







摘要
在知识蒸馏(KD)领域中,温度在调节标签柔软度方面起着关键作用。传统方法通常在整个KD过程中采用静态温度,这无法解决具有不同难度水平的样本的细微复杂度,并且忽略了不同师生配对的独特能力。这导致了不太理想的知识转移。为了改进知识传播过程,我们提出了动态温度知识蒸馏(DTKD)方法,该方法在每个训练迭代中同时对教师和学生模型引入动态、协作的温度控制。特别是,我们提出了“锐度”作为量化模型输出分布的平滑度的度量。通过最小化教师和学生之间的锐度差异,我们可以分别得出他们的样本特定温度。
介绍
通常,教师的输出过于尖锐(自信),使得学生很难学习到错误类之间的细微差异。因此,经常使用由“温度”调节的soft标签来改善KD性能。在实践中,知识蒸馏的损失函数通常由两部分组成:硬标签的交叉熵损失和软标签的KL散度损失。温度对软标签的光滑度影响很大。较大的温度使软标签更光滑,较小的温度使软标签更锐利。一些研究发现,固定的温度可能会阻碍KD过程,因此致力于探索KD过程中温度的动态调节。例如,退火KD认为调节温度可以弥合师生网络之间的容量差距,并提出通过模拟退火来控制温度。CTKD表明,在学生学习生涯中,任务难度水平可以通过一个动态的、可学习的温度来控制。这些方法忽略了学生和教师网络输出分布之间平滑度的差异,而且它们都对教师和学生应用相同的温度。此外,上述方法需要添加新的模块或增加训练成本,这大大降低了它们使用的灵活性。因此,在最近开发的KD算法中,经验固定温度仍然存在(例如DKD,NormKD)源于与我们类似的观点,采用输出logit的归一化来建立整个分布的一致程度的平衡。然而,他们的方法并没有考虑到教师和学生模型之间合作的动力,导致学生的自信水平明显较低,这使得它们在实际部署中不太实用。
与之前的大多数工作不同,我们的工作基于以下观察:如果教师和学生共享一个固定温度,他们的logits(网络输出)的平滑度通常存在差异,这可能会阻碍KD过程。当学生的能力受到限制时,这种现象变得更加明显,如图1所示。
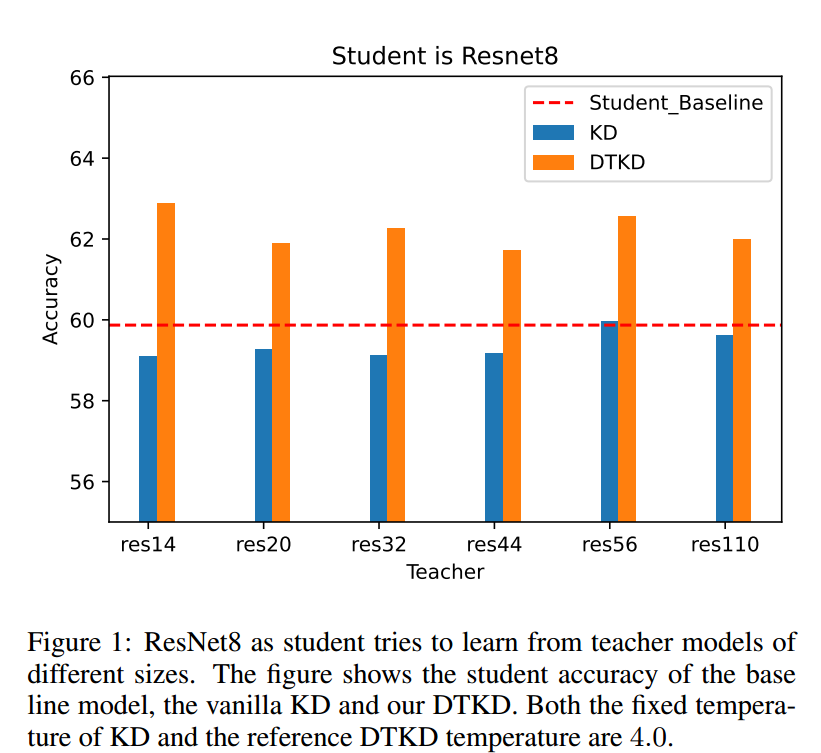
ResNet8学生与不同大小的教师配对,4.0温度下vanillaKD的效果通常比基线差。为了解决这种不匹配的平滑性,本文引入了动态温度知识蒸馏(DTKD)。特别是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3071
3071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









