








问题:为什么同样的模型,例如GRU,用联邦学习框架实现,效果比集中式的要差很多?
问题概述
在联邦学习方法和集中式学习方法的训练过程,我发现联邦学习效果比集中式学习方法效果更差,针对此现象,本文做如下分析。
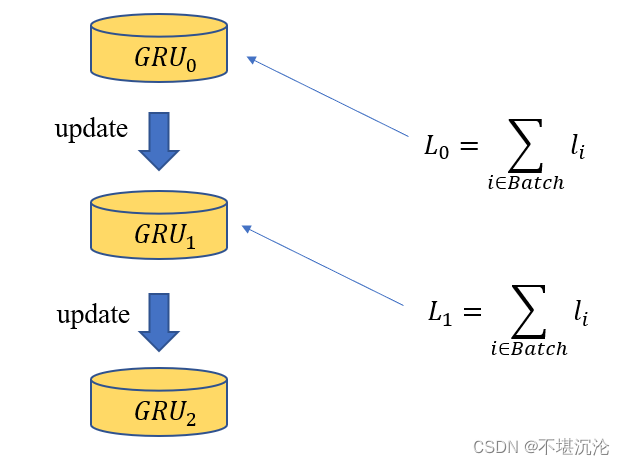
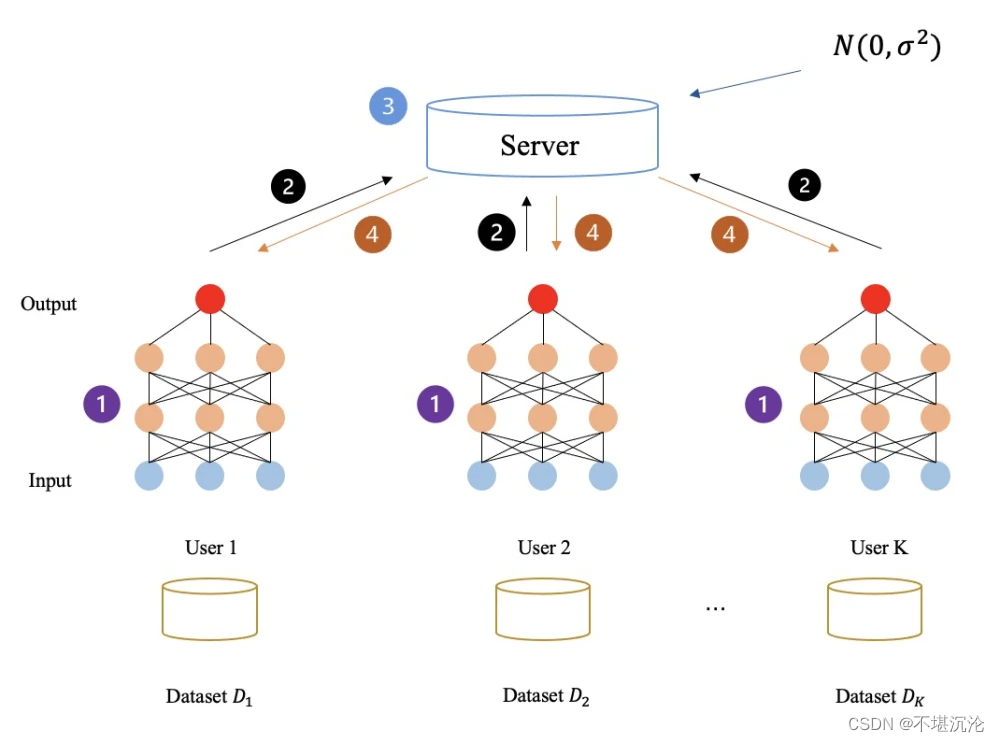
1. 模型更新方式的层面
集中式的学习,不同batch之间的训练是串行的,是在一个batch已训练好,模型有一定程度更新的基础上,再用新的batch进行训练;而联邦学习,不同clients的训练样本(每个client样本的大小一般应该比batch大)是并行训练的,这固然加快了训练的速度,但由于每个client都是在相对没有训练好的模型上进行训练,而不同clients由于数据分布的差异,对模型参数的更新可能有相互抵消的效,因此训练的收敛会慢一些,也有可能训练的效果要差一些(这个不太确定);
2. 训练样本层面
集中式学习,在两个不同训练批次,batch之间的数据样本可以交换,因此一个样本往往有机会跟很多其它不同的样本放在一个批次中训练,这会让模型学会不依赖于具体样本是否在同一个批次出现,更好地学出所有数据样本的共性;对于联邦学习而言,由于数据被固定在每个client,不允许交换,所以在批次学习中样本的多样性会受到影响,尽管不同clients的样本可以通过client局部模型的参数有所体现,但这可能对模型学习的效果带来影响。
总结
可以从样本的共性和样本的局部性角度来理解联邦学习:对每个client而言,其试图学出局部样本的特性,而server端则试图通过FedAvg算法学出所有样本的共性,并把这一共性传递给clients,以便让clients按照server学出的共性来更新其参数,然而每个client在依据server的共性来更新其模型参数后,由于其本地样本的局部性,仍然会按局部数据样本的数据分布的指引更新其参数。因此联邦学习可以理解为server和clients之间进行多方拔河比赛,server端希望学出所有样本的共性,而每个client端希望学出其局部样本的个性。

















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









