







- 作者在知乎的介绍,包含论文及源码链接:[CVPR 2020 Oral] RandLA-Net:大场景三维点云语义分割新框架(已开源)
- 作者在深蓝学院的公开课(包括RandLA-Net和 3D-BoNet):基于三维点云场景的语义分割和实例分割
RandLA-Net最大的亮点在于处理的速度快,准确率也还不错。速度上的提升很大程度是由于point inference部分使用了随机降采样,随机地对点云进行降采样势必会导致有用的信息被丢失,作者设计了局部特征聚合的部分,以此来弥补不均匀采样的问题,同样不再使用max pooling,而是通过加权平均的方法提取全局特征,Dilated Residual Block在扩大感受野上也有很大的优势。
此外,作者提到在设计局部特征聚合部分(LocSE+Attentive Pooling+Dilated Residual Block)时,受到了Relation-Shape CNN以及Dilated Point Convolution(DPC)的启发。Relation-Shape CNN的想法可参考另一篇博文CVPR2019 Relation-Shape CNN,Dilated Point Convolution在本文介绍。
Dilated Point Convolution
Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds 论文链接
- Motivation:对感受野的探索,目前几乎没有在点云上应用深度学习的感受野的研究。
Point Convolution

point convolution 可以用如下公式来表示
(
f
∗
g
)
(
p
i
)
=
∫
−
∞
+
∞
f
(
p
j
)
⊙
g
(
p
i
−
p
j
)
d
p
j
(f*g)(p_i)=\int^{+\infty}_{-\infty}f(p_j)\odot g(p_i-p_j)dp_j
(f∗g)(pi)=∫−∞+∞f(pj)⊙g(pi−pj)dpj
通过蒙特卡洛积分可以近似表示为
(
f
∗
g
)
(
p
i
)
≈
1
N
∑
n
=
1
N
f
(
p
n
)
⊙
g
(
p
i
−
p
n
)
(f*g)(p_i)\approx\frac{1}{N}\sum^N_{n=1}f(p_n)\odot g(p_i-p_n)
(f∗g)(pi)≈N1n=1∑Nf(pn)⊙g(pi−pn)
其中,
g
(
⋅
)
g(·)
g(⋅)为设置有超参数的多层感知机
g
(
p
;
θ
)
=
M
L
P
(
p
;
θ
)
g(p;\theta)=MLP(p;\theta)
g(p;θ)=MLP(p;θ),也有一些工作没有使用多层感知机。
假设卷积处理的范围为中心点
p
i
p_i
pi所在的k近邻邻域
N
i
\mathcal{N}_i
Ni,那么
(
f
∗
g
)
(
p
i
)
≈
1
∣
N
i
∣
∑
p
k
∈
N
i
f
(
p
k
)
⊙
g
(
p
i
−
p
k
)
(f*g)(p_i)\approx\frac{1}{|\mathcal{N}_i|}\sum_{p_k\in\mathcal{N}_i}f(p_k)\odot g(p_i-p_k)
(f∗g)(pi)≈∣Ni∣1pk∈Ni∑f(pk)⊙g(pi−pk)
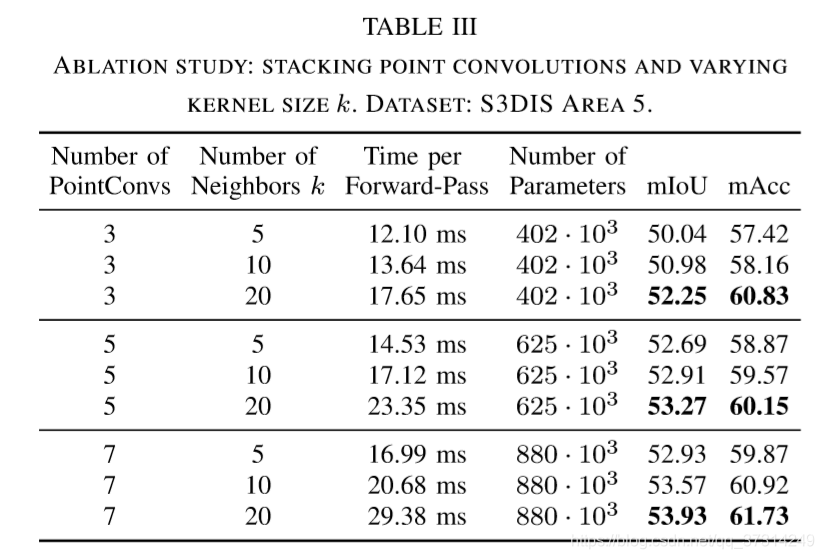
扩大感受野的方法同2D结构差不多,可以通过叠加多层卷积层或者增大卷积核的大小。
Dilated Point Convolutions
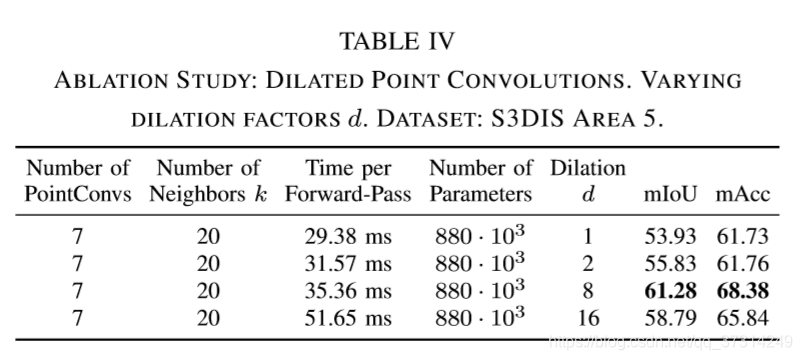
DPC首先计算k·d个近邻,然后每隔d个近邻选择一个点,见图Fig 2(右)。对于d=1,DPC与PCs相同。
参数设置的不同导致接收野大小显著增加(见图4)。但是,参数的数量保持不变。需要计算的邻居数目k·d越大,计算开销就越大。

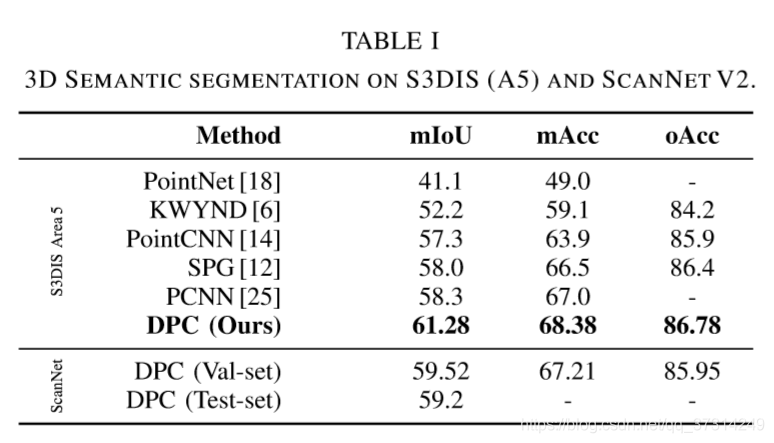
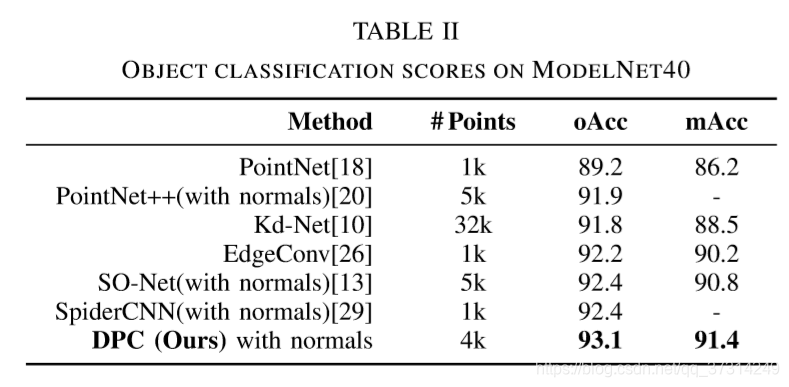
一些实验结果:














 3237
3237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









