







一、研究背景
1.开放世界半监督学习的目的是利用来自标记数据的信息对未标记样本进行分类,其中未标记样本可以来自于已知类,也可以来自于未见过的新类。
2.目前的方法仅依赖于风险较大的基于相似性的聚类算法,且未对无标签样本进行限制。由于缺乏对新类的监督,不同的新类特征可能会混杂在一起,甚至崩溃到同一个聚类中。(由于过拟合于已知类)
二、研究动机
1.NC现象提供了一个最优的具有最小类内方差和最大的类间方差的特征结构。
2.OW-SSL中,缺少新类标注会破坏NC的导向作用,无标注样本的校准依赖于伪标签,错误的伪标签会误导校准结果。
三、研究目标
利用神经崩溃现象得到最佳特征。
四、技术路线
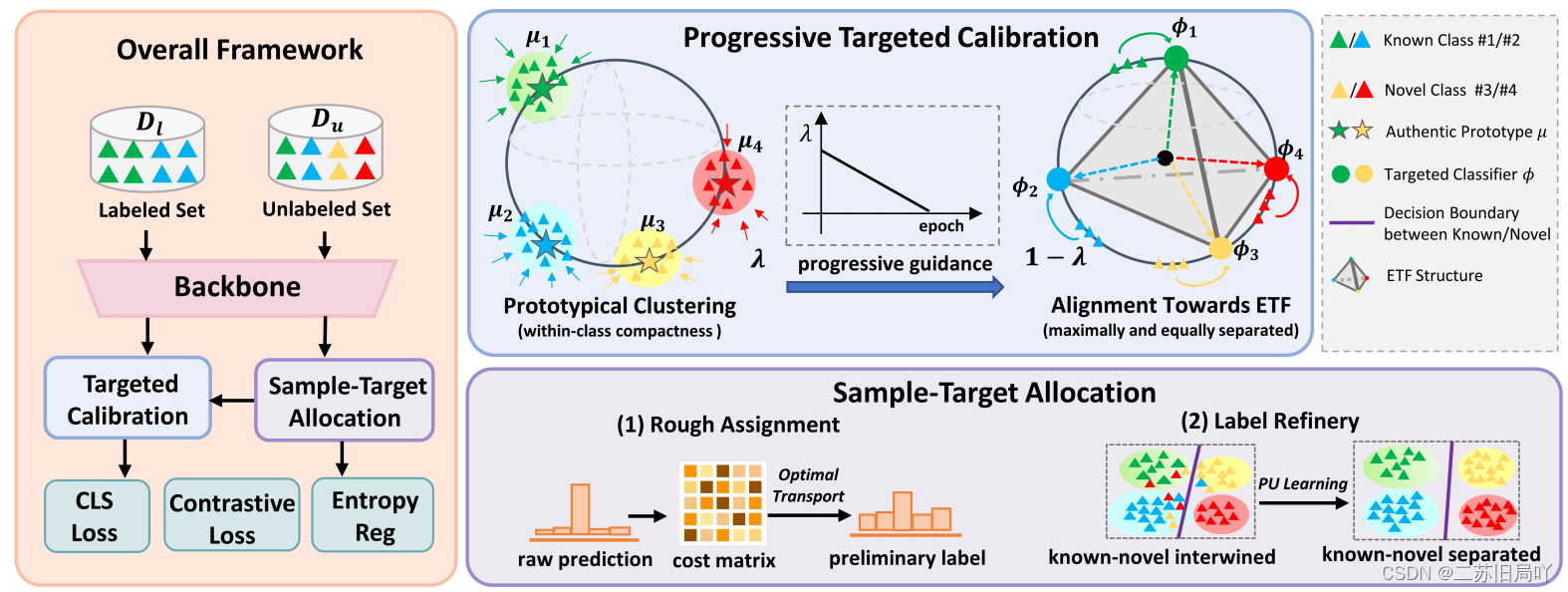
1.Warm-up Phase
- 交叉熵损失
- 自监督对比损失
- 熵损失
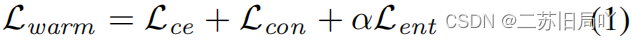
2.Neural Collapse for Representation Calibration
设定具有最大分离度的目标原型,利用目标分类器,逐步将表征对齐至预定义的equiangular tight frame (ETF)原型,以实现嵌入的最优状态。
- Simplex ETF
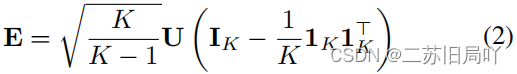
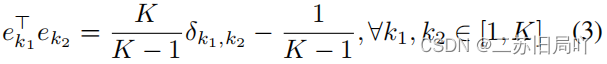
- representation calibration:令目标类原型
ϕ
\phi
ϕ符合ETF结构,拉近特征与相应类原型的距离。
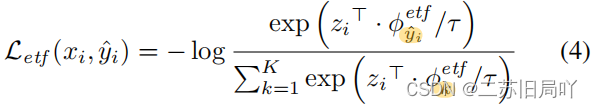
- Progressive Alignment:为保留聚类紧凑性,令无标签样本靠近类中心
μ
\mu
μ。
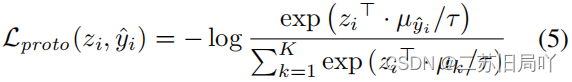
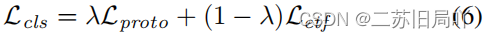
3.Hierarchical Sample-Target Allocation
结合分层的样本-目标分配策略,减轻伪标签噪声引起的错误对齐:
(i) 基于最优传输机制进行粗略样本分配;
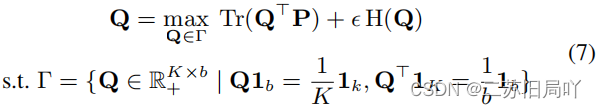
(ii) 将已知-未知分离问题转换为弱监督范式(PU学习),以进行标签改良。
![]()
![]()
![]()
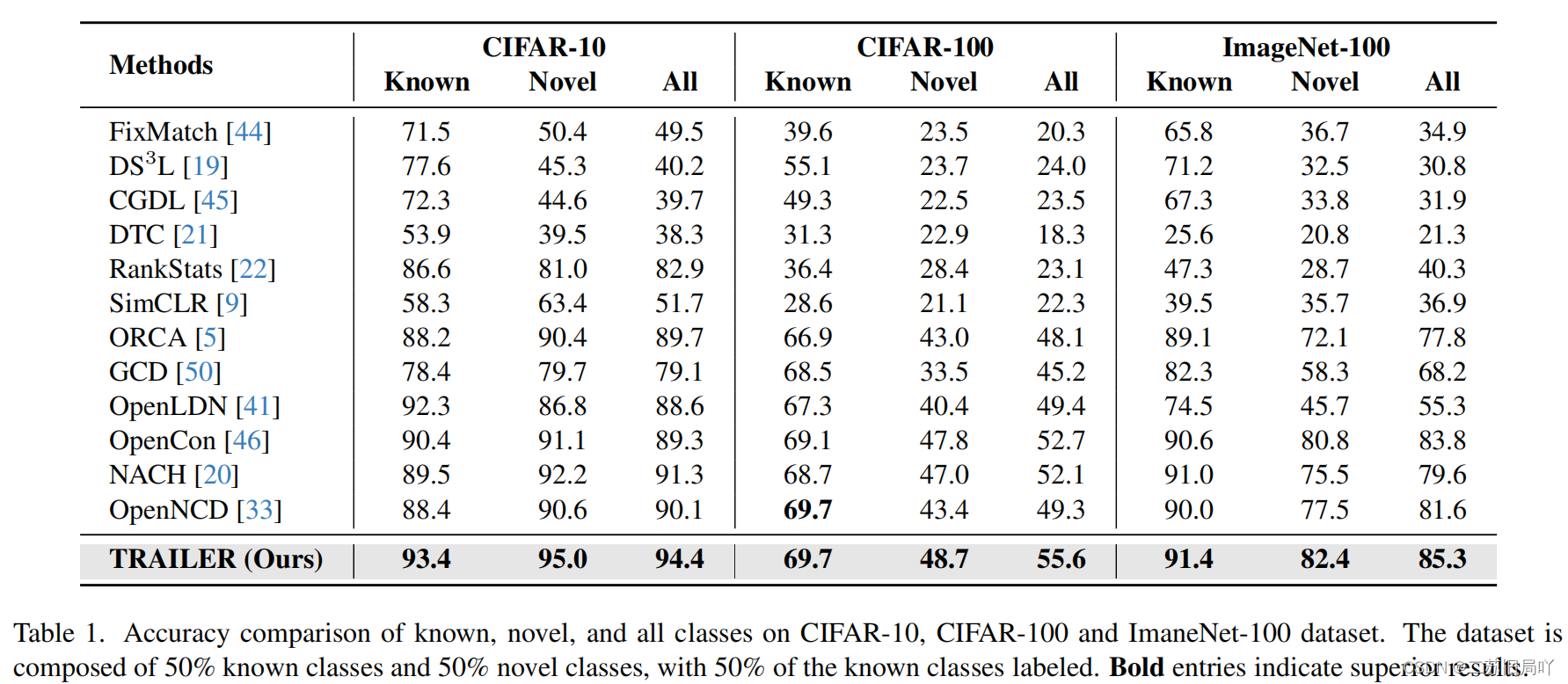
五、实验结果

















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











