






写在前面
感兴趣的话可以了解一下magicleap这家AR公司,也就是几位作者所在单位,很是有意思
摘要
1.文章定义解决的问题是多视角几何问题-multiple-view geometry problems
2.方法被概括为:一种用于训练感兴趣点和描述子检测器的半监督框架
3.摘要中重点强调了两点:(1)在全尺度图像上操作,并在一次前向传播中联合计算感兴趣点和描述子。(2)引入Homographic Adaptation,并生成其具有multi-scale和multi-homographic的特点,可以提高感兴趣点检测的可重复性和跨域(比如合成数据到真实数据)的适配
4.与LIFT、SIFT和ORB在HPatches相比,取得SOTA
Introduction
介绍,在一些任务重关键点提取的重要性
CNN对计算机视觉任务的推动作用
介绍,与人体关键点不同,场景中的感兴趣点检测更困难
重点突出,本文的框架是无监督的,连带着当然会提到伪标签和无标注
提到创建了一个合成数据集Synthetic Shape,由简单的几何形状组成,因此关键点位置无歧义
贡献说明:提出合成数据集,并在合成数据集上训练了一个称为MagicPoint的基础检测器,MagicPoint在合成数据集中表现很好,但因为域适应问题的存在,在真实数据集中表现较差,因此引出另一个创新点:Homographic Adaptation
Homographic Adaptation对兴趣点检测器进行自监督训练。基本原理为:多次扭曲输入图像,以帮助兴趣点检测器从许多不同的视点和比例看到场景。将Homographic Adaptation与MagicPoint检测器结合使用,以提高检测器的性能并生成真值兴趣点的伪标签。由此产生的检测更具可重复性。将结果检测器命名为SuperPoint
SuperPoint架构
该方法的整体印象可参照文中图2的overview
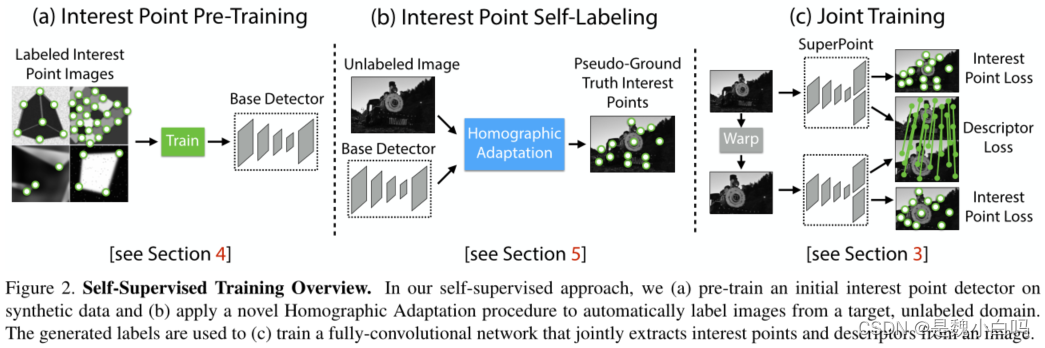
接下来详细介绍SuperPoint的架构: SuperPoint在全尺寸对图像进行操作,并在一次前向传递中产生带有固定长度描述符的兴趣点检测,如图3。 SuperPoint模型有一个单一的且共享的编码器来处理和降低输入图像的维度。在编码器之后,该体系结构被分成两个独立的解码部分,它们学习特定于任务的权重:一个被用于兴趣点检测,另一个用于兴趣点的描述。网络的大部分参数是在两个任务之间共享的,这与传统的系统不同,传统的系统首先检测兴趣点,然后计算描述符,缺乏在两个任务之间共享计算和表示的能力。

共享的编码器
VGG-like
InterestPoint Decoder
常用的方法是生成一层对应的mask,mask上的元素代表对应关键点的概率。文章提到在这其中的上采样过程会产生checkerboard artifacts,因此设计了detection head with an explicit decoder。顺序使用Softmax和Reshape操作。
Descriptor Decoder
同InterestPoint Decoder的过程类似,顺序使用 bicubic interpolation和L2-normalizes
损失函数
由独立的关键点损失和描述子损失组合成最终的损失函数
使用的数据来自两部分:感兴趣点位置的伪标签和与两个图像相关的随机生成的单应性H的标签
损失函数细节介绍可见原文,之后的叙述也会提到
Synthetic Pre-Training
所谓Synthetic Pre-Training就是基础检测器-MagicPoint的训练过程
目前还没有标记为图像的大型兴趣点数据库。为了能训练深度兴趣点检测器,首先创建一个称为Synthetic Shapes 的大规模合成数据集,该数据集由简化的2D几何组成,通过四边形、三角形、直线和椭圆的合成数据渲染。这些形状的例子如图4所示。在这个数据集中够通过使用简单的Y形连接、L形连接、T形连接以及微小椭圆的中心和线段的端点来建模兴趣点,从而消除标签的歧义。

紧接着是说训练处的检测器在真实数据集中表现也很好,只是不够好。这里有一点需要注意,虽然合成数据和真实数据存在域迁移的问题,但合成数据集中训练的检测器在真实环境中也并不是完全不work的,只是效果差了点。
Homographic Adaptation
算是文章最重要的创新点

在MS-COCO数据集中训练,重点强调无标签的自监督训练过程
解释单应(Homographies)
单应(Homographies)表示仅围绕相机中心旋转的图像到图像的相机运动
但因为世界上大多数地方都是相当平坦的,所以当从不同的视角看到同一个3D点时,单应是一个很好的模型。因为单应不需要3D信息,所以它们可以随机采样并轻松地应用于任何2D图像-只涉及双线性内插。出于这些原因,homographies成为了本文自监督方法的核心
听起来像是一个数据增强的过程,举例如下

训练效果

评估
训练是在COCO数据集中
评估是在HPatches数据集中















 6915
6915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











