






 本文介绍了一种使用PyTorch进行股票价格预测的方法,结合CNN、LSTM和不同类型的Attention机制。通过历史股票数据的open, low, close, high预测未来股票变化趋势。实验结果显示,加入SE注意力机制的模型表现较好,但存在过拟合问题。后续优化计划包括引入Transformer和应用滑动平均过滤噪声。"
122251822,350945,智慧水利三维可视化:决策支持与应急响应,"['人工智能', '大数据', '物联网', '数字孪生', '智慧水利']
本文介绍了一种使用PyTorch进行股票价格预测的方法,结合CNN、LSTM和不同类型的Attention机制。通过历史股票数据的open, low, close, high预测未来股票变化趋势。实验结果显示,加入SE注意力机制的模型表现较好,但存在过拟合问题。后续优化计划包括引入Transformer和应用滑动平均过滤噪声。"
122251822,350945,智慧水利三维可视化:决策支持与应急响应,"['人工智能', '大数据', '物联网', '数字孪生', '智慧水利']
前言
本文使用pytorch实现,根据历史股票的open,low,close,high数据预测未来股票的变化趋势。
代码在文末
用xgboost也跑了一下:机器学习实战——股票close预测
拟合结果
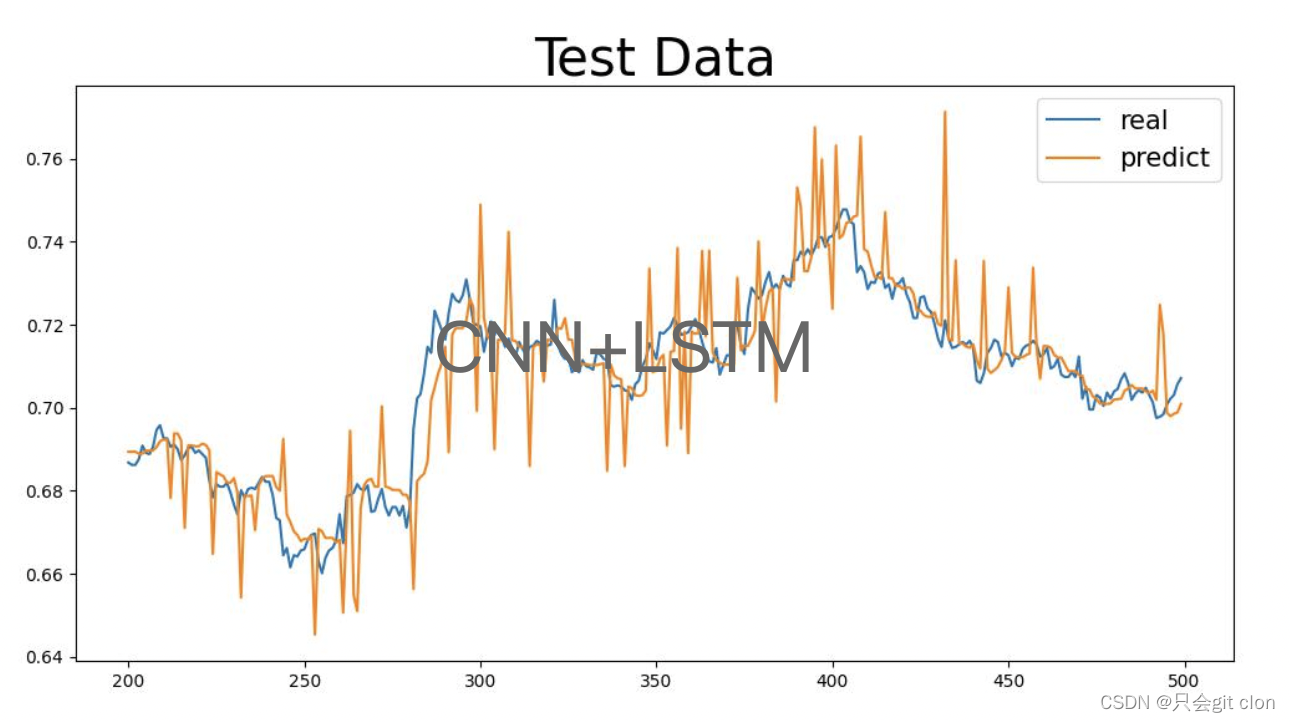
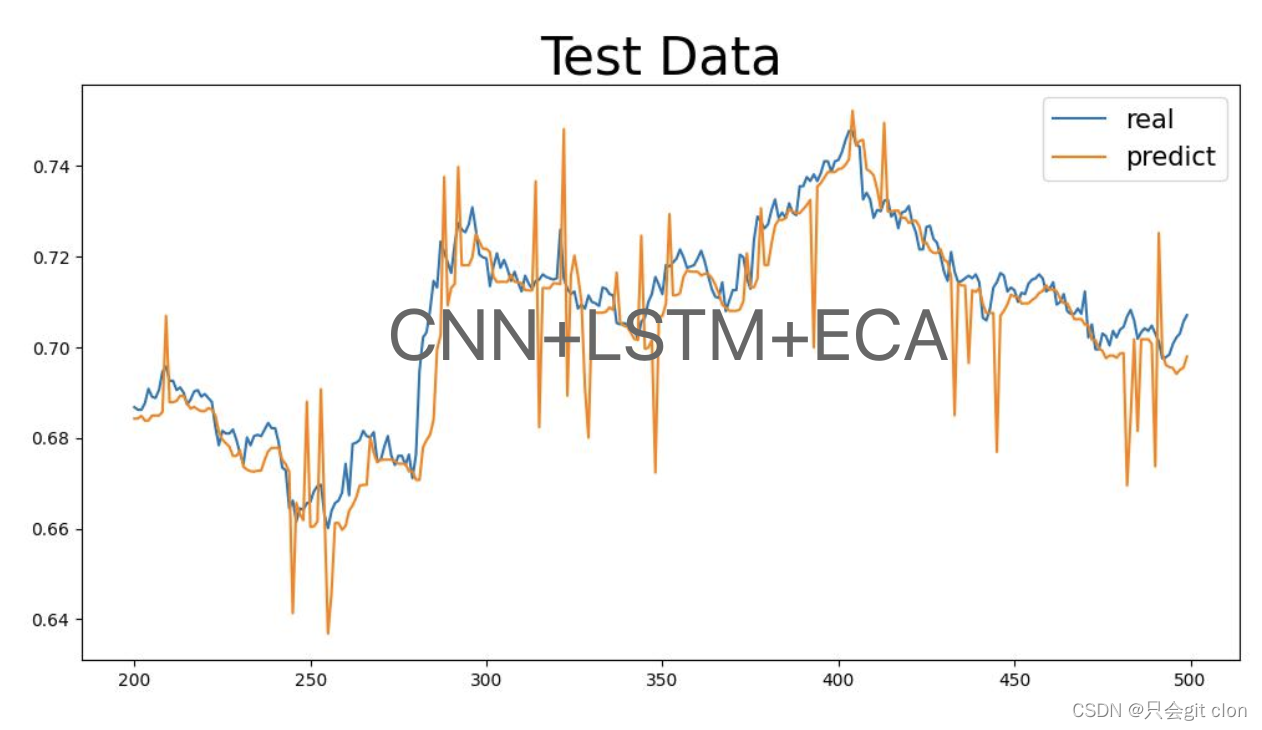
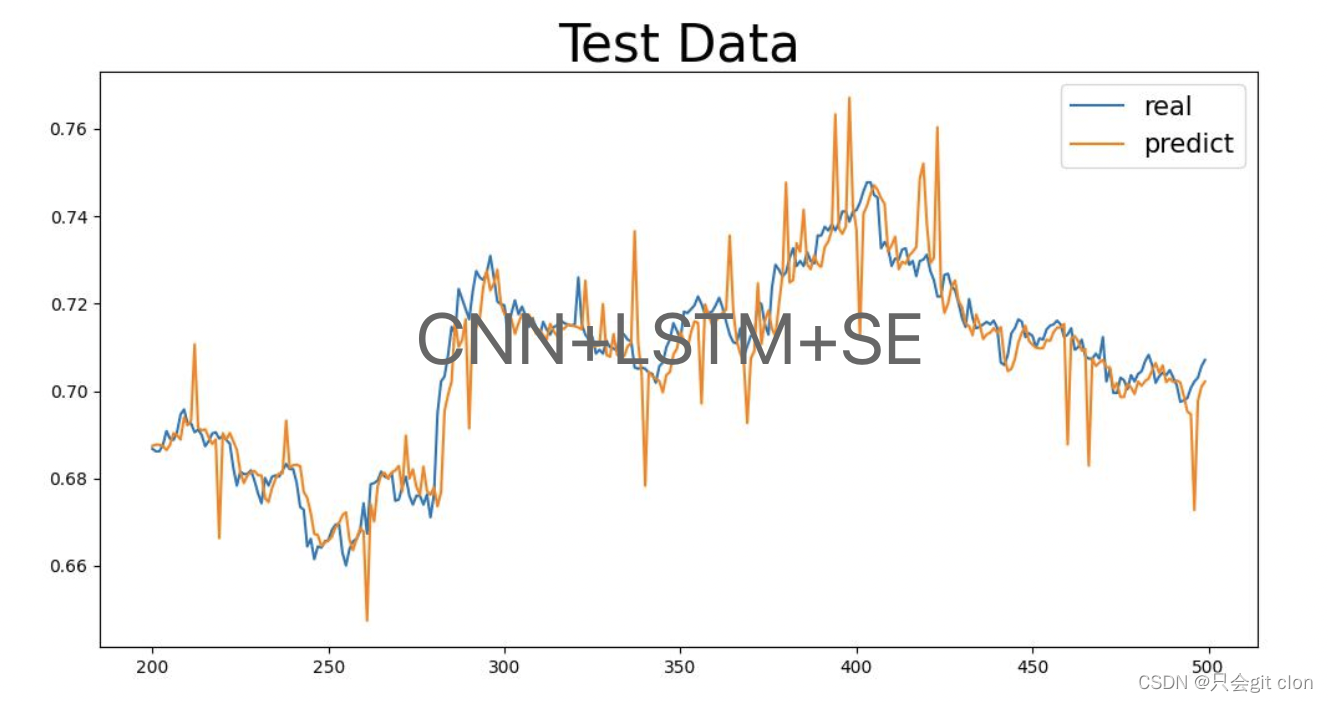
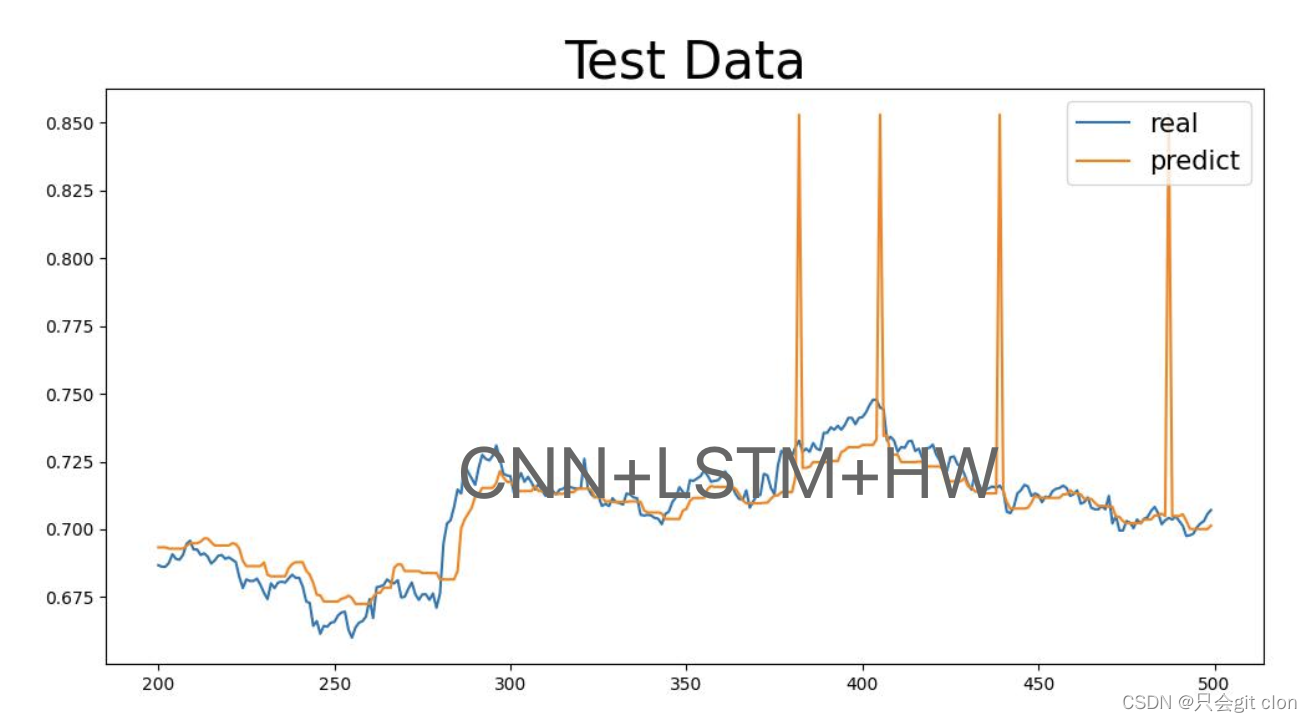

本文使用pytorch实现,根据历史股票的open,low,close,high数据预测未来股票的变化趋势。
代码在文末
用xgboost也跑了一下:机器学习实战——股票close预测
 3769
3769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























