







 本文介绍了图像检索的两种主要技术:基于文本的和基于内容的图像检索。重点讲解了基于BOW(Bag of Words)的图像检索原理,包括BOW模型的概念,以及如何利用SIFT特征和K-means聚类算法构建BoF(Bag of Features)来表示图像。此外,还提到了BoF在计算机视觉中的应用和图像检索的代码实现过程。
本文介绍了图像检索的两种主要技术:基于文本的和基于内容的图像检索。重点讲解了基于BOW(Bag of Words)的图像检索原理,包括BOW模型的概念,以及如何利用SIFT特征和K-means聚类算法构建BoF(Bag of Features)来表示图像。此外,还提到了BoF在计算机视觉中的应用和图像检索的代码实现过程。
目录
一、图像检索概述
图像检索,简单的说,便是从图片检索数据库中检索出满足条件的图片,图像检索技术的研究根据描述图像内容方式的不同可以分为两类:
一类是基于文本的图像检索技术,简称TBIR,
一类为基于内容的图像检索技术,简称CBIR。
1.1 基于文本的图像检索(TBIR)
从20世纪70年代开始,有关图像检索的研究就已经开始,当时主要是基于文本的图像检索技术,利用文本描述的方式描述图像的特点,如一张照片,配以文字说明照片拍摄的时间,地点,事件的主要内容等。
但这种方法需要较多的人工参与,而且随着图像数目的增加,这种方法很难实现;由于图像所包含的信息量庞大,不同的人对于同一张图像的理解也不相同,这就导致对图像的标注没有一个统一的标准,因而检索的结果不能很好的符合用户的需求。
1.2 基于内容的图像检索技术(CBIR)
到90年代以后,出现了对图像的内容语义,如对图像颜色、纹理、布局等进行分析和检索的图像检索技术,即基于内容的图像检索。指的是查询条件本身就是一个图像,或者是对于图像内容的描述,它建立索引的方式是通过提取底层特征,然后通过计算比较这些特征和查询条件之间的距离,来决定两个图片的相似程度。
二、基于bow的图像检索原理
2.1 BOW (Bag of words)
BoW模型最初是为解决文档建模问题而提出的,因为文本本身就是由单词组成的。它忽略文本的词序,语法,句法,仅仅将文本当作一个个词的集合,并且假设每个词彼此都是独立的。这样就可以使用文本中词出现的频率来对文档进行描述,将一个文档表示成一个一维的向量。
BoW引入到计算机视觉中,就是将一幅图像看着文本对象,图像中的不同特征可以看着构成图像的不同词汇。和文本的BoW类似,这样就可以使用图像特征在图像中出现的频率,使用一个一维的向量来描述图像。
要将图像表示为BoW的向量,首先就是要得到图像的“词汇”。通常需要在整个图像库中提取图像的局部特征(例如,sift,orb等),然后使用聚类的方法,合并相近的特征,聚类的中心可以看着一个个的视觉词汇(visual word),视觉词汇的集合构成视觉词典(visual vocabulary) 。 得到视觉词汇集合后,统计图像中各个视觉词汇出现的频率,就得到了图像的BoW表示。


2.2 BOF(Bag of features)
2.2.1 BOF概述
BOF方法源自于文本处理的词袋模型。Bag-of-words model (BoW model) 最早出现在NLP和IR领域. 该模型忽略掉文本的语法和语序, 用一组无序的单词(words)来表达一段文字或一个文档. 近年来, BoW模型被广泛应用于计算机视觉中. 与应用于文本的BoW类比, 图像的特征(feature)被当作单词(Word)。
BoF(Bag Of Feature)借鉴文本处理的词袋(BoW,Bag Of Bag)算法,将图像表示成视觉关键词的统计直方图。就像上面对文本的处理一样,提取文本中出现单词组成词汇表,这里关键是得到图像库的“词汇表”。为了得到图像库的“词汇表",通常对提取到的图像特征进行聚类,得到一定个数的簇。这些聚类得到的簇,就是图像的”词汇“,可以称为视觉词(Visual Word)。聚类形成的簇,可以使用聚类中心来描述,所以,视觉词指的是图像的局部区域特征(如纹理,特征点)经过聚类形成的聚类中心。
2.2.2 基于SIFT特征构建BoF的步骤
这边sift算法原理省略SIFT原理
1、SIFT特征提取 :提取训练集中所有图像的SIFT特征,设有MM幅图像,共得到NN个SIFT特征。
2、构建视觉词汇表 对提取到的NN个SIFT特征进行聚类,得到KK个聚类中心,组成图像的视觉词汇表。
3、图像的视觉词向量表示,统计每幅图像中视觉词汇的出现的次数,得到图像的特征向量。在检索时,该特征向量就代表该幅图像。统计时,计算图像中提取到的SIFT特征点到各个视觉词(聚类中心)的距离,将其归类到聚类最近的视觉词中。
2.3 K-means聚类算法
聚类(Clustering)是一种无监督学习算法,其目的是将数据集中的样本划分为若干个不相交的子集,每个子集称为一个簇(Cluster)。聚类的时候并不关心某一类是什么,只根据数据的相似性,将数据划分到不同的组中。每个组内的成员具有相似的性质。
聚类算法可以分为三类:
- 原型聚类,此类算法假设聚类结构能够通过一组原型描述,这里原型指的是样本空间中具有代表性的点。
- 密度距离,该类算法假设聚类结构能够通过样本分布的紧密程度来确定。
- 层次聚类,在不同的层次对数据集进行划分,从而形成树形的聚结构。
K-Means算法是原型聚类的一种,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分为(C1,C2,...Ck),则我们的目标是最小化平方误差E: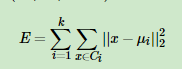
其中μi是簇Ci的均值向量,有时也称为质心,表达式为: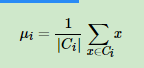
K-Me
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3015
3015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









