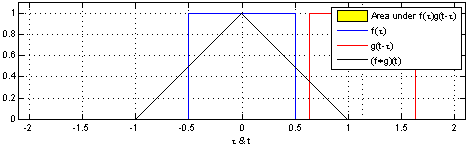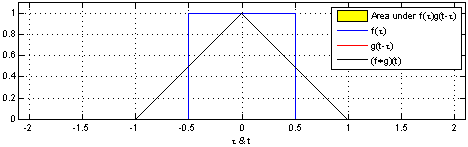
而从数学角度来分析的话,卷积代表的就是一种加权求和运算,它是通过两个函数f和g生成第三个函数的一种数学算子,其一般形式为:
f
(
x
)
∗
g
(
x
)
f(x)*g(x)
f(x)∗g(x)
从信号种类来划分,卷积有两种形式:
- 连续卷积:
( f ∗ g ) ( t ) = f ( t ) ∗ g ( t ) = ∫ − ∞ + ∞ f ( τ ) g ( t − τ ) d τ = ∫ − ∞ + ∞ f ( t − τ ) g ( τ ) d τ (f*g)(t)=f(t)*g(t)=\int^{+\infty}_{-\infty}f(\tau)g(t-\tau)d\tau=\int^{+\infty}_{-\infty}f(t-\tau)g(\tau)d\tau (f∗g)(t)=f(t)∗g(t)=∫−∞+∞f(τ)g(t−τ)dτ=∫−∞+∞f(t−τ)g(τ)dτ
变量 t t t与 τ \tau τ的辩证关系:在积分运算过程中, τ \tau τ是积分变量, t t t是参变量;积分后的结果是 t t t的函数。卷积的积分区间既与 f ( τ ) 、 g ( t − τ ) f(\tau)、g(t-\tau) f(τ)、g(t−τ)非零值的区间有关,也与 f ( τ ) 、 g ( t − τ ) f(\tau)、g(t-\tau) f(τ)、g(t−τ)图形的相对位置有关。因为函数 g ( t − τ ) g(t-\tau) g(t−τ)非零值与 t t t的取值的变化有关,所以对于 t t t的不同取值范围, ∫ − ∞ + ∞ f ( τ ) g ( t − τ ) d τ \int^{+\infty}_{-\infty}f(\tau)g(t-\tau)d\tau ∫−∞+∞f(τ)g(t−τ)dτ就有不同的积分限。详细数学推导等信息请参考wiki百科。
- 离散卷积:
( x ∗ h ) ( n ) = x ( n ) ∗ h ( n ) = ∑ m = − ∞ ∞ x ( m ) h ( n − m ) (x*h)(n)=x(n)*h(n)=\sum\limits^\infty_{m=-\infty}x(m)h(n-m) (x∗h)(n)=x(n)∗h(n)=m=−∞∑∞x(m)h(n−m)
其中,卷积神经网络中使用的卷积是二维离散卷积:
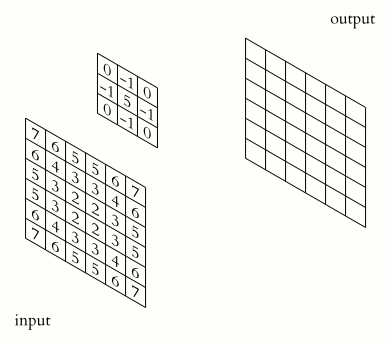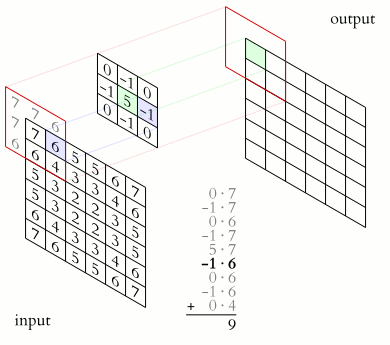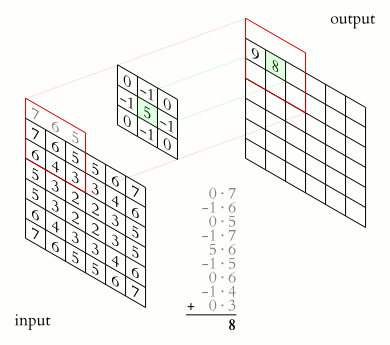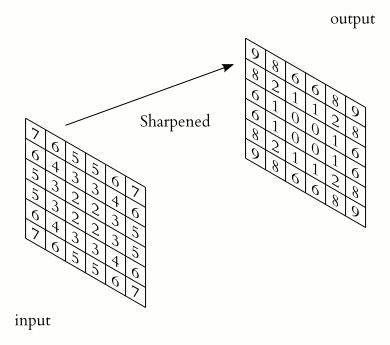
图像卷积
图像卷积操作(convolution),或称为核操作(kernel),是进行图像处理的一种常用手段。图像卷积操作的目的是利用像素点和其邻域像素之前的空间关系,通过加权求和的操作,实现模糊(blurring),锐化(sharpening),边缘检测(edge detection)等功能。
图像卷积的计算过程就是卷积核按步长对图像局部像素块进行加权求和的过程,卷积核实质上是一个固定大小的权重数组,该数组中的锚点通常位于中心。
在计算机视觉领域,卷积核、滤波器通常为较小尺寸的矩阵,比如3×3、5×5等,数字图像是相对较大尺寸的2维(多维)矩阵(张量),图像卷积运算与相关运算的关系如下图所示,其中F为滤波器,X为图像,O为结果。
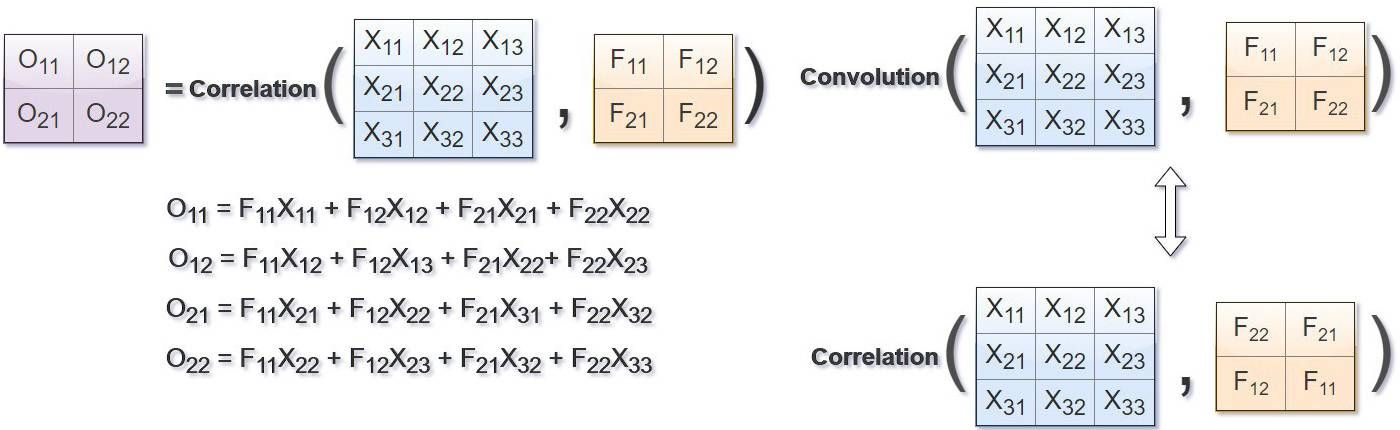
相关是将滤波器在图像上滑动,对应位置相乘求和;卷积则先将滤波器旋转180度(行列均对称翻转),然后使用旋转后的滤波器进行相关运算。两者在计算方式上可以等价,有时为了简化,虽然名义上说是“卷积”,但实际实现时是相关。
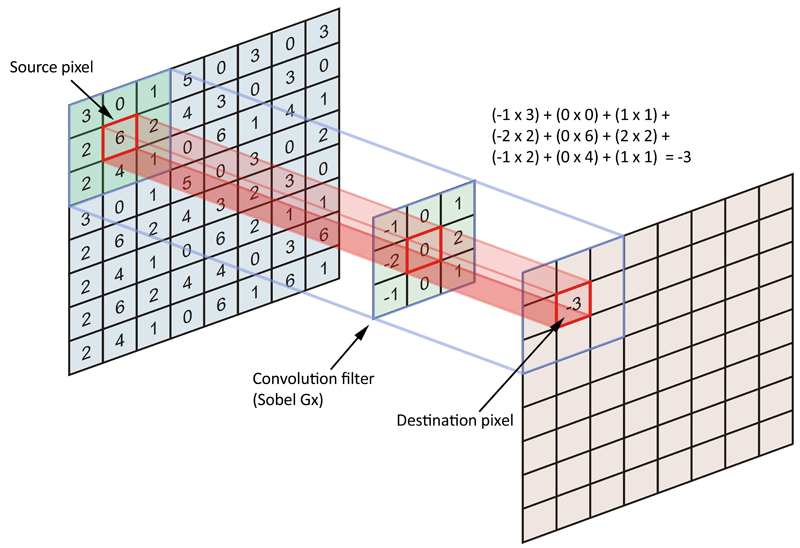
在二维图像上使用sobel Gx(横向梯度)滤波器进行卷积如下图所示:
TODO: 从零开始的深度学习(三):图像处理基础
sobel算子是图像处理中的经典算子(滤波器),对图像中横、纵两个方向进行梯度的近似计算,常用于边缘检测。
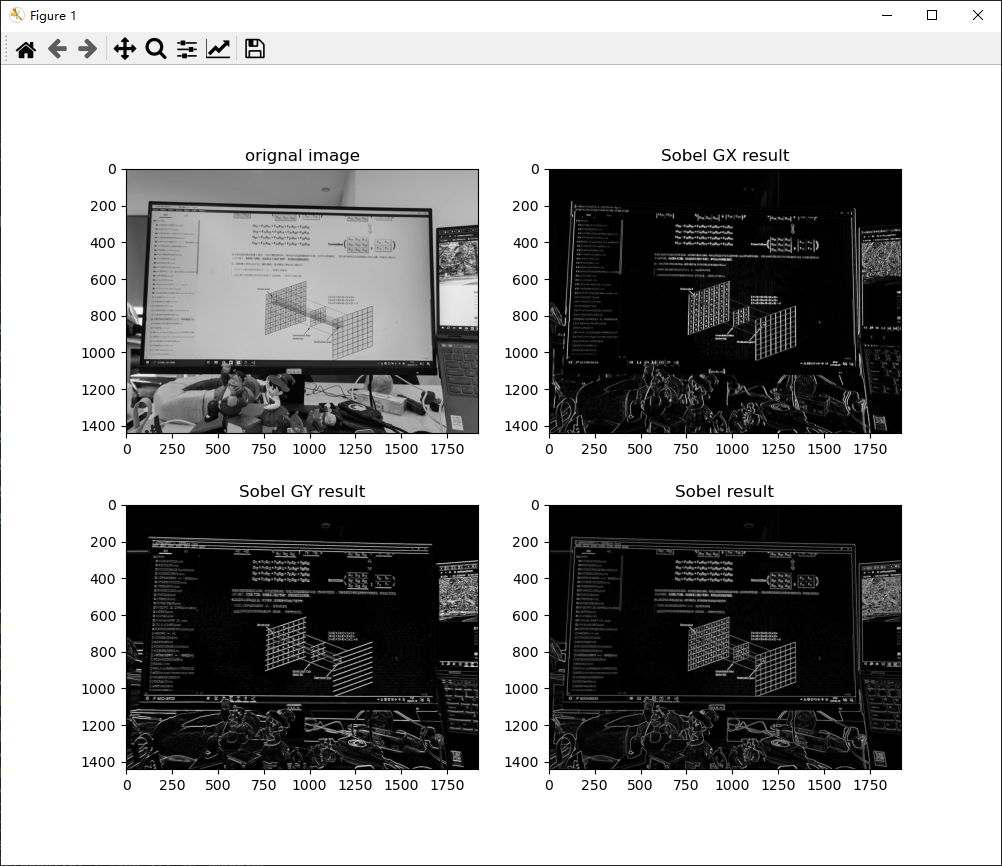
使用sobel算子对图片进行卷积操作的实例如下,Sobel GX在X轴方向上能够有效提取边缘纹理信息,Sobel GY在Y轴方向上同理,最终将二者加权,得到包含图片整体纹理信息的结果。从这个例子可以清楚地了解卷积核的作用。
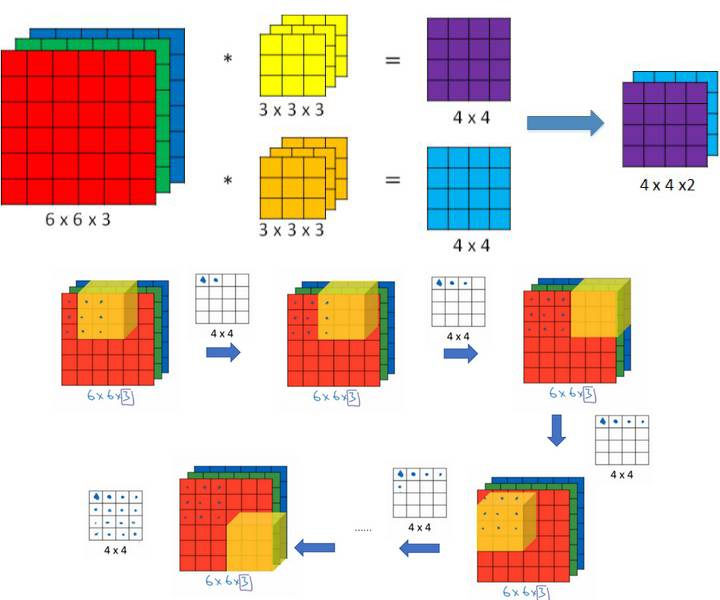
当输入为多维图像(或者多通道特征图)时,多通道卷积如下图所示(图片来自[链接](https://github.com/AlbertHG/Coursera-Deep-Learning-deeplearning.ai/blob/master/04-Convolutional Neural Networks/week1/README.md)),图中输入图像尺寸为6×6,通道数为3,卷积核有2个,每个尺寸为3×3,通道数为3(与输入图像通道数一致),卷积时,仍是以滑动窗口的形式,从左至右,从上至下,3个通道的对应位置相乘求和,输出结果为2张4×4的特征图。一般地,当输入为 m × n × c m\times n\times c m×n×c时,每个卷积核为 k × k × c k\times k\times c k×k×c,即每个卷积核的通道数应与输入的通道数相同(因为多通道需同时卷积),输出的特征图数量与卷积核数量一致,这里不再赘述。
卷积小结
这里提供两个理解卷积的角度:
- 从函数(或者说映射、变换)的角度理解。 卷积过程是在图像每个位置进行线性变换映射成新值的过程,将卷积核看成权重,若拉成向量记为 w w w,图像对应位置的像素拉成向量记为 x x x,则该位置卷积结果为 y = w ′ x + b y=w'x+b y=w′x+b,即向量内积+偏置,将 x x x变换为 y y y。从这个角度看,多层卷积是在进行逐层映射,整体构成一个复杂函数,训练过程是在学习每个局部映射所需的权重,训练过程可以看成是函数拟合的过程。
- 从模版匹配的角度理解。 前面我们已经知道,卷积与相关在计算上可以等价,相关运算常用模板匹配,即认为卷积核定义了某种模式,卷积(相关)运算是在计算每个位置与该模式的相似程度,或者说每个位置具有该模式的分量有多少,当前位置与该模式越像,响应越强。下图为图像层面的模板匹配(图片来自链接),右图为响应图,可见狗头位置的响应最大。当然,也可以在特征层面进行模版匹配,卷积神经网络中的隐藏层即可以看成是在特征层面进行模板匹配。这时,响应图中每个元素代表的是当前位置与该模式的相似程度,单看响应图其实看不出什么,可以想像每个位置都有个“狗头”,越亮的地方越像“狗头”,若给定模板甚至可以通过反卷积的方式将图像复原出来。这里多说一句,我们真的是想把图像复原出来吗,我们希望的是在图像中找到需要的模式,若是通过一个非线性函数,将响应图中完全不像“狗头”的地方清零,而将像“狗头”的地方保留,然后再将图像复原,发现复原图中只有一个“狗头”,这是不是更美好——因为我们明确了图像中的模式,而减少了其他信息的干扰!

卷积的特征提取
如果把卷积核定为“狗头”模板会有什么问题?将缺乏灵活性,或者说泛化能力不够,因为狗的姿态变化是多样的,如果直接把卷积核定义得这么“死板”,狗换个姿势或者换一条狗就不认得了。
那么,为了适应目标的多样性,卷积核该怎么设计呢?这个问题,我们在下一节回答,这里先看看人工定义的卷积核是如何提取特征的。
以下图sobel算子为例(图片来自链接),对图像进行卷积,获得图像的边缘响应图,当我们看到响应图时,要知道图中每个位置的响应代表着这个位置在原图中有个形似sobel算子的边缘,信息被压缩了,响应图里的一个数值其实代表了这个位置有个相应强度的sobel边缘模式,我们通过卷积抽取到了特征。

人工能定义边缘这样的简单卷积核来描述简单模式,但是更复杂的模式怎么办,像人脸、猫、狗等等,尽管每个狗长得都不一样,但是我们即使从未见过某种狗,当看到了也会知道那是狗,所以对于狗这个群体一定是存在着某种共有的模式,让我们人能够辨认出来,但问题是这种模式如何定义?在上一节,我们知道“死板”地定义个狗的模板是不行的,其缺乏泛化能力,我们该怎么办?
通过多层卷积,来将简单模式组合成复杂模式,通过这种灵活的组合来保证具有足够的表达能力和泛化能力。
为了直观,我们先上图,图片出自论文《Visualizing and Understanding Convolutional Networks》,作者可视化了卷积神经网络每层学到的特征,当输入给定图片时,每层学到的特征如下图所示,注意,我们上面提到过每层得到的特征图直接观察是看不出什么的,因为其中每个位置都代表了某种模式,需要在这个位置将模式复现出来才能形成人能够理解的图像,作者在文中将这个复现过程称之为deconvolution,详细查看论文(前文已经有所暗示,读者可以先独自思考下复现会怎么做)。

从图中可知,浅层layer学到的特征为简单的边缘、角点、纹理、几何形状、表面等,到深层layer学到的特征则更为复杂抽象,为狗、人脸、键盘等等,有几点需要注意:
- 卷积神经网络每层的卷积核权重是由数据驱动学习得来,不是人工设计的,人工只能胜任简单卷积核的设计,像边缘,但在边缘响应图之上设计出能描述复杂模式的卷积核则十分困难。
- 数据驱动卷积神经网络逐层学到由简单到复杂的特征(模式),复杂模式是由简单模式组合而成,比如Layer4的狗脸是由Layer3的几何图形组合而成,Layer3的几何图形是由Layer2的纹理组合而成,Layer2的纹理是由Layer1的边缘组合而成,从特征图上看的话,Layer4特征图上一个点代表Layer3某种几何图形或表面的组合,Layer3特征图上一个点代表Layer2某种纹理的组合,Layer2特征图上一个点代表Layer1某种边缘的组合。
- 这种组合是一种相对灵活的方式在进行,不同的边缘→不同纹理→不同几何图形和表面→不同的狗脸、不同的物体……,前面层模式的组合可以多种多样,使后面层可以描述的模式也可以多种多样,所以具有很强的表达能力,不是“死板”的模板,而是“灵活”的模板,泛化能力更强。
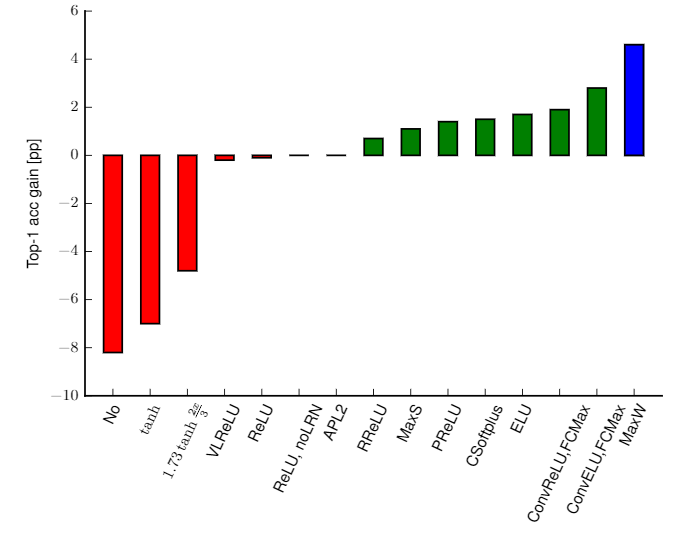
- 卷积神经网络真正使用时,还需要配合池化、激活函数等,以获得更强的表达能力,但模式蕴含在卷积核中,如果没有非线性激活函数,网络仍能学到模式,但表达能力会下降,由论文《Systematic evaluation of CNN advances on the ImageNet》,在ImageNet上,使用调整后的caffenet,不使用非线性激活函数相比使用ReLU的性能会下降约8个百分点,如下图所示。通过池化和激活函数的配合,可以看到复现出的每层学到的特征是非常单纯的,狗、人、物体是清晰的,少有其他其他元素的干扰,可见网络学到了待检测对象区别于其他对象的模式。
普通卷积特性
稀疏连接(sparse connectivity)
传统的神经网络层使用矩阵乘法,由一个参数矩阵和一个单独的参数描述每个输入和每个输出之间的交互,即每个输出单元与每个输入单元进行密集交互。
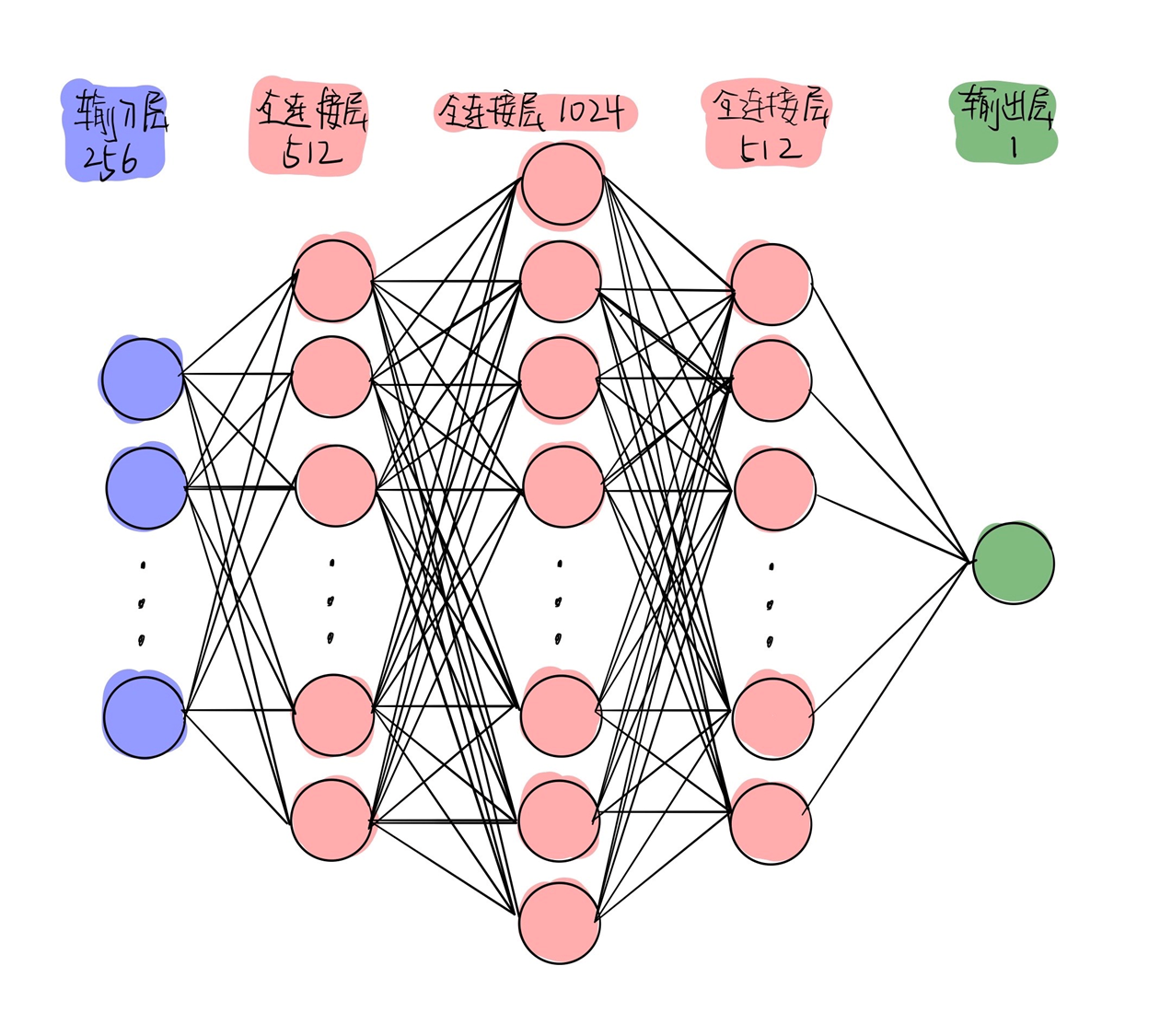
然而,卷积网络具有稀疏交互作用,有时也称为稀疏连接或稀疏权值。
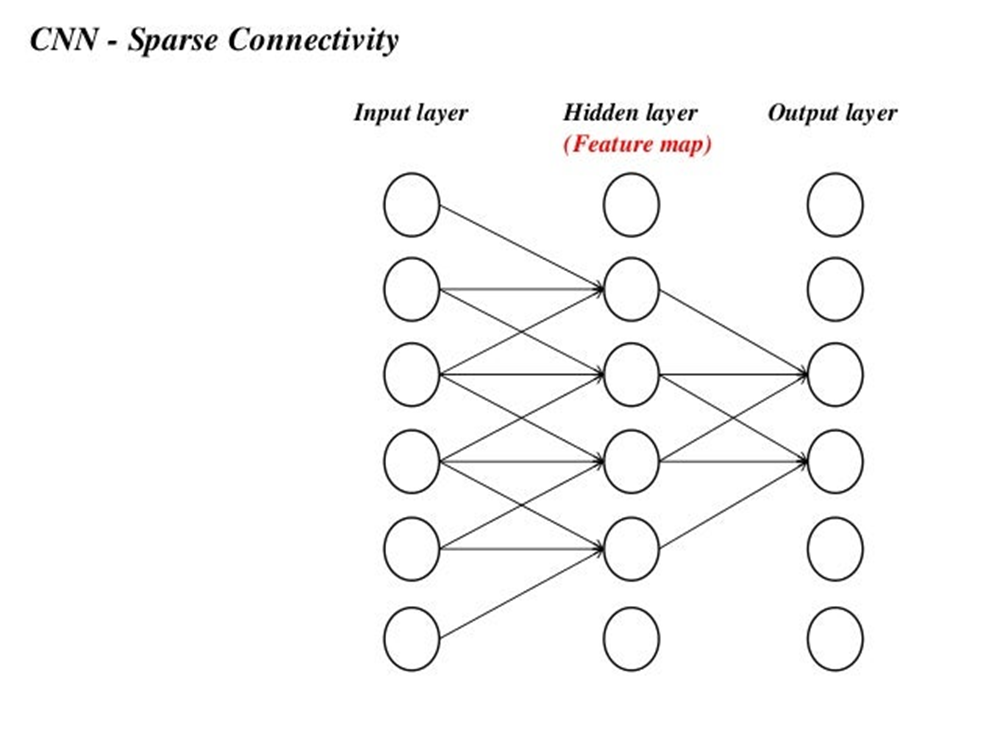
总的来说,使用稀疏连接方式可以使网络储存更少的参数,降低模型的内存要求,同时提高计算效率。
权值共享(shared weights)
在传统的神经网络中,每个元素都使用一个对应的参数(权重)进行学习。但是,在CNNs中卷积核参数是共享的。权值共享,也称为参数共享,是指在计算图层的输出时多次使用相同的参数进行卷积运算。
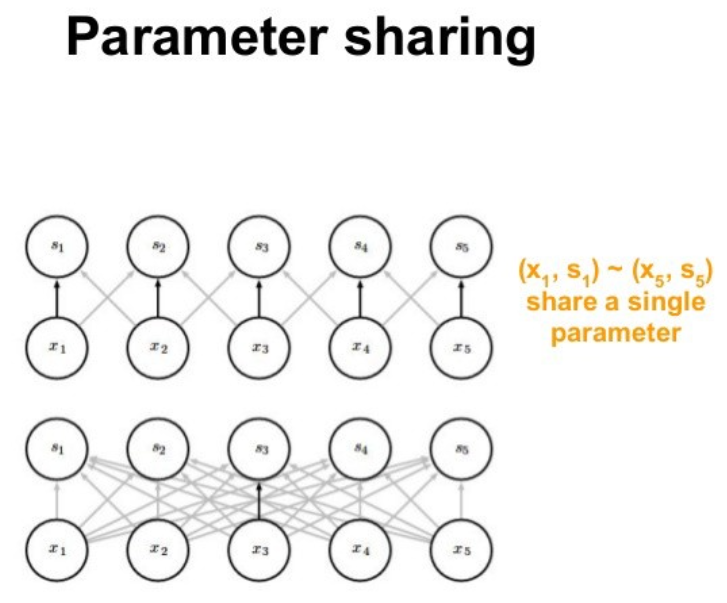
平移不变性(translation invariant)
CNNs中的平移不变性指的是当图像中的目标发生偏移时网络仍然能够输出同源图像一致的结果。对于图像分类任务来说,我们希望CNNs具备平移不变性,因为当图像中目标发生位置偏移时其输出结果应该保持一致。然而,CNNs结构本身所带来的平移不变性是非常脆弱的,大多数时候还是需要从大量数据中学习出来。关于CNN平移不变性的研究可以参考卷积网络的平移不变性以及这篇文章。
平移等变性(translation equivalence)
CNNs中的平移等变性指的是当输入发生偏移时网络的输出结果也应该发生相应的偏移。这种特性比较适用于目标检测和语义分割等任务。CNNs中卷积操作的参数共享使得它对平移操作具有等变性,而一些池化操作对平移有近似不变性。
设平移函数为 T ( x ) T(x) T(x),表示对 x x x进行平移操作,设使用sobel算子得到边缘图的过程为 f ( x ) f(x) f(x),则平移不变性可表示为: f ( T ( x ) ) = f ( x ) f(T(x))=f(x) f(T(x))=f(x);而平移等变性可表示为 f ( T ( x ) ) = T ( f ( x ) ) f(T(x))=T(f(x)) f(T(x))=T(f(x))。如下图所示,我们将原始1080P的图片 i m g img img缩放到原图的一半大小,并放置在1080P大小的画布上,图片的初始位置为左上角点坐标=(100, 100),下图中, T ( x ) T(x) T(x)为将图片在横纵两个坐标轴上分别移动300个像素,可以对这两个性质有更形象的理解——对平移后的图片进行sobel操作的结果和对平移前的图片做sobel操作的结果相同,即平移不变性;对图片进行平移操作时,sobel操作的结果也会在画布上进行相应的平移,即平移等变性。
通俗一些讲,可以说平移不变性是指,在对平移 T ( x ) T(x) T(x)前后的图片进行某种操作 f ( x ) f(x) f(x)后,对应得到的结果数值相同;平移等变性是指,对进行操作 f ( x ) f(x) f(x)前的图片进行的某种平移 T ( x ) T(x) T(x),同样会对进行操作 f ( x ) f(x) f(x)后的结果产生相同的平移效果。

卷积相关计算
卷积前后特征图尺寸的计算
定义参数如下:
输入特征图尺寸: W × W W\times W W×W
卷积核尺寸: F × F F\times F F×F
步长: S S S
填充的像素数: P P P
那么,输出的特征图尺寸为 N × N N\times N N×N,其中, N = ⌊ W − F + 2 P S + 1 ⌋ N=\lfloor\frac{W-F+2P}{S}+1\rfloor N=⌊SW−F+2P+1⌋
参数量的计算
设前一层的通道数: C i n C_{in} Cin
当前层的卷积核个数(通道数): C o u t C_{out} Cout
单个卷积核的参数量: P a r a m s k e r n a l = C i n × K 2 Params_{kernal}=C_{in}\times K^2 Paramskernal=Cin×K2
总参数量: P a r a m s c o n v = K 2 × C i n × C o u t Params_{conv}=K^2\times C_{in}\times C_{out} Paramsconv=K2×Cin×Cout
卷积核数量的计算
对于普通卷积,卷积核数量为 C i n × C o u t C_{in}\times C_{out} Cin×Cout
全连接层的参数量
在进行全连接层的计算之前需要将最后一层卷积得到的特征图展开为一维的向量,即 $D_{in} = H × W × C $ ,其中
H
,
W
,
C
H,W,C
H,W,C是最后一层卷积输出特征图的高宽和通道数,
D
i
n
D_{in}
Din即为本全连接层的输入特征维度,又设
D
o
u
t
D_{out}
Dout为输出特征维度,则有:
P
a
r
a
m
s
F
C
=
D
i
n
×
D
o
u
t
Params_{FC}=D_{in}\times D_{out}
ParamsFC=Din×Dout
未来展望
本文对原始卷积(普通卷积)的数理背景、计算机视觉中的应用和相关信息计算进行了介绍,接下来会对图像处理基础、卷积的变种等深度学习相关基础知识进行介绍。
参考文献
[1] 一文看尽深度学习中的20种卷积
[2] 连续卷积和离散卷积定义及积分计算
[4] Coursera-Deep-Learning-deeplearning.ai/04-Convolutional Neural Networks
[5] 卷积神经网络——图像卷积















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









