







 本文介绍了DropConnect,一种针对神经网络全连接层的正则化技术,它是Dropout的扩展,通过在权重而非激活上随机删除连接来减少过拟合。在训练时,DropConnect为每个样本实例化不同的连接,提升了模型的泛化性能。实验结果显示,DropConnect在多项图像识别任务上表现出优于Dropout的性能,并且通过结合多个DropConnect训练的模型,能在多个基准测试中达到最先进的结果。
本文介绍了DropConnect,一种针对神经网络全连接层的正则化技术,它是Dropout的扩展,通过在权重而非激活上随机删除连接来减少过拟合。在训练时,DropConnect为每个样本实例化不同的连接,提升了模型的泛化性能。实验结果显示,DropConnect在多项图像识别任务上表现出优于Dropout的性能,并且通过结合多个DropConnect训练的模型,能在多个基准测试中达到最先进的结果。
论文:Regularization of Neural Networks using DropConnect . Li Wan,Matthew Zeiler,Sixin Zhang,Yann LeCun,Rob Fergus
摘要
我们引入了DropConnect,这是Dropout的一个推广,用于正则化神经网络中的大型全连接层。当使用Dropout进行训练时,在每一层中将随机选取的激活子集设为零。DropConnect将网络中随机选择的权重子集设置为零。因此,每个单元接收来自前一层单元的随机子集的输入。我们得到了Dropout和DropConnect的泛化性能的一个界。然后,我们在一系列数据集上评估DropConnect,与Dropout进行比较,并通过聚合多个DropConnect训练过的模型,在几个图像识别基准上显示最先进的结果。
引言
神经网络(NN)模型非常适合于有大型标准的数据集可用的领域,因为它们的容量可以通过在每一层中添加更多层或更多单元来轻松增加。然而,拥有数百万或数十亿参数的大型网络,即使是最大的数据集,也很容易过度拟合。相应地,各种各样的神经网络正则化技术也得到了发展。在网络权值上增加一个l2的罚值是一种简单而有效的方法。其他正则化形式包括: 贝叶斯方法、权重消除、提前停止训练。在实践中,在训练大型网络时使用这些技术可以为未经正则化训练的小型网络提供更好的测试性能。
最近,Hinton等人提出了一种新的正则化形式Dropout。对于每个训练示例,正向传播包括随机删除每一层中一半的激活。然后,误差只通过其余的激活反向传播。大量的实验表明,这大大减少了过拟合,提高了测试性能。尽管对其机制的充分理解是难以理解的,但直觉上它阻止了网络权值相互协作来记忆训练样本。
在本文中,我们提出了DropConnect,它通过随机丢弃权重而不是激活来推广了Dropout。和Dropout一样,该技术只适用于全连接层。在四种不同的图像数据集上对两种方法进行了比较。
Motivation
考虑一个输入v = [v1, v2,…,vn]T的神经网络的全连接层,和权重参数W(大小为d×n)。该层的输出r=[r1,r2,...,rd]T是计算为输入向量与权值矩阵的矩阵相乘,然后是非线性激活函数a(为简便起见,W中包含偏差biases,对应的固定输入为1):
r = a(u) = a(Wv) (1)
Dropout
Dropout是 (Hinton et al., 2012)提出的一种全连接神经网络层的正则化形式。层输出的每个元素都以概率p保持,否则以概率(1-p)设置为0。大量的实验表明,Dropout算法提高了网络的泛化能力,提高了测试性能。将Dropout应用于一个全连接层的输出时,将Eqn. 1写成:
r = m*a(Wv) (2)
其中*表示逐元素相乘,m是每个元素大小为d的二元掩码向量(binary mask vector),mj~Bernoulli(p)。许多常用的激活函数,如tanh、certered sigmoid和relu,都具有a(0) = 0的性质。因此,Eqn. 2可以重写为,r = a(m * Wv),其中Dropout应用于激活函数的输入。
DropConnect
DropConnect是Dropout的推广,每个连接都可以以1-p的概率被删除,而不是每个输出单元。DropConnect与Dropout相似,因为它在模型中引入了动态稀疏性,但不同之处在于稀疏性是在权值W上,而不是某一层的输出向量上。换句话说,全连接的DropConnect层变成了稀疏连接层,在训练阶段随机选择连接。注意,这并不等同于训练时将W设为固定的稀疏矩阵。
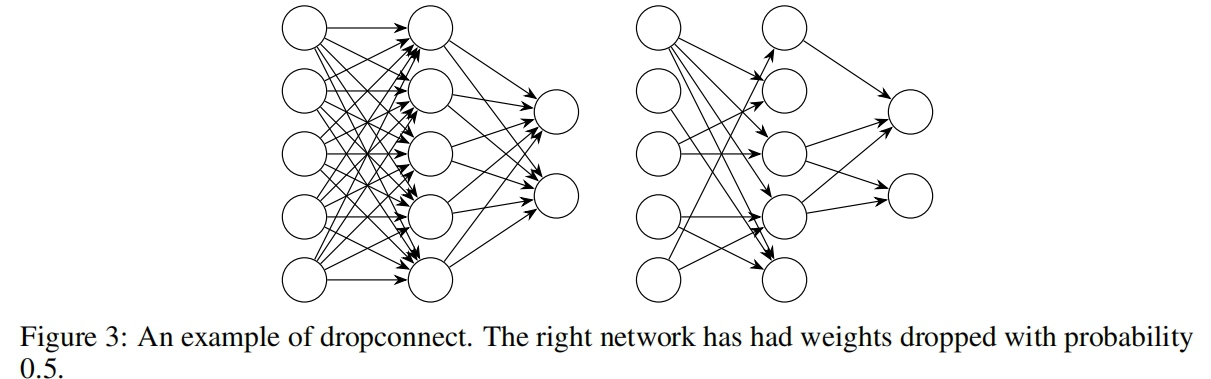
对于DropConnect层,输出如下:
r = a((M*W)v) (3)
其中M是编码了连接信息的二元矩阵,且Mij~Bernoulli(p)。在训练过程中,掩码矩阵 M 的每个元素都是为每个样本独立采样的,本质上是为每个看到的样本实例化不同的连接。在训练过程中,这些Bias也被掩盖了。从等式2和等式 3可以明显看出,DropConnect是Dropout对一层全连接结构的推广。
方法
考虑一个由四个基本组件组成的标准模型架构(见图1a):
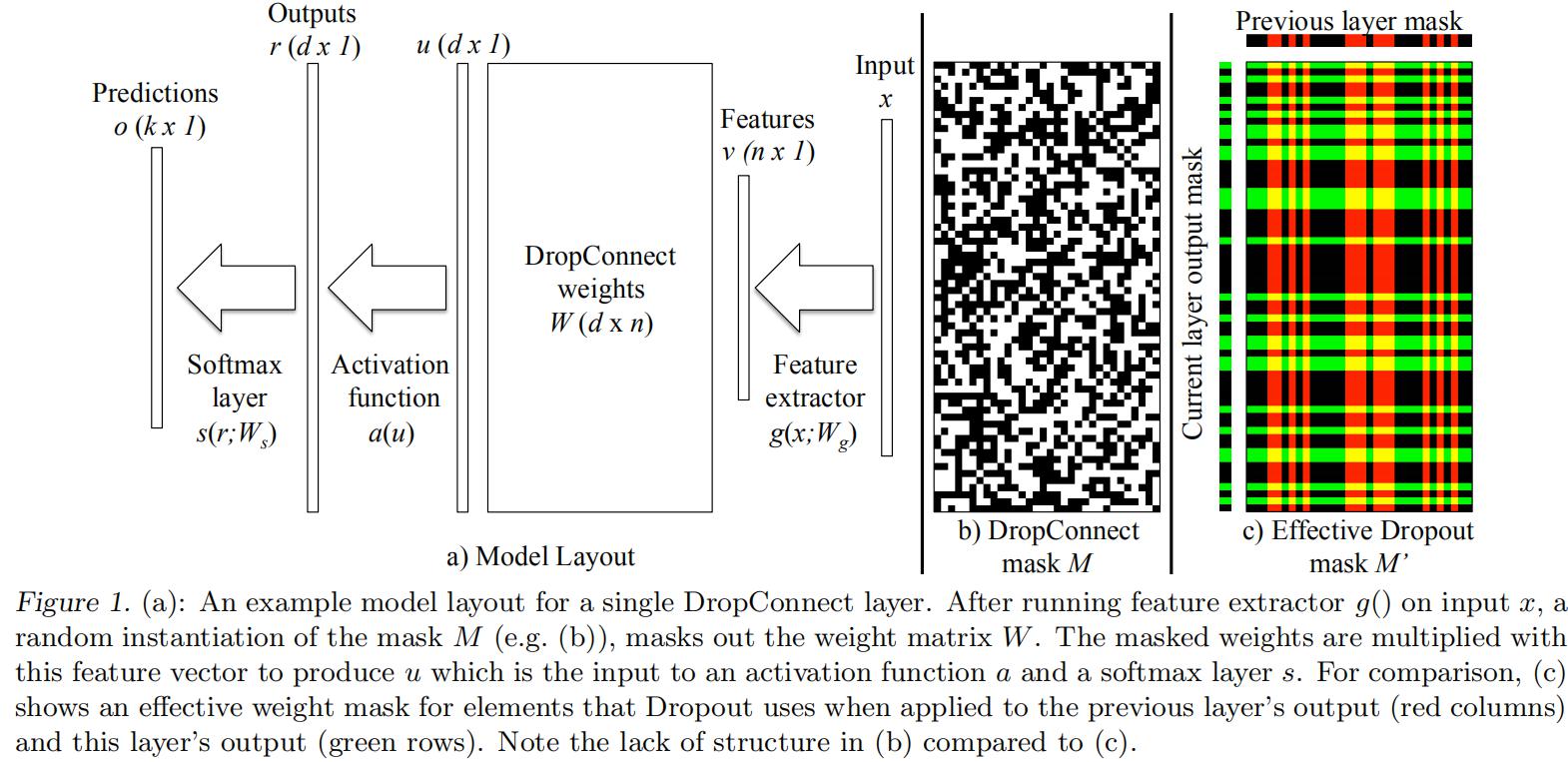
特征抽取器:v=g(x;Wg),其中v是输出特征图,x是整个模型的输入数据,Wg是特征抽取器的参数,g()是CNN。
DropConnect层:r=a(u)=a((M*W)v),其中v是特征抽取器的输出,W是全连接层权重矩阵,a是非线性激活函数,M是二元掩码矩阵。
Softmax分类层:o=s(r;Ws),然后参数Ws将r映射到k维输出。
分类交叉熵损失:A(y,o)= -Σi=1k yilog(oi),输入是概率o和ground truth标签y。
因此整个模型f(x;θ,M),通过一系列给定参数θ={Wg,W,Ws}的运算和随机采样的掩码矩阵M,将输入x映射到输出o。对所有可能的掩码矩阵M求和得到o的正确值:
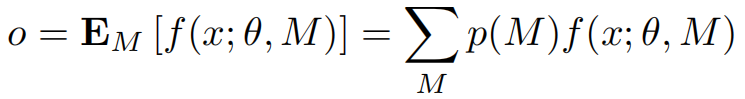
这揭示了DropConnect(和Dropout)的混合模型解释,其中输出是2^|M|不同网络的混合,每个网络都有权值p(M)。如果p=0.5,则这些权重相等,且输出
o=
![]()
训练
训练第3节中描述的模型,首先从训练集中选择一个样本x,并为这个样本v提取特征。这些特征被输入到DropConnect层,首先从Bernoulli(p)分布中采样掩模矩阵M,以掩模掉DropConnect层中权重矩阵和偏置值。成功使用DropConnect训练的关键组件是为每个训练样本选择不同的掩码。为训练样本的子集(例如128个样本的小批量)选择单个掩码,在实践中并没有足够的正则化模型。由于M的内存需求现在随着每个mini-batch处理的大小而增长,因此需要按照第5节的描述仔细设计实现。
一旦掩码被选择,它就被应用到权重和偏差上,以便计算激活函数的输入。这将得到输入到softmax层的输入r,该层输出类预测,从类预测中计算出Ground truth值标签之间的交叉熵。然后,通过损失函数相对于参数A’θ的梯度反向传播,通过随机梯度下降(SGD)来更新整个模型的参数。为了更新DropConnect层的权值矩阵W,将掩码应用到梯度上,只更新那些在前向通道中激活的元素。此外,当将梯度传递到特征提取器时,使用了掩码权值矩阵M *W。如算法1所示。

推断
推断时,需要计算r=1/|M|∑M a((M*W)v),则需要计算2^|M|个不同的掩码矩阵,明显不可能。Dropout做了一个近似:∑M a((M*W)v)≈a(∑M(M*W)v),采取不同的方法。在激活函数a()之前考虑单个激活单元ui:ui=∑j(Wijvi)Mij。这是伯努利变量Mij的加权和,可以通过矩匹配用高斯函数来近似。单元u的均值和方差是:EM[u]=pWv和VM[u]=p(1-p)(W*W)(v*v)。然后,从这个高斯分布中采样,并将它们通过激活函数a()传递,然后再将它们平均并呈现给下一层。算法2总结了这个过程:

注意,由于每个单元和示例的样本可以并行采样,因此可以有效地进行。该方案仅是多层网络情况下的一种近似方法,实验结果表明该方案在实际应用中具有良好的效果。


















 7506
7506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









