






文章目录
0. 前言
整个初始化部分的pipeline如下所示:
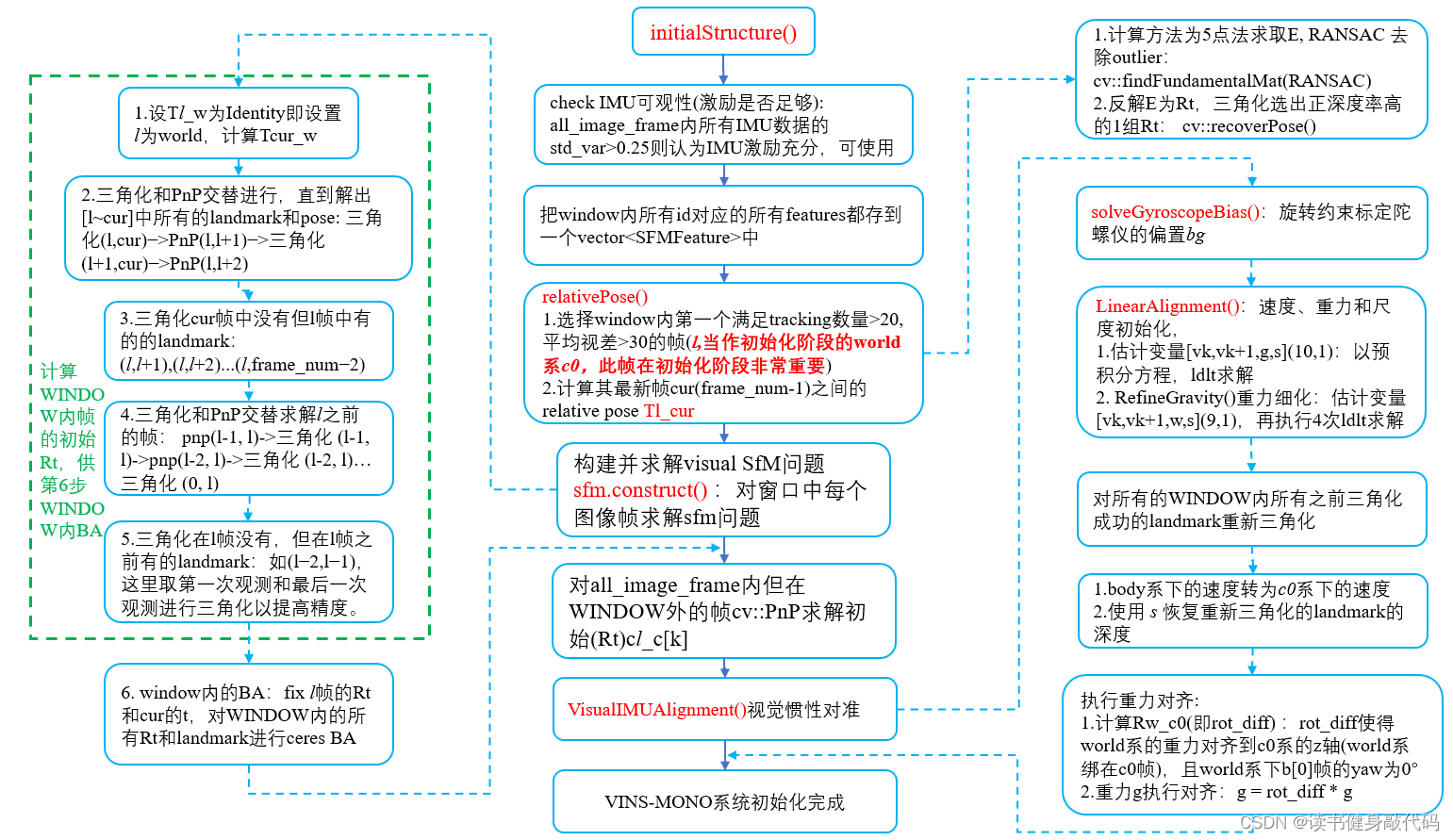
之前的课程中讲解过理论部分,接下来根据代码一步步讲解。

1. 旋转约束标定旋转外参Rbc
上回讲了processImage中addFeatureCheckParallax完成了对KF的筛选,我们知道了2nd是否为KF,接下来是初始化和后端求解部分。对于初始化,如果需要标定外参Tic,则先标定Ric外参,使用两帧img和对应imu的数据进行标定。
//不知道关于外参的任何info,需要标定
if(ESTIMATE_EXTRINSIC == 2)
{
ROS_INFO("calibrating extrinsic param, rotation movement is needed");
if (frame_count != 0)
{
// 找相邻两帧(bk, bk+1)之间的tracking上的点,构建一个pair,所有pair是一个vector,即corres(pondents),
// 要求it.start_frame <= frame_count_l && it.endFrame() >= frame_count_r
vector<pair<Vector3d, Vector3d>> corres = f_manager.getCorresponding(frame_count - 1, frame_count);
Matrix3d calib_ric;
//旋转约束+SVD分解求取Ric旋转外参
if (initial_ex_rotation.CalibrationExRotation(corres, pre_integrations[frame_count]->delta_q, calib_ric))
{
ROS_WARN("initial extrinsic rotation calib success");
ROS_WARN_STREAM("initial extrinsic rotation: " << endl << calib_ric);
ric[0] = calib_ric;
RIC[0] = calib_ric;
ESTIMATE_EXTRINSIC = 1;
}
}
}
- 找到WINDOW内的倒数2nd和1st之间tracking上的点,用于八点法求解这两帧间的relative pose。
CalibrationExRotation是主要函数,用于标定旋转外参Ric,理论依据是旋转约束(下面会讲)。
下面依次讲解各部分代码。
1.1 八点法求取relative pose
重点函数solveRelativeR。
其中八点法求取Rt,correspondents不小于9时,1.求取E,2.反解并test出4组Rt,3.使用三角化出的深度来判断正确的那组Rt,这里 求E(看14讲),由E反解出4组Rt(看之前SLAM博客),三角化(看VIO博客),带点进Rt判断正深度来确定正确的Rt(看代码注释) 基本上都是调用的cv库函数,原理之前的SLAM和VIO课程中都有学过,相应回顾即可。
Matrix3d InitialEXRotation::solveRelativeR(const vector<pair<Vector3d, Vector3d>> &corres)
{
//大于9个点才进行求解,否则直接返回Identity
if (corres.size() >= 9)
{
vector<cv::Point2f> ll, rr;
for (int i = 0; i < int(corres.size()); i++)
{
//将找到的这两帧间的所有corr点收集起来,用于后面的 对极约束求本质矩阵E 和 三角化求深度
ll.push_back(cv::Point2f(corres[i].first(0), corres[i].first(1)));
rr.push_back(cv::Point2f(corres[i].second(0), corres[i].second(1)));
}
cv::Mat E = cv::findFundamentalMat(ll, rr);//对极约束求本质矩阵E=t^R
cv::Mat_<double> R1, R2, t1, t2;
decomposeE(E, R1, R2, t1, t2);
//这应该是什么判断
if (determinant(R1) + 1.0 < 1e-09)
{
E = -E;
decomposeE(E, R1, R2, t1, t2);
}
//用四个解分别进行Triangulation,带入points,求深度为正的比例,取比例最大的作为正确的Rt解
double ratio1 = max(testTriangulation(ll, rr, R1, t1), testTriangulation(ll, rr, R1, t2));
double ratio2 = max(testTriangulation(ll, rr, R2, t1), testTriangulation(ll, rr, R2, t2));
cv::Mat_<double> ans_R_cv = ratio1 > ratio2 ? R1 : R2;
Matrix3d ans_R_eigen;
for (int i = 0; i < 3; i++)
for (int j = 0; j < 3; j++)
ans_R_eigen(j, i) = ans_R_cv(i, j);
return ans_R_eigen;
}
return Matrix3d::Identity();
}
三角化以及反解E
//将一个点
double InitialEXRotation::testTriangulation(const vector<cv::Point2f> &l,
const vector<cv::Point2f> &r,
cv::Mat_<double> R, cv::Mat_<double> t)
{
cv::Mat pointcloud;
//因为triangulatePoints函数要传入分别两帧的pose,所以通常假设第一帧的外参pose是Identity,这样由relative Rt即可得第二帧的pose,即P1 = relative Rt
cv::Matx34f P = cv::Matx34f(1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0);
cv::Matx34f P1 = cv::Matx34f(R(0, 0), R(0, 1), R(0, 2), t(0),
R(1, 0), R(1, 1), R(1, 2), t(1),
R(2, 0), R(2, 1), R(2, 2), t(2));
//pointcloud是三角化的结果,是(4*m)维,其中m是传入的correspondents的对数,pointcloud每一列都是相应的三角化之后的为归一化的齐次坐标
cv::triangulatePoints(P, P1, l, r, pointcloud);
int front_count = 0;
for (int i = 0; i < pointcloud.cols; i++)
{
//用于归一化,使最后一维为1,这样前三维就是world系下的3D点了,乘以相应的pose就能转化为每个camera系下的3D点(非归一化平面,
// 如果再 /p_3d_r(2) 则可转化为归一化平面下的3D点,但是要使用深度是否>0来筛选出正确的Rt的解,所以就不归一化,见《14讲》P169)
double normal_factor = pointcloud.col(i).at<float>(3);
cv::Mat_<double> p_3d_l = cv::Mat(P) * (pointcloud.col(i) / normal_factor);
cv::Mat_<double> p_3d_r = cv::Mat(P1) * (pointcloud.col(i) / normal_factor);
if (p_3d_l(2) > 0 && p_3d_r(2) > 0)
front_count++;//统计正深度点的个数
}
ROS_DEBUG("MotionEstimator: %f", 1.0 * front_count / pointcloud.cols);
return 1.0 * front_count / pointcloud.cols;//统计所有pointcloud中正深度点的比率(不是很明白,不应该都是正的吗?直接取ratio=1的不行吗?)
}
//从E中分解出Rt
void InitialEXRotation::decomposeE(cv::Mat E,
cv::Mat_<double> &R1, cv::Mat_<double> &R2,
cv::Mat_<double> &t1, cv::Mat_<double> &t2)
{
cv::SVD svd(E, cv::SVD::MODIFY_A);
//绕z顺时针90°
cv::Matx33d W(0, -1, 0,
1, 0, 0,
0, 0, 1);
//绕z逆时针90°
cv::Matx33d Wt(0, 1, 0,
-1, 0, 0,
0, 0, 1);
R1 = svd.u * cv::Mat(W) * svd.vt;
R2 = svd.u * cv::Mat(Wt) * svd.vt;
t1 = svd.u.col(2);//3*3取最后一个是待求量(TODO:为什么t2可以直接取负号?)
t2 = -svd.u.col(2);
}
1.2 旋转约束和旋转residual的构建

两个路径求取的
q
b
k
c
k
+
1
q_{b_kc_{k+1}}
qbkck+1理想状态下相等,详见VIO Ch7博客2.2节
q
b
k
c
k
+
1
=
q
b
k
b
k
+
1
∗
q
b
c
=
q
b
c
∗
q
c
k
c
k
+
1
\begin{align} q_{b_kc_{k+1}} = q_{b_kb_{k+1}} * q_{bc} = q_{bc} * q_{c_kc_{k+1}} \end{align}
qbkck+1=qbkbk+1∗qbc=qbc∗qckck+1
但是实际情况,二者之间存在误差,即为residual,移项(左移右)即得residual:
r
e
s
i
d
u
a
l
=
q
b
c
−
1
∗
q
b
k
b
k
+
1
−
1
∗
q
b
c
∗
q
c
k
c
k
+
1
=
q
c
b
∗
q
b
k
+
1
b
k
∗
q
c
b
−
1
∗
q
c
k
c
k
+
1
\begin{align} residual &=q_{bc}^{-1}*q_{b_kb_{k+1}}^{-1} * q_{bc} * q_{c_kc_{k+1}} \tag{1.1} \\ &=q_{cb}*q_{b_{k+1}b_k} * q_{cb}^{-1} * q_{c_kc_{k+1}}\tag{1.2} \\ \end{align}
residual=qbc−1∗qbkbk+1−1∗qbc∗qckck+1=qcb∗qbk+1bk∗qcb−1∗qckck+1(1.1)(1.2)
上式(1.1)和(1.2)两种形式分别对应旋转外参
q
b
c
q_{bc}
qbc和
q
c
b
q_{cb}
qcb,跟后面左右乘的定义方式有关,代码中使用的(1.2)形式的定义,左乘L定义为 相机旋转四元数的左乘矩阵,右乘R定义为 IMU旋转四元数的右乘矩阵,下面会讲。
对应到CalibrationExRotation代码中:
-
Rc即 q c k c k + 1 q_{c_kc_{k+1}} qckck+1,由SfM获得,从第 k + 1 k+1 k+1帧到第 k k k帧的rotation -
Rimu即delta_q即 q b k + 1 b k q_{b_{k+1}b_k} qbk+1bk:由IMU预积分获得,从第 k k k帧积分到第 k + 1 k+1 k+1帧(这里有个细节,预计分量 P Q V ( α γ β ) PQV(\alpha\gamma\beta) PQV(αγβ)的下标都是从左往右读,而旋转 R 、 q R、q R、q是从右往左读,pre_integrations->delta_q即 β \beta β从 k k k积分到 k + 1 k+1 k+1的记法是 β k _ k + 1 \beta_{k\_k+1} βk_k+1,搞清楚这点,所有的坐标体系就自洽了,参考下图预积分的定义, q q q 和 α , β \alpha,\beta α,β 相乘的时候坐标相消,可以说明是从左往右读)
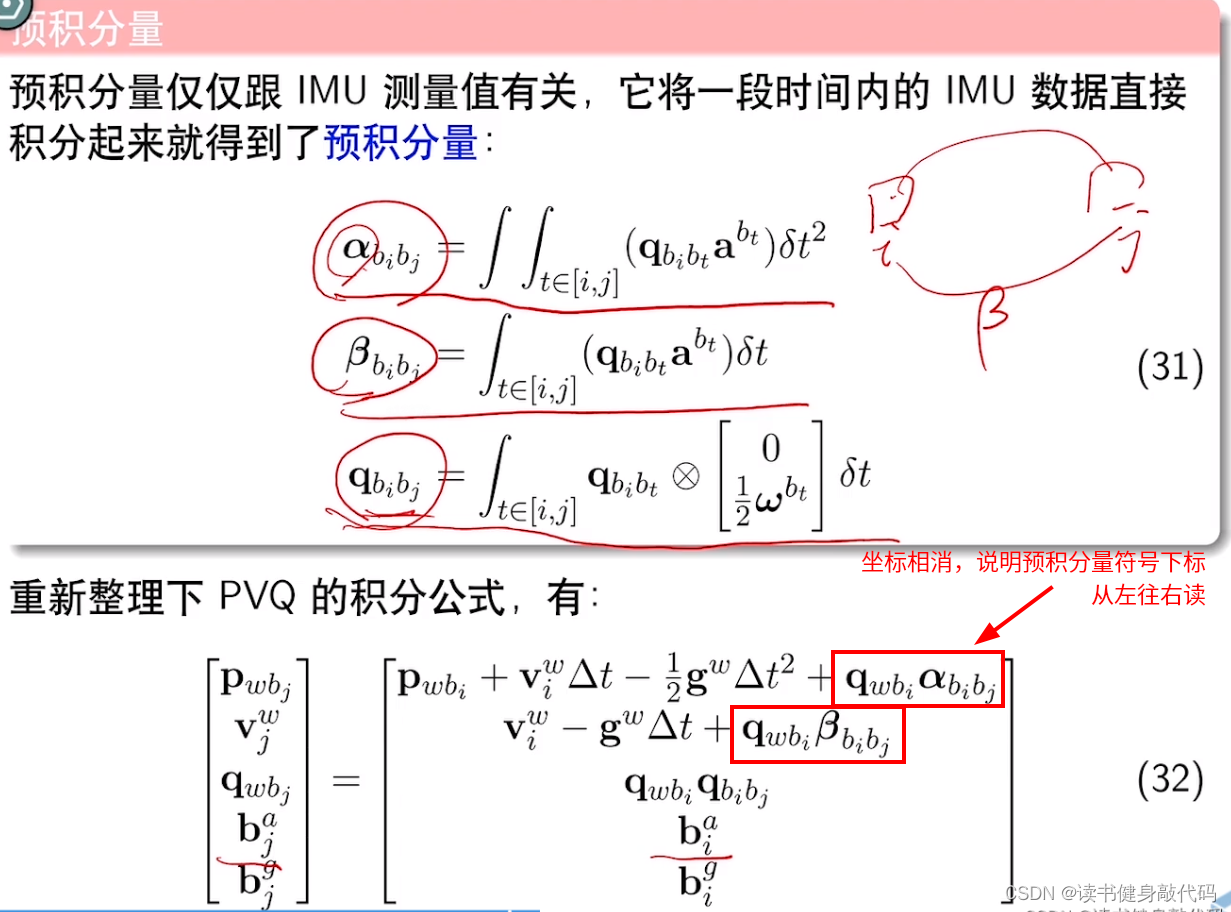
-
Rc_g即式(1.2)中剩下的左边部分 q c b ∗ q b k + 1 b k ∗ q c b − 1 = q c b ∗ β b k b k + 1 ∗ q c b − 1 q_{cb}*q_{b_{k+1}b_k} * q_{cb}^{-1}=q_{cb}*\beta_{b_{k}b_{k+1}} * q_{cb}^{-1} qcb∗qbk+1bk∗qcb−1=qcb∗βbkbk+1∗qcb−1
1.3 左乘右乘的构建
由于使用了式(1.2)形式来构建左右乘,所以式(1.2)整理为
(
[
q
c
k
c
k
+
1
]
L
−
[
q
b
k
+
1
b
k
]
R
)
q
b
c
=
0
\begin{align} ([\bm q_{c_kc_{k+1}}]_{\bm L} - [q_{b_{k+1}b_k}]_{\bm R})\bm{q}_{bc} = 0 \end{align}
([qckck+1]L−[qbk+1bk]R)qbc=0
崔华坤PDF中的

文献中的

二者形式上有差别,但是本质上应该是相同的,崔华坤PDF中的应该是根据代码推出来的,我们暂且使用这一套,对应到代码中:
//L为相机旋转四元数的左乘矩阵,记四元数为(w,x,y,z)
//实际构建的是qc_b
//构建结果为
//w -z y x
//z w -x y
//-y x w z
//-z -y -z w
double w = Quaterniond(Rc[i]).w();
Vector3d q = Quaterniond(Rc[i]).vec();
L.block<3, 3>(0, 0) = w * Matrix3d::Identity() + Utility::skewSymmetric(q);//构建A左上角3*3
L.block<3, 1>(0, 3) = q;
L.block<1, 3>(3, 0) = -q.transpose();
L(3, 3) = w;
//R为IMU旋转四元数的右乘矩阵,同样记四元数为(w,x,y,z)
//构建结果为
//w z -y x
//-z w x y
//y -x w z
//-x -y -z w
Quaterniond R_ij(Rimu[i]);
w = R_ij.w();
q = R_ij.vec();
R.block<3, 3>(0, 0) = w * Matrix3d::Identity() - Utility::skewSymmetric(q);
R.block<3, 1>(0, 3) = q;
R.block<1, 3>(3, 0) = -q.transpose();
R(3, 3) = w;
1.4 系数矩阵A的构建
如上构建出来的四元数左右乘矩阵均为(4*4)维,每组可构建一个式(2)所示的方程,多组correspondents构成多个方程,组成超定方程组,于是就需要构建超定方程组的系数矩阵
A
A
A,维度为(frame_count * 4, 4),如下所示:
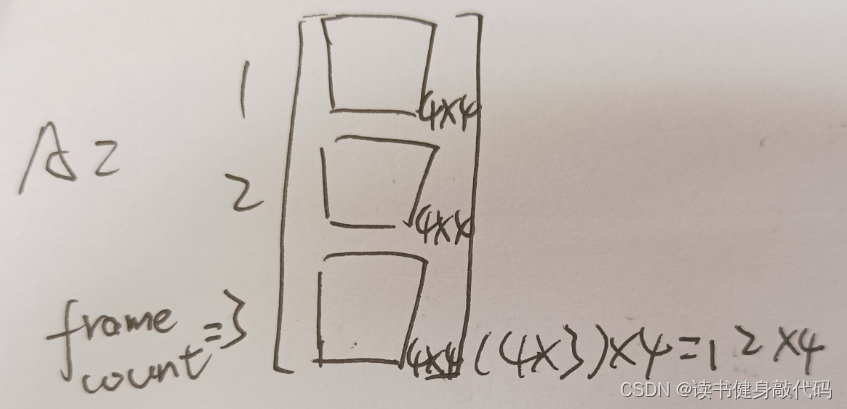
使用 SVD分解求解超定方程组,取最后一个特征值对应的特征向量即为我们所求的 q c b \bm q_{cb} qcb
1.5 鲁棒核函数
为了使方程具有更好的数值稳定性,在构建系数矩阵
A
A
A时根据每项的residual为相应的(4*4)块添加了权重
ω
\omega
ω,权重由Huber损失函数计算而得:

对应代码:
Quaterniond r1(Rc[i]);
Quaterniond r2(Rc_g[i]);
// 这里的angular_distance是角度误差,5是Huber核函数中的threshold,
// angularDistance: returns the angle (in radian) between two rotations返回两个旋转之间的相对旋转(弧度表示),再换算为角度
// 旋转矩阵R和轴角theta之间的关系:tr(R)=1+2cos(theta),所以theta=arccos( (tr(R)-1)/2 ),就是angularDistance的返回值
double angular_distance = 180 / M_PI * r1.angularDistance(r2);
ROS_DEBUG(
"%d %f", i, angular_distance);
//Huber鲁棒核函数
double huber = angular_distance > 5.0 ? 5.0 / angular_distance : 1.0;
其中angularDistance函数应该对应着上图的式(9),输出rad,代码中又转化为angle。式(8)中的threshold设为5。如此,方程的构建部分就全部完成。
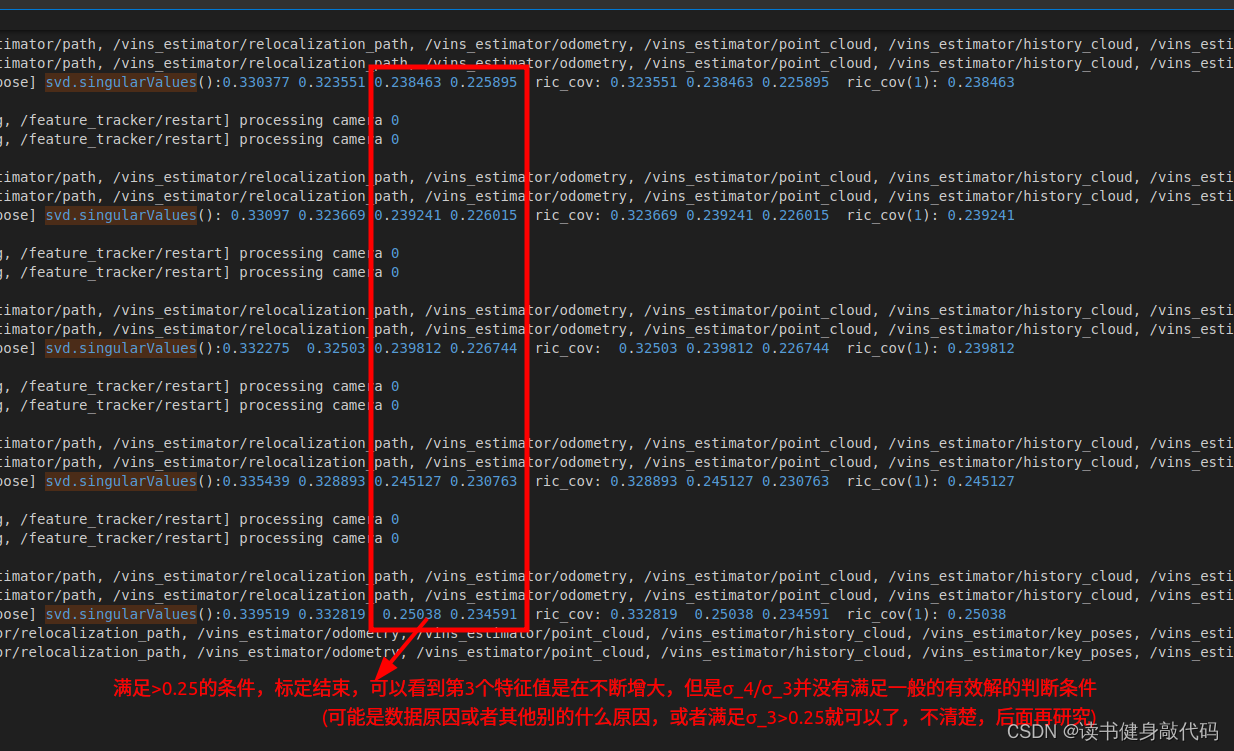
1.6 q c b q_{cb} qcb 的求解
使用SVD分解求解超定方程组,根据之前Triangulation的经验(博客第3.2节),需要对特征值 σ 4 / σ 3 \sigma_4/\sigma_3 σ4/σ3的比值进行判断,但是此处发现并没有满足远小于的条件,后面再探究吧。
关于特征值的判断条件:
至此已完成旋转外参标定的所有理论和代码部分的对应,附上该部分完整代码注释。
// 旋转约束标定Ric,两条路径求取的旋转应相同,所以移项构建方程,并根据误差项r的鲁棒核函数值w(r)对每一项的系数进行加权,将大于threshold的部分的权值设的较小,
// 最终使用SVD分解求取特征值最小的特征向量
// 详见第7章博客:https://blog.csdn.net/qq_37746927/article/details/133782580#t4
// 旋转约束:qbk_ck+1=qbk_bk+1*qbc=qbc*qck_ck+1
bool InitialEXRotation::CalibrationExRotation(vector<pair<Vector3d, Vector3d>> corres, Quaterniond delta_q_imu, Matrix3d &calib_ric_result)
{
frame_count++;
//correspondents对数不小于9时求出Rt: 1.求取E,2.反解并test出4组Rt,3.使用三角化出的深度来判断正确的那组Rt
//Rc即Rck_ck+1
Rc.push_back(solveRelativeR(corres));
//Rimu即delta_q即βbk_bk+1即Rbk+1_bk(预计分量下标的读取是从左到右)
Rimu.push_back(delta_q_imu.toRotationMatrix());
//旋转约束:qbk_ck+1 = qbk_bk+1 * qbc = qbc * qck_ck+1,移项(左移右)即得residual=qbc^(-1)*qbk_bk+1^(-1) * qbc * qck_ck+1,
//其中Rc=qck_ck+1,剩下的项就是qbc^(-1) * qbk_bk+1^(-1) * qbc = qcb * qbk+1_bk * qcb^(-1),记为Rc_g
//上式左边是rbc版本构建A时L为IMU,右边是rcb版本,构建A时L为camera,这里采用了后者rcb,L为camera
//注意这里下标不一样,PVQ预积分下标都是从左往右读,而正常的旋转是从右往左读,所以上面的Rc_g = qcb * qbk+1_bk * qcb^(-1)中,qbk+1_bk对应预积分就是βbk_bk+1
Rc_g.push_back(ric.inverse() * delta_q_imu * ric);//Rc_g * Rc就是整个左移右的residual
//构建A矩阵
Eigen::MatrixXd A(frame_count * 4, 4);//这个维度是什么意思?从第[1]帧开始
A.setZero();
int sum_ok = 0;
for (int i = 1; i <= frame_count; i++)
{
Quaterniond r1(Rc[i]);
Quaterniond r2(Rc_g[i]);
// 这里的angular_distance是角度误差,5是Huber核函数中的threshold,
// angularDistance: returns the angle (in radian) between two rotations返回两个旋转之间的相对旋转(弧度表示),再换算为角度
// 旋转矩阵R和轴角theta之间的关系:tr(R)=1+2cos(theta),所以theta=arccos( (tr(R)-1)/2 ),就是angularDistance的返回值
double angular_distance = 180 / M_PI * r1.angularDistance(r2);
ROS_DEBUG(
"%d %f", i, angular_distance);
//Huber鲁棒核函数
double huber = angular_distance > 5.0 ? 5.0 / angular_distance : 1.0;
++sum_ok;
Matrix4d L, R;
//L为相机旋转四元数的左乘矩阵,记四元数为(w,x,y,z)
//实际构建的是qc_b
//构建结果为
//w -z y x
//z w -x y
//-y x w z
//-z -y -z w
double w = Quaterniond(Rc[i]).w();
Vector3d q = Quaterniond(Rc[i]).vec();
L.block<3, 3>(0, 0) = w * Matrix3d::Identity() + Utility::skewSymmetric(q);//构建A左上角3*3
L.block<3, 1>(0, 3) = q;
L.block<1, 3>(3, 0) = -q.transpose();
L(3, 3) = w;
//R为IMU旋转四元数的右乘矩阵,同样记四元数为(w,x,y,z)
//构建结果为
//w z -y x
//-z w x y
//y -x w z
//-x -y -z w
Quaterniond R_ij(Rimu[i]);
w = R_ij.w();
q = R_ij.vec();
R.block<3, 3>(0, 0) = w * Matrix3d::Identity() - Utility::skewSymmetric(q);
R.block<3, 1>(0, 3) = q;
R.block<1, 3>(3, 0) = -q.transpose();
R(3, 3) = w;
A.block<4, 4>((i - 1) * 4, 0) = huber * (L - R);
}
JacobiSVD<MatrixXd> svd(A, ComputeFullU | ComputeFullV);
Matrix<double, 4, 1> x = svd.matrixV().col(3);
Quaterniond estimated_R(x);
ric = estimated_R.toRotationMatrix().inverse();//这里可以看到求得ric实际上是rci=rcb
//cout << svd.singularValues().transpose() << endl;
//cout << ric << endl;
Vector3d ric_cov;
ric_cov = svd.singularValues().tail<3>();
ROS_DEBUG_STREAM("svd.singularValues():" << svd.singularValues().transpose() << " ric_cov: " << ric_cov.transpose() << " ric_cov(1): " << ric_cov(1));
//这个取ric_cov相当于取所有特征值里面的第三个,要求它大于某个阈值,最后一个理论上来说应该是特别小的,
//根据SVD有效性判断方法,σ4 << σ3才算解有效,σ4/σ3比值的阈值一般取1e-2~1e-4算远小于,
//但是实际Debug发现SVD解出来的一半也不满足这个条件,所以ESTIMATE_EXTRINSIC直接config为0,不标了?
if (frame_count >= WINDOW_SIZE && ric_cov(1) > 0.25)
{
calib_ric_result = ric;
return true;
}
else
return false;
}
2. initialStructure()
这是初始化的主要函数,主要包含3部分:
- check IMU可观性(激励是否足够)
- 构建并求解visual SfM问题
- 视觉惯性对齐(估计重力向量 g c 0 g^{c_0} gc0,尺度 s s s,估计速度 v k , v k + 1 . . . v_k,v_{k+1}... vk,vk+1...,重力向量 g g g细化)
2.1 check IMU可观性(激励是否足够)
方法思想是:看window内的线加速度的标准差是否够大(threshold=0.25),大于threshol则证明加速度波动较大,激励充分,反之不充分。
-
遍历window内所有的
ImageFrame,将pre_integration的sum_dt累加求出改frame的总耗时,pre_integration->delta_v获取速度,计算 线加速度=速度/时间。 -
求线加速度的均值和标准差(注意
all_image_frame.size()共有all_image_frame.size()-1个线加速度,求mean和std_var时注意分母-1) -
标准差用阈值判断(此处的阈值设置为0.25,联想到标定qcb旋转外参使用SVD的特征值的那个0.25有关系吗?)
//check imu observibility
{
map<double, ImageFrame>::iterator frame_it;
Vector3d sum_g;
//遍历window内所有的ImageFrame
for (frame_it = all_image_frame.begin(), frame_it++; frame_it != all_image_frame.end(); frame_it++)
{
double dt = frame_it->second.pre_integration->sum_dt;//该帧总时间
Vector3d tmp_g = frame_it->second.pre_integration->delta_v / dt;//速度/时间=加速度
sum_g += tmp_g;
}
Vector3d aver_g;
aver_g = sum_g * 1.0 / ((int)all_image_frame.size() - 1);//线加速度均值,因为第一帧没有,所以-1
double var = 0;
for (frame_it = all_image_frame.begin(), frame_it++; frame_it != all_image_frame.end(); frame_it++)
{
double dt = frame_it->second.pre_integration->sum_dt;
Vector3d tmp_g = frame_it->second.pre_integration->delta_v / dt;
var += (tmp_g - aver_g).transpose() * (tmp_g - aver_g);
//cout << "frame g " << tmp_g.transpose() << endl;
}
var = sqrt(var / ((int)all_image_frame.size() - 1));//求线加速度的标准差
//ROS_WARN("IMU variation %f!", var);
if(var < 0.25)//如果加速度方差小于0.25,则证明加速度波动较小,证明IMU激励不够(TODO:这个0.25跟标定qcb旋转外参得手SVD的特征值的那个0.25有关系吗?)
{
ROS_INFO("IMU excitation not enouth!");
//return false;
}
}
2.2 构建并求解global visual SfM
由于后面标定gyro bias和重力向量等需要all_image_frame中各img之间的relative pose,所以需要先进行求解,所以需要先进行Visual SfM。
视觉SfM主要包含3部分
- 选取 l l l帧(SfM的world帧),求取 T l _ c u r T_{l\_cur} Tl_cur
- visual SfM对所有frame的PnP
- visual和IMU的align(估计gyro bias,scale,重力细化RefineGravity) (BA)
2.2.1 SfM数据结构
struct SFMFeature
{
bool state;//状态(是否被三角化)
int id;
vector<pair<int,Vector2d>> observation;//所有观测到该特征点的图像帧ID和图像坐标
double position[3];//3d坐标
double depth;//深度
};
- 遍历
f_manager.feature(该数据结构是list< vector< const Eigen::Matrix<double, 7, 1> &_point > >),将其存入到vector<SFMFeature> sfm_f中 - 选择window内第一个满足“tracking数量>20,平均视差>30”的帧( l l l)与最新帧之间的relative pose,是从最新帧到第 l l l帧(对应论文V.A节)
2.2.2 relativePose() 寻找world帧( l l l帧)并计算 T w _ c u r T_{w\_cur} Tw_cur
2.2.2.1 找corresponding,计算视差
讨论:
- 对于视差的计算,需要转化为像素单位,由于
getCorresponding返回的point是去畸变的归一化平面上的点,所以深度为1,使用 d i s p = f b d e p t h disp=\frac{fb}{depth} disp=depthfb即可算出disparity,但这是双目的模型,单目不知道b如何选取,这里如果用这个公式来理解,那么baseline=1,但是查看了些博客,baseline似乎跟参考帧的选择有关,双目其实也是两个单目,选的近,那么baseline就小,精度低;选的远,baseline就大,精度高,但是非凸。可能这里对于精度要求不高吧,因为后面还有PnP和BA。 - 还有如果选用不同的帧,没法保证去畸变之后各个特征点是rectify之后的,所以视差的计算就不局限于x方向,y方向也存在disparity,代码中也是计算的norm()而非disparity,所以上面的式子可能需要做一些变换,这个后面再来看。
//选择window内第一个满足tracking数量>20,平均视差>30的帧(l)与最新帧之间的relative pose,是从最新帧到第l帧
bool Estimator::relativePose(Matrix3d &relative_R, Vector3d &relative_T, int &l)
{
// find previous frame which contians enough correspondance and parallex with newest frame
//对应论文V.A节
for (int i = 0; i < WINDOW_SIZE; i++)
{
vector<pair<Vector3d, Vector3d>> corres;
// 找第i帧和buffer内最后一帧,(i, WINDOW_SIZE),之间的tracking上的点,构建一个pair,
// 所有pair是一个vector,即corres(pondents),first=前一帧的去畸变的归一化平面上的点,second=后一帧的
corres = f_manager.getCorresponding(i, WINDOW_SIZE);
if (corres.size() > 20)//要求两帧的共视点大于20对
{
double sum_parallax = 0;
double average_parallax;
for (int j = 0; j < int(corres.size()); j++)
{
Vector2d pts_0(corres[j].first(0), corres[j].first(1));
Vector2d pts_1(corres[j].second(0), corres[j].second(1));
double parallax = (pts_0 - pts_1).norm();//计算共视点的视差(欧氏距离)
sum_parallax = sum_parallax + parallax;
}
average_parallax = 1.0 * sum_parallax / int(corres.size());//平均视差
//用内参将归一化平面上的点转化到像素平面fx*X/Z + cx,cx相减抵消,z=1,所以直接就是fx*X
//求的Rt是当前帧([WINDOW_SIZE]帧)到第l帧的坐标系变换Rl_[WINDOW_SIZE]
if(average_parallax * 460 > 30 && m_estimator.solveRelativeRT(corres, relative_R, relative_T))
{
l = i;
ROS_DEBUG("average_parallax %f choose l %d and newest frame to triangulate the whole structure", average_parallax * 460, l);
return true;
}
}
}
return false;
}
2.2.2.2 视差满足后计算relative Rt (5点法)
标定旋转外参 R b c Rbc Rbc的时候使用的8点法,此处5点法,思路大致相同:1.对极几何求出E,2.反解出Rt,3.三角化,4.四个解带入用正深度判断正确的解。
cv::Mat mask;
cv::Mat E = cv::findFundamentalMat(ll, rr, cv::FM_RANSAC, 0.3 / 460, 0.99, mask);
cv::Mat cameraMatrix = (cv::Mat_<double>(3, 3) << 1, 0, 0, 0, 1, 0, 0, 0, 1);
cv::Mat rot, trans;
int inlier_cnt = cv::recoverPose(E, ll, rr, cameraMatrix, rot, trans, mask);
这里recoverPose直接把后234步都做了,里面关于_mask和4个good的具体细节没有仔细看,先挖个坑,后面再说。
//1.从E中恢复出Rt,并三角化,
//2.根据深度正负来找出正确的解
int recoverPose( InputArray E, InputArray _points1, InputArray _points2, InputArray _cameraMatrix,
OutputArray _R, OutputArray _t, InputOutputArray _mask)
{
Mat points1, points2, cameraMatrix;
_points1.getMat().convertTo(points1, CV_64F);
_points2.getMat().convertTo(points2, CV_64F);
_cameraMatrix.getMat().convertTo(cameraMatrix, CV_64F);
int npoints = points1.checkVector(2);
CV_Assert( npoints >= 0 && points2.checkVector(2) == npoints &&
points1.type() == points2.type());
CV_Assert(cameraMatrix.rows == 3 && cameraMatrix.cols == 3 && cameraMatrix.channels() == 1);
if (points1.channels() > 1)
{
points1 = points1.reshape(1, npoints);
points2 = points2.reshape(1, npoints);
}
double fx = cameraMatrix.at<double>(0,0);
double fy = cameraMatrix.at<double>(1,1);
double cx = cameraMatrix.at<double>(0,2);
double cy = cameraMatrix.at<double>(1,2);
points1.col(0) = (points1.col(0) - cx) / fx;
points2.col(0) = (points2.col(0) - cx) / fx;
points1.col(1) = (points1.col(1) - cy) / fy;
points2.col(1) = (points2.col(1) - cy) / fy;
points1 = points1.t();
points2 = points2.t();
Mat R1, R2, t;
//从E#中反解出两个R和1个t(这里传参只有一个t,感觉是因为另一个t实际上就是取负号,所以直接没定义)
decomposeEssentialMat(E, R1, R2, t);
Mat P0 = Mat::eye(3, 4, R1.type());
Mat P1(3, 4, R1.type()), P2(3, 4, R1.type()), P3(3, 4, R1.type()), P4(3, 4, R1.type());
P1(Range::all(), Range(0, 3)) = R1 * 1.0; P1.col(3) = t * 1.0;
P2(Range::all(), Range(0, 3)) = R2 * 1.0; P2.col(3) = t * 1.0;
P3(Range::all(), Range(0, 3)) = R1 * 1.0; P3.col(3) = -t * 1.0;
P4(Range::all(), Range(0, 3)) = R2 * 1.0; P4.col(3) = -t * 1.0;
// Do the cheirality check.
// Notice here a threshold dist is used to filter
// out far away points (i.e. infinite points) since
// there depth may vary between postive and negtive.
double dist = 50.0;
Mat Q;
triangulatePoints(P0, P1, points1, points2, Q);
Mat mask1 = Q.row(2).mul(Q.row(3)) > 0;
Q.row(0) /= Q.row(3);
Q.row(1) /= Q.row(3);
Q.row(2) /= Q.row(3);
Q.row(3) /= Q.row(3);
mask1 = (Q.row(2) < dist) & mask1;
Q = P1 * Q;
mask1 = (Q.row(2) > 0) & mask1;
mask1 = (Q.row(2) < dist) & mask1;
triangulatePoints(P0, P2, points1, points2, Q);
Mat mask2 = Q.row(2).mul(Q.row(3)) > 0;
Q.row(0) /= Q.row(3);
Q.row(1) /= Q.row(3);
Q.row(2) /= Q.row(3);
Q.row(3) /= Q.row(3);
mask2 = (Q.row(2) < dist) & mask2;
Q = P2 * Q;
mask2 = (Q.row(2) > 0) & mask2;
mask2 = (Q.row(2) < dist) & mask2;
triangulatePoints(P0, P3, points1, points2, Q);
Mat mask3 = Q.row(2).mul(Q.row(3)) > 0;
Q.row(0) /= Q.row(3);
Q.row(1) /= Q.row(3);
Q.row(2) /= Q.row(3);
Q.row(3) /= Q.row(3);
mask3 = (Q.row(2) < dist) & mask3;
Q = P3 * Q;
mask3 = (Q.row(2) > 0) & mask3;
mask3 = (Q.row(2) < dist) & mask3;
triangulatePoints(P0, P4, points1, points2, Q);
Mat mask4 = Q.row(2).mul(Q.row(3)) > 0;
Q.row(0) /= Q.row(3);
Q.row(1) /= Q.row(3);
Q.row(2) /= Q.row(3);
Q.row(3) /= Q.row(3);
mask4 = (Q.row(2) < dist) & mask4;
Q = P4 * Q;
mask4 = (Q.row(2) > 0) & mask4;
mask4 = (Q.row(2) < dist) & mask4;
mask1 = mask1.t();
mask2 = mask2.t();
mask3 = mask3.t();
mask4 = mask4.t();
// If _mask is given, then use it to filter outliers.
if (!_mask.empty())
{
Mat mask = _mask.getMat();
CV_Assert(mask.size() == mask1.size());
bitwise_and(mask, mask1, mask1);
bitwise_and(mask, mask2, mask2);
bitwise_and(mask, mask3, mask3);
bitwise_and(mask, mask4, mask4);
}
if (_mask.empty() && _mask.needed())
{
_mask.create(mask1.size(), CV_8U);
}
CV_Assert(_R.needed() && _t.needed());
_R.create(3, 3, R1.type());
_t.create(3, 1, t.type());
int good1 = countNonZero(mask1);
int good2 = countNonZero(mask2);
int good3 = countNonZero(mask3);
int good4 = countNonZero(mask4);
if (good1 >= good2 && good1 >= good3 && good1 >= good4)
{
R1.copyTo(_R);
t.copyTo(_t);
if (_mask.needed()) mask1.copyTo(_mask);
return good1;
}
else if (good2 >= good1 && good2 >= good3 && good2 >= good4)
{
R2.copyTo(_R);
t.copyTo(_t);
if (_mask.needed()) mask2.copyTo(_mask);
return good2;
}
else if (good3 >= good1 && good3 >= good2 && good3 >= good4)
{
t = -t;
R1.copyTo(_R);
t.copyTo(_t);
if (_mask.needed()) mask3.copyTo(_mask);
return good3;
}
else
{
t = -t;
R2.copyTo(_R);
t.copyTo(_t);
if (_mask.needed()) mask4.copyTo(_mask);
return good4;
}
}
2.2.3 构建并求解SfM问题(2.2节重点)
注意这里SfM求的都是从world系到camera系的 T c l T_{cl} Tcl,最后才转化为从camera系到world系的 T l c T_{lc} Tlc
2.2.3.1 求 T l _ w T_{l\_w} Tl_w和 T c u r _ w T_{cur\_w} Tcur_w
求 T l _ w = T l _ l = I d e n t i t y ( ) T_{l\_w}=T_{l\_l}=Identity() Tl_w=Tl_l=Identity() 和 T c u r _ w = T c u r _ l T_{cur\_w}=T_{cur\_l} Tcur_w=Tcur_l
2.2.3.2 三角化和PnP l l l 后的帧
三角化和PnP交替进行,直到解出[l~cur]中所有的landmark和pose:
跟 c u r 帧三角化 ( l , c u r ) − > 跟 l 帧 P n P ( l , l + 1 ) − > 跟 c u r 帧三角化 ( l + 1 , c u r ) − > 跟 l 帧 P n P ( l , l + 2 ) . . . 跟cur帧三角化(l,cur)->跟l帧PnP(l,l+1)->跟cur帧三角化(l+1,cur)->跟l帧PnP(l,l+2)... 跟cur帧三角化(l,cur)−>跟l帧PnP(l,l+1)−>跟cur帧三角化(l+1,cur)−>跟l帧PnP(l,l+2)...
需要指出,前面寻找第[ l l l]帧 前面的 l l l的筛选条件(tracking数量>20,平均视差>30),保证了[ l l l~ c u r cur cur]这中间的帧都是有tracking上的点的,至于在帧后(如第 l l l+1帧)才被insert进来的新点,在解出了 l + 1 l+1 l+1帧的pose之后就能使用pose进行三角化了,如此循环就能三角化解出[ l + 1 l+1 l+1~cur]中所有的landmark(当时看到这里感觉很妙)
//1: trangulate between l ----- frame_num - 1
//2: solve pnp l + 1; trangulate l + 1 ------- frame_num - 1;
//三角化(l,cur)->PnP(l+1,cur)->三角化(l+1,cur)->PnP(l+2,cur)...
//前面的l的筛选机制,保证了[l~cur]这中间的帧都是有tracking上的点的,至于在帧后(如第l+1帧)才被insert进来的新点,
//在解出了l+1帧的pose之后就能使用pose进行三角化了,如此循环就能三角化解出[l~cur]中所有的landmark
for (int i = l; i < frame_num - 1 ; i++)
{
// solve pnp
if (i > l)
{
Matrix3d R_initial = c_Rotation[i - 1];
Vector3d P_initial = c_Translation[i - 1];
if(!solveFrameByPnP(R_initial, P_initial, i, sfm_f))
return false;
c_Rotation[i] = R_initial;
c_Translation[i] = P_initial;
c_Quat[i] = c_Rotation[i];
Pose[i].block<3, 3>(0, 0) = c_Rotation[i];
Pose[i].block<3, 1>(0, 3) = c_Translation[i];
}
// triangulate point based on the solve pnp result手动三角化(SVD分解):找[i]和[frame_num - 1]中都tracking上的点(两次观测),构建Dy=0,SVD求解,结果齐次化
triangulateTwoFrames(i, Pose[i], frame_num - 1, Pose[frame_num - 1], sfm_f);
}
此处的三角化与CalibrationExRotation中用到的testTriangulation本质上相同,但此处的三角化是手写的,具体原理可看注释和之前的博客3.2节式(12)~(14):
void GlobalSFM::triangulateTwoFrames(int frame0, Eigen::Matrix<double, 3, 4> &Pose0,
int frame1, Eigen::Matrix<double, 3, 4> &Pose1,
vector<SFMFeature> &sfm_f)
{
assert(frame0 != frame1);
//TODO:感觉这个功能也可以用getCorresponding()来实现啊,找出来的是两帧之间的所有的corres,便利corres,对每个pair进行三角化,后面尝试一下
for (int j = 0; j < feature_num; j++)//遍历window内feature_id,即window内feature对应的3D landmark的个数
{
if (sfm_f[j].state == true)//如果该feature没有被Triangulate就继续Triangulation
continue;
bool has_0 = false, has_1 = false;//该landmark是否被frame0和frame1观测到
Vector2d point0;
Vector2d point1;
//遍历观测到该landmark的所有帧的frame_id,确定该landmark是否被frame0和frame1观测到
for (int k = 0; k < (int)sfm_f[j].observation.size(); k++)
{
if (sfm_f[j].observation[k].first == frame0)//vector<pair<int,Vector2d>> observation,pair<观测到该landmark的frame_id, feature 2D坐标>
{
point0 = sfm_f[j].observation[k].second;
has_0 = true;
}
if (sfm_f[j].observation[k].first == frame1)
{
point1 = sfm_f[j].observation[k].second;
has_1 = true;
}
}
if (has_0 && has_1)
{
Vector3d point_3d;
//手动三角化
triangulatePoint(Pose0, Pose1, point0, point1, point_3d);
sfm_f[j].state = true;//已三角化过
sfm_f[j].position[0] = point_3d(0);//读取3D landmark值
sfm_f[j].position[1] = point_3d(1);
sfm_f[j].position[2] = point_3d(2);
//cout << "trangulated : " << frame1 << " 3d point : " << j << " " << point_3d.transpose() << endl;
}
}
}
//手动三角化(底层实现是对构建的H矩阵进行SVD分解,取最后一个特征值对应的特征向量)
void GlobalSFM::triangulatePoint(Eigen::Matrix<double, 3, 4> &Pose0, Eigen::Matrix<double, 3, 4> &Pose1,
Vector2d &point0, Vector2d &point1, Vector3d &point_3d)
{
//构建Dy=0的系数矩阵D,维度是(2n,4),n为观测次数,这里是2次观测,一次观测有2个方程,所以就是(4,4)
//详见博客3.2节式(12)~(14):https://blog.csdn.net/qq_37746927/article/details/133693726#t4
Matrix4d design_matrix = Matrix4d::Zero();
design_matrix.row(0) = point0[0] * Pose0.row(2) - Pose0.row(0);
design_matrix.row(1) = point0[1] * Pose0.row(2) - Pose0.row(1);
design_matrix.row(2) = point1[0] * Pose1.row(2) - Pose1.row(0);
design_matrix.row(3) = point1[1] * Pose1.row(2) - Pose1.row(1);
Vector4d triangulated_point;
//SVD分解求出V的最右边一列即为最小特征值对应的特征向量
//return the singular value decomposition of \c *this computed by two-sided Jacobi transformations.
triangulated_point = design_matrix.jacobiSvd(Eigen::ComputeFullV).matrixV().rightCols<1>();
point_3d(0) = triangulated_point(0) / triangulated_point(3);//三角化出来的是非齐次的,/第4维变为齐次的3D landmark
point_3d(1) = triangulated_point(1) / triangulated_point(3);
point_3d(2) = triangulated_point(2) / triangulated_point(3);
}
solveFrameByPnP函数较简单:找已经被三角化过的共视点(不能太少,<10直接不用),用这些点来与
l
l
l进行PnP得
T
i
l
T_{il}
Til(内参为Identity,畸变为0)
//PnP求解第i帧与第l帧的pose:Tl_i
//输出: R_initial,P_initial
bool GlobalSFM::solveFrameByPnP(Matrix3d &R_initial, Vector3d &P_initial, int i,
vector<SFMFeature> &sfm_f)
{
vector<cv::Point2f> pts_2_vector;
vector<cv::Point3f> pts_3_vector;
for (int j = 0; j < feature_num; j++)
{
if (sfm_f[j].state != true)//如果该feature没有被三角化过则直接跳过
continue;
Vector2d point2d;
//这里都是已经被三角化过的landmark_id
for (int k = 0; k < (int)sfm_f[j].observation.size(); k++)
{
//如果这个id被第[i]帧观测到了(则也被cur观测到过,因为所有的Triangulation都是跟cur做的)
if (sfm_f[j].observation[k].first == i)
{
Vector2d img_pts = sfm_f[j].observation[k].second;
//第i帧里面的feature_num第j个id的landmark在sfm_f[j].observation的第[k]次观测里面的2D坐标
cv::Point2f pts_2(img_pts(0), img_pts(1));
pts_2_vector.push_back(pts_2);
//之前Triangulation出来的3D landmark坐标
cv::Point3f pts_3(sfm_f[j].position[0], sfm_f[j].position[1], sfm_f[j].position[2]);
pts_3_vector.push_back(pts_3);
break;
}
}
}
//如果两帧之间用于PnP的(即tracking上的点太少,则tracking不稳定,不能用于PnP,因为解出来的pose可能不准)
if (int(pts_2_vector.size()) < 15)
{
printf("unstable features tracking, please slowly move you device!\n");
if (int(pts_2_vector.size()) < 10)
return false;
}
cv::Mat r, rvec, t, D, tmp_r;//D畸变系数,设为0
cv::eigen2cv(R_initial, tmp_r);
cv::Rodrigues(tmp_r, rvec);
cv::eigen2cv(P_initial, t);
cv::Mat K = (cv::Mat_<double>(3, 3) << 1, 0, 0, 0, 1, 0, 0, 0, 1);//内参设为Identity()
bool pnp_succ;
pnp_succ = cv::solvePnP(pts_3_vector, pts_2_vector, K, D, rvec, t, 1);
if(!pnp_succ)
{
return false;
}
cv::Rodrigues(rvec, r);
//cout << "r " << endl << r << endl;
MatrixXd R_pnp;
cv::cv2eigen(r, R_pnp);
MatrixXd T_pnp;
cv::cv2eigen(t, T_pnp);
R_initial = R_pnp;
P_initial = T_pnp;
return true;
}
2.2.3.3 三角化 l l l没有的landmark
三角化cur帧中没有的(cur中的所有被tracking上的观测都已被trangulated),但是在l帧和其他帧中tracking上的landmark(这里三角化已经跟 l l l帧中的landmark进行了,没有用cur的,可能是为了保证更多的tracking上的点)
( l , l + 1 ) , ( l , l + 2 ) , ( l , l + 3 ) . . . ( l , f r a m e _ n u m − 2 ) (l,l+1),(l,l+2),(l,l+3)...(l,frame\_num -2) (l,l+1),(l,l+2),(l,l+3)...(l,frame_num−2)
//3: triangulate l-----l+1 l+2 ... frame_num -2
for (int i = l + 1; i < frame_num - 1; i++)
triangulateTwoFrames(l, Pose[l], i, Pose[i], sfm_f);
2.2.3.4 三角化和PnP l l l前的帧
往window l l l帧前 PnP&Triangulation
//4: solve pnp l-1; triangulate l-1 ----- l
// l-2 l-2 ----- l
//跟l帧PnP得Tl_l-1->跟l帧三角化得3D landmark->
// Tl_l-2-> 3D landmark->...
for (int i = l - 1; i >= 0; i--)
{
//solve pnp
Matrix3d R_initial = c_Rotation[i + 1];
Vector3d P_initial = c_Translation[i + 1];
if(!solveFrameByPnP(R_initial, P_initial, i, sfm_f))
return false;
c_Rotation[i] = R_initial;
c_Translation[i] = P_initial;
c_Quat[i] = c_Rotation[i];
Pose[i].block<3, 3>(0, 0) = c_Rotation[i];
Pose[i].block<3, 1>(0, 3) = c_Translation[i];
//triangulate
triangulateTwoFrames(i, Pose[i], l, Pose[l], sfm_f);
}
2.2.3.5 triangulate所有其他点
- 在求解完window内所有frame的pose( T i l T_{il} Til)后,可以对window内的任一个被观测超过1次的landmark进行Triangulation,比如只在 ( l − 2 , l − 1 ) (l-2,l-1) (l−2,l−1)之间tracking上的landmark,在与 l l l做Triangulation时是求不出来的
- 这里三角化剩下的点时有个细节,当某个id的landmark观测帧数大于1时,对该landmark进行triangulation时,取第一次和最后一次的观测量,尽量增大t,降低triangulation的不确定性,《14讲》 P 179 − 180 P_{179-180} P179−180
//5: triangulate all other points
//在求解完window内所有frame的pose(Tl_i)后,可以对window内的任一个被观测超过1次的landmark进行Triangulation,
//比如只在(l-2,l-1)之间tracking上的landmark,在与l做Triangulation时是求不出来的
for (int j = 0; j < feature_num; j++)
{
if (sfm_f[j].state == true)
continue;
//当某个id的landmark观测帧数大于1时,则可以对该landmark进行triangulation(取第一次和最后一次的观测量,尽量增大t,降低triangulation的不确定性,《14讲》P179~180)
if ((int)sfm_f[j].observation.size() >= 2)
{
Vector2d point0, point1;
int frame_0 = sfm_f[j].observation[0].first;//第一次观测
point0 = sfm_f[j].observation[0].second;
int frame_1 = sfm_f[j].observation.back().first;//最后一次观测
point1 = sfm_f[j].observation.back().second;
Vector3d point_3d;
triangulatePoint(Pose[frame_0], Pose[frame_1], point0, point1, point_3d);
sfm_f[j].state = true;
sfm_f[j].position[0] = point_3d(0);
sfm_f[j].position[1] = point_3d(1);
sfm_f[j].position[2] = point_3d(2);
//cout << "trangulated : " << frame_0 << " " << frame_1 << " 3d point : " << j << " " << point_3d.transpose() << endl;
}
}
至此已经完成了
- window内所有img frame相对于第l帧的pose求解: T i l T_{il} Til
- window内所有可Triangulation的点的三角化:3D landmark
接下来可以着手使用这些量进行window内的global BA了。
2.2.3.6 window内的BA
- 可以先简单复习一下ceres的用法。
- 然后就是构建problem和residualBlock,此处由于把 l l l当做world,所以fix了world的pose,并且还fix了 c u r cur cur帧的 t t t (不清楚为什么不fix q)。
- 最后整理求出的window内所有帧的pose: T w c = T l c T_{wc}=T_{lc} Twc=Tlc和所有的landmark,均是以第 l l l帧为world系。
//full BA 构建BA问题
ceres::Problem problem;
//当四元数为优化的对象时,需要调用ceres::QuaternionParameterization来消除自由度冗余
ceres::LocalParameterization* local_parameterization = new ceres::QuaternionParameterization();
//cout << " begin full BA " << endl;
for (int i = 0; i < frame_num; i++)
{
//double array for ceres
c_translation[i][0] = c_Translation[i].x();
c_translation[i][1] = c_Translation[i].y();
c_translation[i][2] = c_Translation[i].z();
c_rotation[i][0] = c_Quat[i].w();
c_rotation[i][1] = c_Quat[i].x();
c_rotation[i][2] = c_Quat[i].y();
c_rotation[i][3] = c_Quat[i].z();
problem.AddParameterBlock(c_rotation[i], 4, local_parameterization);
problem.AddParameterBlock(c_translation[i], 3);
//fix住world(l)系的pose和cur的t
if (i == l)
{
problem.SetParameterBlockConstant(c_rotation[i]);//world
}
if (i == l || i == frame_num - 1)
{
problem.SetParameterBlockConstant(c_translation[i]);
}
}
//用window内的frame pose和landmark构建残差块(4,3,3),并依次加入到problem中
for (int i = 0; i < feature_num; i++)
{
if (sfm_f[i].state != true)
continue;
for (int j = 0; j < int(sfm_f[i].observation.size()); j++)
{
int l = sfm_f[i].observation[j].first;
//自定义cost function,这里使用的是自动求导(AutoDiffCostFunction),也可以自定义解析Jacobian的计算方式
//解析求导比自动求导计算更快
ceres::CostFunction* cost_function = ReprojectionError3D::Create(
sfm_f[i].observation[j].second.x(),
sfm_f[i].observation[j].second.y());
problem.AddResidualBlock(cost_function, //cost_function
NULL, //loss_function,一般不用
c_rotation[l], //后面这3个都是优化的初值,维度分别为4,3,3
c_translation[l],
sfm_f[i].position);
}
}
ceres::Solver::Options options;
options.linear_solver_type = ceres::DENSE_SCHUR;
//options.minimizer_progress_to_stdout = true;
options.max_solver_time_in_seconds = 0.2;
ceres::Solver::Summary summary;
ceres::Solve(options, &problem, &summary);
//std::cout << summary.BriefReport() << "\n";
if (summary.termination_type == ceres::CONVERGENCE || summary.final_cost < 5e-03)
{
//cout << "vision only BA converge" << endl;
}
else
{
//cout << "vision only BA not converge " << endl;
return false;
}
//保存Twc
//旋转qwc
for (int i = 0; i < frame_num; i++)
{
q[i].w() = c_rotation[i][0]; //到cam系
q[i].x() = c_rotation[i][1];
q[i].y() = c_rotation[i][2];
q[i].z() = c_rotation[i][3];
q[i] = q[i].inverse();//转为qc_w转为qw_c
//cout << "final q" << " i " << i <<" " <<q[i].w() << " " << q[i].vec().transpose() << endl;
}
//平移twc
for (int i = 0; i < frame_num; i++)
{
T[i] = -1 * (q[i] * Vector3d(c_translation[i][0], c_translation[i][1], c_translation[i][2]));
//cout << "final t" << " i " << i <<" " << T[i](0) <<" "<< T[i](1) <<" "<< T[i](2) << endl;
}
for (int i = 0; i < (int)sfm_f.size(); i++)
{
if(sfm_f[i].state)
sfm_tracked_points[sfm_f[i].id] = Vector3d(sfm_f[i].position[0], sfm_f[i].position[1], sfm_f[i].position[2]);
}
return true;
2.2.3.7 buffer中所有帧all_image_frame内的global BA
由于并不是第一次视觉初始化就能成功,此时图像帧数目有可能会超过滑动窗口的大小,所以在视觉初始化的最后,要求出滑动窗口外的帧的位姿 T c w T_{cw} Tcw,转为 T w c T_{wc} Twc后,再使用外参转为 T w i = T w c ∗ T i c T = T w c ∗ T c i T_{wi}=T_{wc}*T_{ic}^T=T_{wc}*T_{ci} Twi=Twc∗TicT=Twc∗Tci(这里猜测可能是后面做全局pose graph要使用,但是此时的world不是真正的world,暂时不知道这么理解对不对)。
对于非滑动窗口的所有帧,提供一个初始的R,T,然后solve pnp求解pose。
问题:最开始会奇怪为什么会有这一步,在slidewindow内会删除旧的帧,all_image_frame不是应该跟window内的是一样的吗?
但是仔细看了slidewindow内才发现其中的不同:
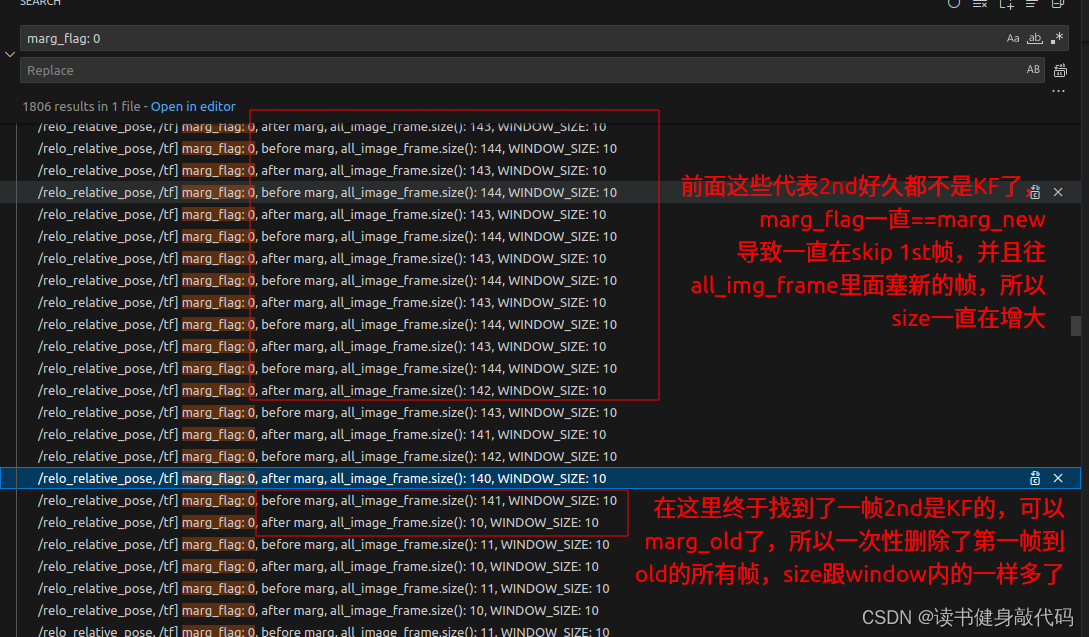
在marginalization_flag==MARGIN_OLD时会erase掉all_image_frame第一帧和要marg的old帧之间(含)的所有帧,但是在marginalization_flag==MARGIN_SECOND_NEW时却不会,这意味着在后一种情况下all_image_frame的size会不断增大,我们的WINDOW内的frame就来自其中。
在slideWindow的MARGIN_OLD部分加了下面两个ROS_DEBUG打印看了下:
dt_buf[WINDOW_SIZE].clear();
linear_acceleration_buf[WINDOW_SIZE].clear();
angular_velocity_buf[WINDOW_SIZE].clear();
ROS_DEBUG("marg_flag: %d, before marg, all_image_frame.size(): %lu, WINDOW_SIZE: %d",
marginalization_flag, all_image_frame.size(), WINDOW_SIZE);
if (true || solver_flag == INITIAL)
{
map<double, ImageFrame>::iterator it_0;
it_0 = all_image_frame.find(t_0);//t_0是最老帧的时间戳,marg_old时删掉了帧,但是marg2nd的时候没有动,但是在process时候加进来了,说明all_image_frame应该是在增长的
delete it_0->second.pre_integration;
it_0->second.pre_integration = nullptr;
for (map<double, ImageFrame>::iterator it = all_image_frame.begin(); it != it_0; ++it)
{
if (it->second.pre_integration)
delete it->second.pre_integration;
it->second.pre_integration = NULL;
}
all_image_frame.erase(all_image_frame.begin(), it_0);//erase掉从开始到被marg掉的old之间所有的帧
all_image_frame.erase(t_0);//erase掉old帧
}
slideWindowOld();//求prior,删除某些变量
ROS_DEBUG("marg_flag: %d, after marg, all_image_frame.size(): %lu, WINDOW_SIZE: %d",
marginalization_flag, all_image_frame.size(), WINDOW_SIZE);
Debug结果:
结果不出所料,all_image_frame多的时候能够塞140多帧,所以这一部分的PnP就是为了求出初始化阶段时all_image_frame内不在WINDOW内的帧(也即非KF帧)。
至此完成了初始化阶段一次视觉SfM的全部工作,后面就是重力向量,scale,速度,gravity_refinement部分了。
2.3 旋转约束标定陀螺仪偏置 solveGyroscopeBias()
从这节开始进行视觉惯性对准,对应VisualIMUAlignment,调用了两个函数solveGyroscopeBias,solveGyroscopeBias,分别用于 标定陀螺仪的偏置
b
g
b_g
bg 和 估计尺度,重力向量和速度。
bool VisualIMUAlignment(map<double, ImageFrame> &all_image_frame, Vector3d* Bgs, Vector3d &g, VectorXd &x)
{
//标定陀螺仪的偏置 bg
solveGyroscopeBias(all_image_frame, Bgs);
//估计尺度,重力向量和速度
if(LinearAlignment(all_image_frame, g, x))
return true;
else
return false;
}
估计陀螺仪bias仍然可以使用旋转约束,但是约束得构建与标定外参 q b c q_{bc} qbc时不同,在已经标定出外参 q b c q_{bc} qbc的基础上,只需使用相邻两帧构建出relative Rotation的观测和预测即可构建residual。
具体推导如下(这部分推导参考此博客的“陀螺仪偏置标定”章节)
细节问题:预计分量 γ b k + 1 b k \gamma^{b_k}_{b_{k+1}} γbk+1bk 是从上往下读,代表从 k k k 时刻积分到 k + 1 k+1 k+1 时刻的旋转预积分量。


//估计陀螺bias:bg
void solveGyroscopeBias(map<double, ImageFrame> &all_image_frame, Vector3d* Bgs)
{
Matrix3d A;
Vector3d b;
Vector3d delta_bg;//待求量
A.setZero();
b.setZero();
map<double, ImageFrame>::iterator frame_i;
map<double, ImageFrame>::iterator frame_j;
for (frame_i = all_image_frame.begin(); next(frame_i) != all_image_frame.end(); frame_i++)
{
frame_j = next(frame_i);//迭代器的下一个或上一个分别用next()和prev()获取。
MatrixXd tmp_A(3, 3);//3*3矩阵,关于bg的J^T*J
tmp_A.setZero();
VectorXd tmp_b(3);
tmp_b.setZero();
Eigen::Quaterniond q_ij(frame_i->second.R.transpose() * frame_j->second.R);//qc0_bk^(-1) * qc0_bk+1
tmp_A = frame_j->second.pre_integration->jacobian.template block<3, 3>(O_R, O_BG);//Jacobian中的f25
tmp_b = 2 * (frame_j->second.pre_integration->delta_q.inverse() * q_ij).vec();//预计分量,从i积分到j,γij
A += tmp_A.transpose() * tmp_A;
b += tmp_A.transpose() * tmp_b;
}
delta_bg = A.ldlt().solve(b);
ROS_WARN_STREAM("gyroscope bias initial calibration " << delta_bg.transpose());
//估计出bg后需要更新WINDOW中各帧对应的陀螺仪偏置,并重新propogate每一帧的预积分
for (int i = 0; i <= WINDOW_SIZE; i++)
Bgs[i] += delta_bg;
//为什么对所有帧重传,那没有更新bg的帧怎么办?
for (frame_i = all_image_frame.begin(); next(frame_i) != all_image_frame.end( ); frame_i++)
{
frame_j = next(frame_i);
frame_j->second.pre_integration->repropagate(Vector3d::Zero(), Bgs[0]);//预积分重新传递
}
}
其中Jacobian中的f25对应的是
∂
γ
k
+
1
∂
b
g
k
\frac{\partial \gamma_{k+1}}{\partial b_{g_k}}
∂bgk∂γk+1
结合之前FG的推导

对应代码:
void midPointIntegration(...) {
...
F.block<3, 3>(3, 12) = -1.0 * MatrixXd::Identity(3,3) * _dt;//f25,在估计gyro bias时用到了
...
}
估计出
δ
b
g
\delta b_{g}
δbg后需要更新WINDOW内的
b
g
b_g
bg,然后对现在all_image_frame所有的帧重新计算预积分(为什么对所有帧重传,那没有更新bg的帧怎么办?挖个坑)
2.4 估计速度、重力和尺度初始化,重力细化 LinearAlignment()
2.4.1 速度、重力和尺度初始化 LinearAlignment()
求解这部分就是对构建的最小二乘问题进行求解:
H
x
=
b
Hx=b
Hx=b
这里使用了二阶方法构建以下方程进行求解:
H
T
Σ
−
1
H
x
=
H
−
1
e
H^T\Sigma^{-1}Hx=H^{-1}e
HTΣ−1Hx=H−1e
代码中把所有的观测都放在一个方程中,构建一个大的超定方程组,
针对每个block有:
tmp_A即这里构建的
H
6
×
10
H^{6\times10}
H6×10矩阵,
tmp_b即残差项
e
6
×
1
e^{6\times1}
e6×1,
cov_inv为信息矩阵,设为
I
d
e
n
t
i
t
y
(
)
Identity()
Identity()
r_A即为带信息矩阵的Hessian的近似
(
H
T
Σ
−
1
H
)
10
×
10
(H^T\Sigma^{-1}H)^{10\times10}
(HTΣ−1H)10×10
每两帧之间的观测都是一个
10
×
10
10\times10
10×10的block,
e
e
e为
(
6
×
1
)
(6\times1)
(6×1)
每个block:
(
H
T
Σ
−
1
H
)
10
×
10
∗
x
10
×
1
=
(
H
T
)
10
×
6
∗
e
6
×
1
(H^T\Sigma^{-1}H)^{10\times10}*x^{10\times1}=(H^T)^{10\times6}*e^{6\times1}
(HTΣ−1H)10×10∗x10×1=(HT)10×6∗e6×1
整体
l
d
l
t
整体ldlt
整体ldlt求解即可。
细节问题:
- 构建H时涉及到
p
c
0
c
k
,
p
c
0
c
k
+
1
p_{c_0c_k},p_{c_0c_{k+1}}
pc0ck,pc0ck+1的都是不带米制单位的,所以构建时任意设了一个scale转换为米制单位,代码中设置的为
1
/
100
1/100
1/100,求出来scale之后也
/
100
/100
/100,不是很懂为什么。
tmp_A.block<3, 1>(0, 9) = frame_i->second.R.transpose() * (frame_j->second.T - frame_i->second.T) / 100.0;//这个100应该是任意取的s,转化为米制单位 double s = x(n_state - 1) / 100.0; - A和b在
l
d
l
t
ldlt
ldlt求解之前都
∗
1000
*1000
∗1000不知道是不是为了更好的数值稳定性
A = A * 1000.0; b = b * 1000.0; x = A.ldlt().solve(b);
这部分初始化的对应代码:
int all_frame_count = all_image_frame.size();
int n_state = all_frame_count * 3 + 3 + 1;//速度个数 * 3 + gc0 + scale尺度
MatrixXd A{n_state, n_state};
A.setZero();
VectorXd b{n_state};
b.setZero();
map<double, ImageFrame>::iterator frame_i;
map<double, ImageFrame>::iterator frame_j;
int i = 0;
for (frame_i = all_image_frame.begin(); next(frame_i) != all_image_frame.end(); frame_i++, i++)
{
frame_j = next(frame_i);//j > i
MatrixXd tmp_A(6, 10);//H(6,10)
tmp_A.setZero();
VectorXd tmp_b(6);//b(6,1)
tmp_b.setZero();
double dt = frame_j->second.pre_integration->sum_dt;
tmp_A.block<3, 3>(0, 0) = -dt * Matrix3d::Identity();
tmp_A.block<3, 3>(0, 6) = frame_i->second.R.transpose() * dt * dt / 2 * Matrix3d::Identity();//这里的frame_i->second.R是SfM最后输出的Rw_c=Rc0_c,所以对应到公式中的Rbk_c0就要取转置
tmp_A.block<3, 1>(0, 9) = frame_i->second.R.transpose() * (frame_j->second.T - frame_i->second.T) / 100.0;//这个100应该是任意取的s,转化为米制单位
tmp_b.block<3, 1>(0, 0) = frame_j->second.pre_integration->delta_p + frame_i->second.R.transpose() * frame_j->second.R * TIC[0] - TIC[0];//TIC的size为NUM_OF_CAM,单目所以直接取第一个了
//cout << "delta_p " << frame_j->second.pre_integration->delta_p.transpose() << endl;
tmp_A.block<3, 3>(3, 0) = -Matrix3d::Identity();
tmp_A.block<3, 3>(3, 3) = frame_i->second.R.transpose() * frame_j->second.R;//Rbk_c0*Rc0_bk+1
tmp_A.block<3, 3>(3, 6) = frame_i->second.R.transpose() * dt * Matrix3d::Identity();
tmp_b.block<3, 1>(3, 0) = frame_j->second.pre_integration->delta_v;//βbk_bk+1
//cout << "delta_v " << frame_j->second.pre_integration->delta_v.transpose() << endl;
Matrix<double, 6, 6> cov_inv = Matrix<double, 6, 6>::Zero();
//cov.block<6, 6>(0, 0) = IMU_cov[i + 1];
//MatrixXd cov_inv = cov.inverse();
cov_inv.setIdentity();//信息矩阵设为Identity,不进行加权
MatrixXd r_A = tmp_A.transpose() * cov_inv * tmp_A;//J^T*J
VectorXd r_b = tmp_A.transpose() * cov_inv * tmp_b;//J^Tb
//前6维
A.block<6, 6>(i * 3, i * 3) += r_A.topLeftCorner<6, 6>();
b.segment<6>(i * 3) += r_b.head<6>();
//后4维
A.bottomRightCorner<4, 4>() += r_A.bottomRightCorner<4, 4>();
b.tail<4>() += r_b.tail<4>();
A.block<6, 4>(i * 3, n_state - 4) += r_A.topRightCorner<6, 4>();
A.block<4, 6>(n_state - 4, i * 3) += r_A.bottomLeftCorner<4, 6>();
}
A = A * 1000.0;
b = b * 1000.0;
x = A.ldlt().solve(b);
double s = x(n_state - 1) / 100.0;
ROS_DEBUG("estimated scale: %f", s);
g = x.segment<3>(n_state - 4);//估计出来的重力向量gc0
ROS_DEBUG_STREAM(" result g " << g.norm() << " " << g.transpose());
if(fabs(g.norm() - G.norm()) > 1.0 || s < 0)//如果估计出来的重力向量和重力的差范数大于1或者scale<0则认为标定错误
{
return false;
}
2.4.2 重力细化 RefineGravity()
本小结主要两部分:1.重力向量参数化 2.使用参数化的重力,在上面的优化基础上再执行4次优化。
着重讲解第1部分。
2.4.2.1 重力向量参数化
对于我们优化的重力向量其实可以这样理解:优化的 g 3 × 1 g^{3\times1} g3×1理解为G.norm()=9.81在3个方向上分量的权值,把9.81按照权值来分摊到3个轴上,但是总体的模长还是9.81。
由于前面的优化过程中没有考虑到**重力向量的模长(9.81)**这个约束,所以需要细化。考虑到重力向量会受到扰动,在其他方向上会出现扰动分量,所以需要把9.81这一先验作为约束加入到优化中去,重新优化,这就是RefineGravity()的目的:使重力向量的估计更准确。
重力向量的模长已知,因此重力向量只剩两个自由度。
所有重力向量组成其三维球面流形,一个重力向量在流形上对应一个点,在该点处的正切空间是一个二维平面,即为该重力向量的切平面,我们用两个单位正交基来表示这个正切平面,与之前的优化结果叠加即可表示真正准确的重力向量:
g
^
=
∣
∣
g
∣
∣
g
^
‾
+
ω
1
b
1
+
ω
2
b
2
=
∣
∣
g
∣
∣
g
^
‾
+
b
3
×
2
w
2
×
1
\bm{\hat g}=||\bm g||\overline{\hat{\bm g}} + \omega_1\bm b_1+ \omega_2\bm b_2=||\bm g||\overline{\hat{\bm g}}+\bm b^{3\times2}\bm w^{2\times1}
g^=∣∣g∣∣g^+ω1b1+ω2b2=∣∣g∣∣g^+b3×2w2×1
其中
- w 2 × 1 = [ ω 1 , ω 2 ] T , b 3 × 2 = [ b 1 , b 2 ] \bm w^{2\times1}=[\omega_1, \omega_2]^T, \bm b^{3\times2}=[\bm{b_1}, \bm{b_2}] w2×1=[ω1,ω2]T,b3×2=[b1,b2];
- g ^ ‾ \overline{\hat{\bm g}} g^为上一步求得的重力方向;
-
b
1
,
b
2
\bm{b_1}, \bm{b_2}
b1,b2是
g
^
\bm{\hat g}
g^的正切平面上上的两个单位正交基,网上都说这样求:

但是对应不到代码中,研究了一下代码中的方法,其思想是:定义一个和 g ^ ‾ \overline{\hat{\bm g}} g^不相同的向量tmp(为 [ 1 , 0 , 0 ] T [1,0,0]^T [1,0,0]T或者 [ 0 , 0 , 1 ] T [0,0,1]^T [0,0,1]T),求tmp在 g ^ ‾ \overline{\hat{\bm g}} g^方向上的投影tmp_1,tmp_2=tmp-tmp_1就是b1方向上的向量,归一化后就是 b 1 b_1 b1,叉乘可得 b 2 = g ^ ‾ × b 1 \bm{b}_2=\overline{\hat{\bm g}}\times \bm b_1 b2=g^×b1//在半径为G的半球找到切面的一对单位正交基 MatrixXd TangentBasis(Vector3d &g0) { Vector3d b, c; Vector3d a = g0.normalized(); Vector3d tmp(0, 0, 1); if(a == tmp) tmp << 1, 0, 0; // 将tmp往a方向和a垂直方向分解为两个垂直的分量(tmp1,tmp2), // a * (a.transpose() * tmp)求的是将tmp往a方向投影获得的分量tmp1,而使用向量减法可获得tmp2=tmp-tmp1 // tmp2与a垂直,是a的正切空间的一个基向量,归一化之后就是单位基向量b,与a叉乘之后就得第二个单位基向量c b = (tmp - a * (a.transpose() * tmp)).normalized();//它是 tmp 减去在 a 方向上的投影,并进行归一化。 Vector3d tmp_b = a.cross(tmp).normalized(); ROS_DEBUG_STREAM("g0: " << g0.transpose() << " a:" << a.transpose() << " b from author's code: " << b.transpose() << " b from my corss multiply: " << tmp_b.transpose()); c = a.cross(b); MatrixXd bc(3, 2); bc.block<3, 1>(0, 0) = b; bc.block<3, 1>(0, 1) = c; return bc; }
向量投影的定义:
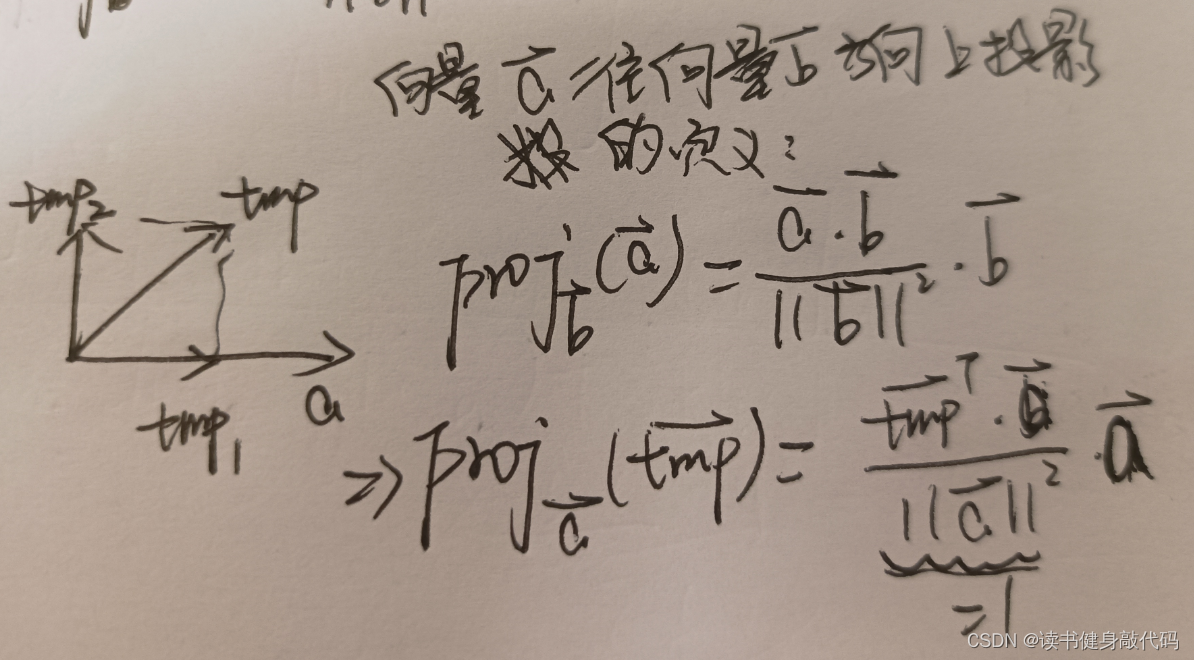
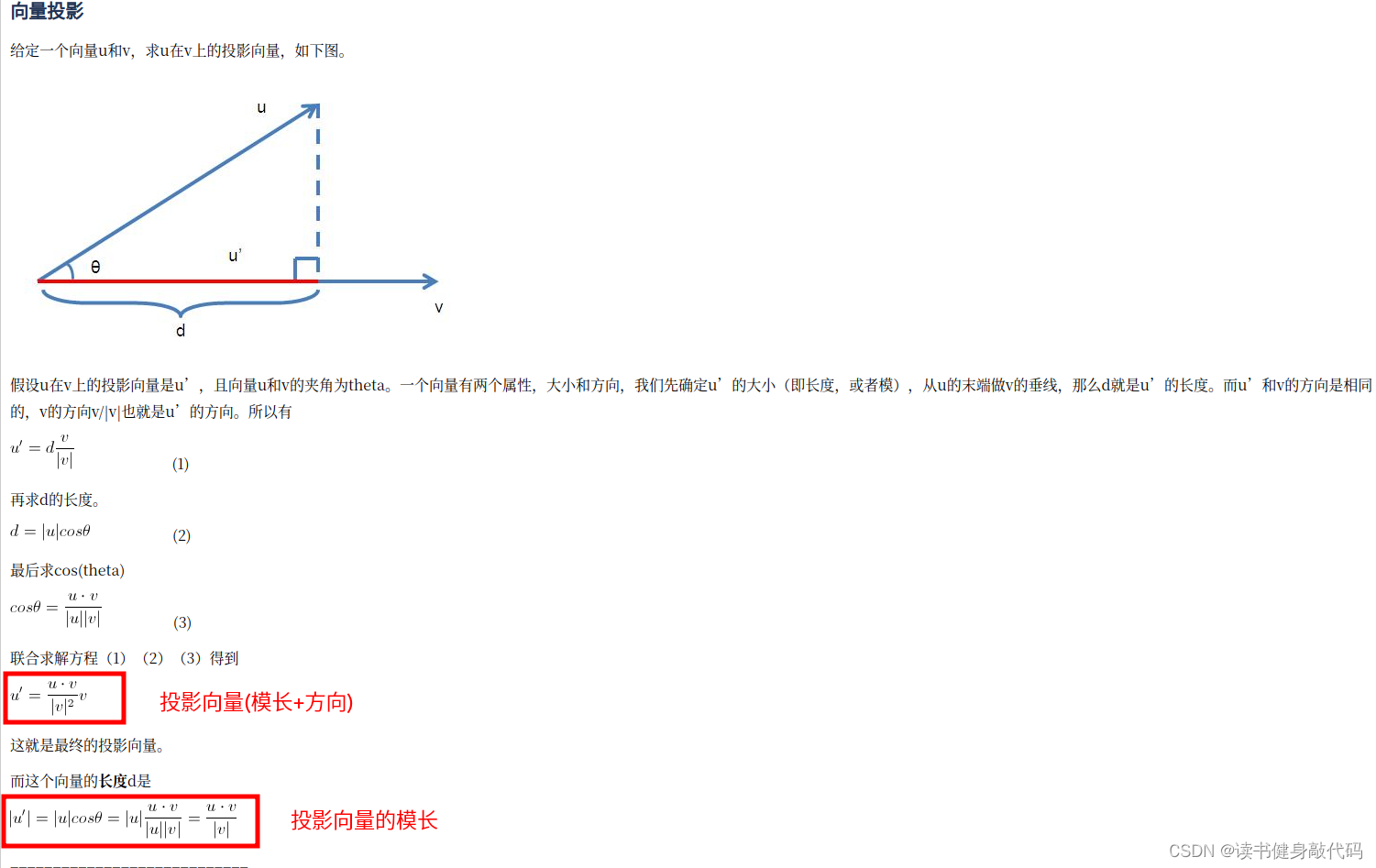
(这块可跳过不看)
灵感来自GPT-3.5,


投影公式推导过程
对应到论文中大概是这样理解(
b
1
,
b
2
\bm b_1,\bm b_2
b1,b2我换了位置)
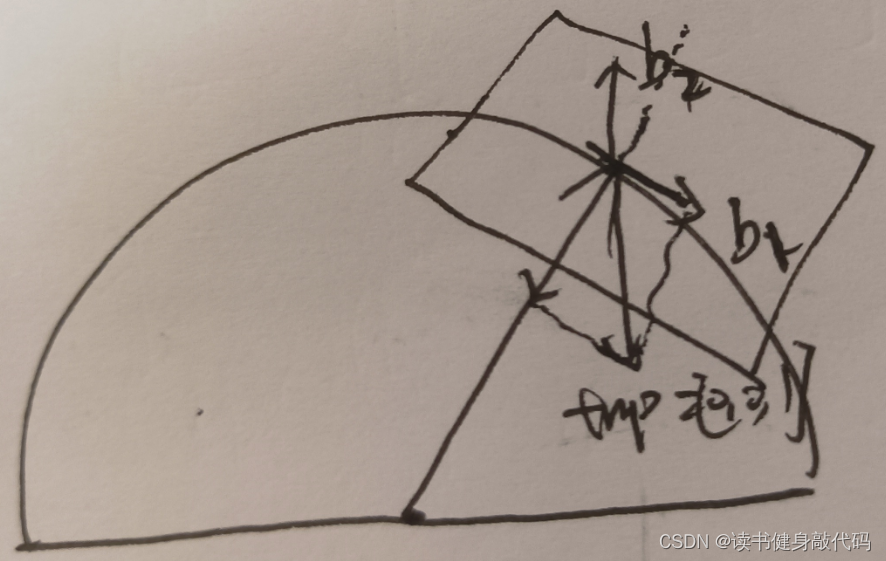
如此就完成了重力向量的参数化。
2.4.2.2 执行4次优化
重力向量参数化之后,需要更改待优化变量和观测方程
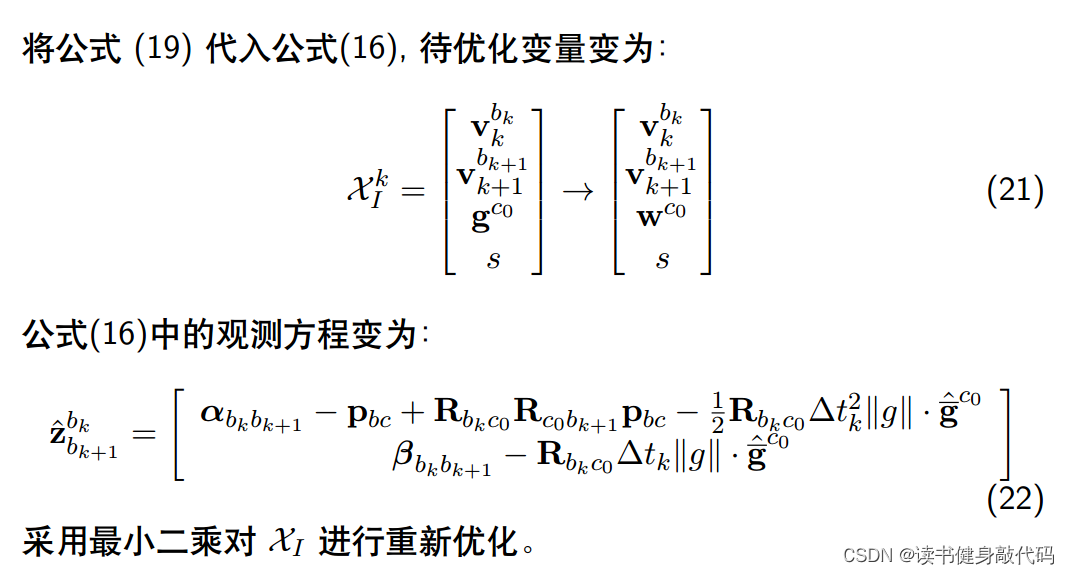
由于重力只有2维,所以待优化变量变为9维,代码中
g0即 ∣ ∣ g ∣ ∣ g ^ ‾ c 0 ||\bm g||\overline{\hat{\bm g}}^{c_0} ∣∣g∣∣g^c0lxly( 3 × 2 ) (3\times 2) (3×2)为为两个单位基向量 b 3 × 2 = [ b 1 , b 2 ] \bm b^{3\times2}=[\bm{b_1}, \bm{b_2}] b3×2=[b1,b2];VectorXd dg = x.segment<2>(n_state - 3);即 w 2 × 1 = [ ω 1 , ω 2 ] T \bm w^{2\times1}=[\omega_1, \omega_2]^T w2×1=[ω1,ω2]T
相应的观测方程和residual:
tmp_A.block<3, 2>(0, 6) = frame_i->second.R.transpose() * dt * dt / 2 * Matrix3d::Identity() * lxly;//权值放到待优化变量中去了,正切空间需要乘进来
tmp_b.block<3, 1>(0, 0) = frame_j->second.pre_integration->delta_p + frame_i->second.R.transpose() * frame_j->second.R * TIC[0] - TIC[0] - frame_i->second.R.transpose() * dt * dt / 2 * g0;
tmp_A.block<3, 2>(3, 6) = frame_i->second.R.transpose() * dt * Matrix3d::Identity() * lxly;//同理
tmp_b.block<3, 1>(3, 0) = frame_j->second.pre_integration->delta_v - frame_i->second.R.transpose() * dt * Matrix3d::Identity() * g0;
一次refinement共优化4轮,每轮优化结束后都更新一次g0
2.4.2.3 关于切空间的拓展(可跳过)
gravityRefinement()这里最大的创新点在于为重力向量定义了一种新的参数化方式,而这种参数化方式就借鉴了切空间。针对切空间,查阅了一些定义作为补充:

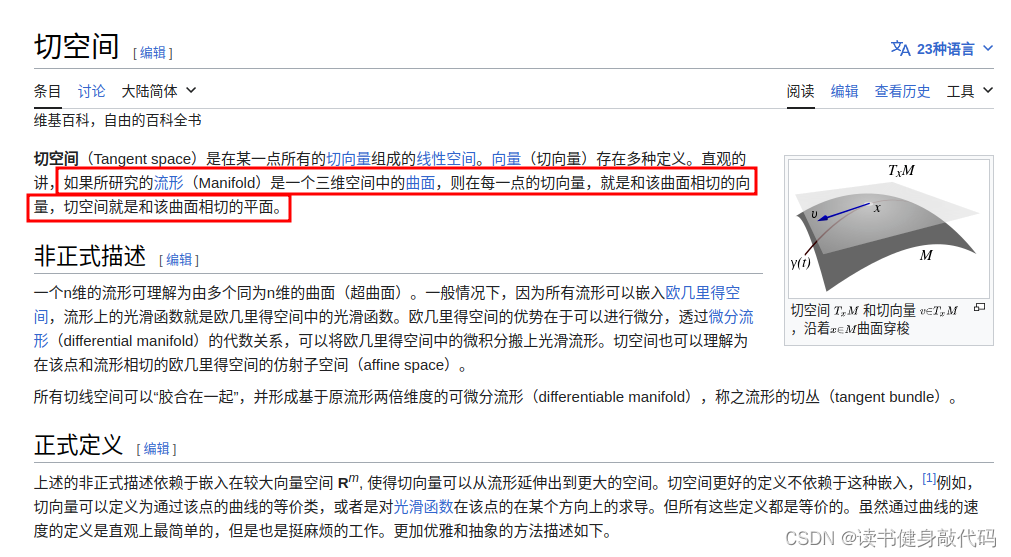
这里我们的先验是重力加速度的模长(≈9.81)和方向(前一步优化过方向),对于不同地方的重力向量,其模长大致相同,但是方向不同,而所有的重力向量构成了重力向量的流型(球面),这个流型是三维的。三维欧式空间中,在某一点的正切空间是二维的,即一个平面,我们求的这个平面相当于重力向量的噪声
δ
g
\delta \bm g
δg:
g
g
t
=
g
^
‾
+
δ
g
\bm g_{gt}=\bm{\overline{\hat g}} + \delta \bm g
ggt=g^+δg
而
δ
g
\delta \bm g
δg就在这个二维平面上,为了表示这个二维平面,我们就使用了两个单位基向量(类似的,也可以替换为其他的表示二维平面的方法)。
2.4.3 完成初始化
接下来就是恢复米制单位,转到真正的world系。
2.4.3.1 重新三角化
首先是对所有的WINDOW内所有之前三角化成功的landmark重新三角化(松耦合三角化),此处传入的Ps是
t
c
0
b
k
t_{c_0b_k}
tc0bk,三角化过程中转为
t
c
0
c
k
t_{c_0c_k}
tc0ck使用
void FeatureManager::triangulate(Vector3d Ps[], Vector3d tic[], Matrix3d ric[])
{
for (auto &it_per_id : feature)//WINDOW内的所有特征点
{
it_per_id.used_num = it_per_id.feature_per_frame.size();
if (!(it_per_id.used_num >= 2 && it_per_id.start_frame < WINDOW_SIZE - 2))
continue;
//跳过深度为正的点
if (it_per_id.estimated_depth > 0)
continue;
int imu_i = it_per_id.start_frame, imu_j = imu_i - 1;
ROS_ASSERT(NUM_OF_CAM == 1);
Eigen::MatrixXd svd_A(2 * it_per_id.feature_per_frame.size(), 4);
int svd_idx = 0;
//P0设为Identity()的T
Eigen::Matrix<double, 3, 4> P0;
Eigen::Vector3d t0 = Ps[imu_i] + Rs[imu_i] * tic[0];//Rc0_bk*tbc + tc0_bk即Tc0_bk * Tbc = Tc0_ck,从IMU系再转回camera系
Eigen::Matrix3d R0 = Rs[imu_i] * ric[0];
P0.leftCols<3>() = Eigen::Matrix3d::Identity();
P0.rightCols<1>() = Eigen::Vector3d::Zero();
//构建Dy=0矩阵,SVD求解
for (auto &it_per_frame : it_per_id.feature_per_frame)//遍历start_frame上一帧的所有feature
{
imu_j++;
Eigen::Vector3d t1 = Ps[imu_j] + Rs[imu_j] * tic[0];//Tc0_ck
Eigen::Matrix3d R1 = Rs[imu_j] * ric[0];
Eigen::Vector3d t = R0.transpose() * (t1 - t0);
Eigen::Matrix3d R = R0.transpose() * R1;
Eigen::Matrix<double, 3, 4> P;
P.leftCols<3>() = R.transpose();
P.rightCols<1>() = -R.transpose() * t;
//normalized之后不是归一化坐标了,但是模长为1,f为imu_j帧的观测[u',v',1]^T,标准化为[u,v,w]^T
Eigen::Vector3d f = it_per_frame.point.normalized();
ROS_DEBUG_STREAM("before normalized f: " << it_per_frame.point.transpose() <<" after normalized f: " << f.transpose());
//D找那个一个block的两行方程,当观测不为归一化坐标时,下面的构建是更一般的形式
//设观测为[u,v,w]^T,则D.block为:
//D.row(0) = u * (Tk,3)^T - w * (Tk,1)^T
//D.row(1) = v * (Tk,3)^T - w * (Tk,2)^T
svd_A.row(svd_idx++) = f[0] * P.row(2) - f[2] * P.row(0);
svd_A.row(svd_idx++) = f[1] * P.row(2) - f[2] * P.row(1);
if (imu_i == imu_j)
continue;
}
ROS_ASSERT(svd_idx == svd_A.rows());
//y取σ4对应的取特征向量,即最后一个 rightCols<1> size=(4,1)
Eigen::Vector4d svd_V = Eigen::JacobiSVD<Eigen::MatrixXd>(svd_A, Eigen::ComputeThinV).matrixV().rightCols<1>();
//齐次化得camera系下的深度
double svd_method = svd_V[2] / svd_V[3];
//it_per_id->estimated_depth = -b / A;
//it_per_id->estimated_depth = svd_V[2] / svd_V[3];
it_per_id.estimated_depth = svd_method;
//it_per_id->estimated_depth = INIT_DEPTH;
if (it_per_id.estimated_depth < 0.1)
{
it_per_id.estimated_depth = INIT_DEPTH;
}
}
}
关于triangulate函数中系数矩阵的构建,与之前的略有不同(之前的见博客3.2节式(12)~(14)),此处是更一般的形式,这里的观测是被normalized()的,观测记为
[
u
,
v
,
w
]
T
[u,v,w]^T
[u,v,w]T,不是标准的
[
u
,
v
,
1
]
T
[u,v,1]^T
[u,v,1]T的归一化平面的观测,保证模长为1是为了统一我们优化的深度
z
z
z(下面会讲为什么),对系数矩阵的构建做了一个简单的推导:
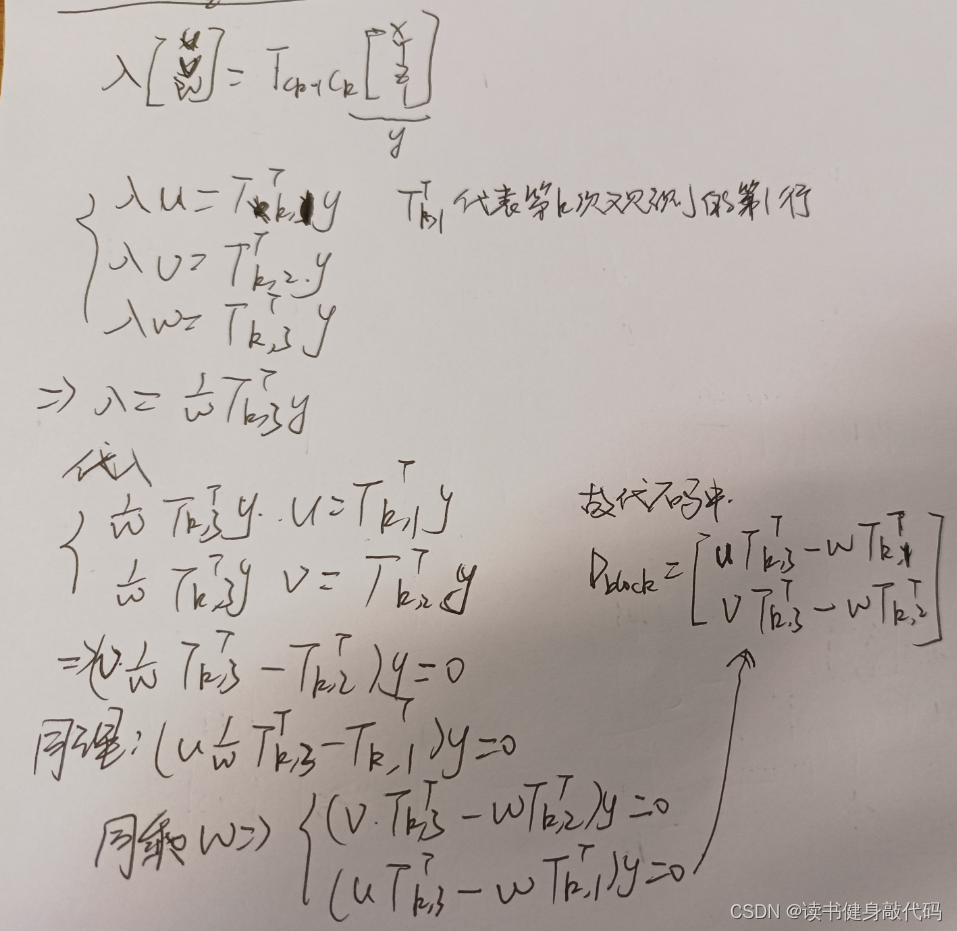
推导修正:
上图第1个公式
T
c
k
−
1
c
k
T_{c_{k-1}c_{k}}
Tck−1ck下标有些问题,对应到代码中应该是
λ
c
j
[
u
v
w
]
n
o
r
m
a
l
i
z
e
d
=
T
c
j
c
i
[
x
y
z
1
]
\lambda_{c_j} \begin{bmatrix} u\\v\\w \end{bmatrix}_{normalized}=T_{c_jc_i}\begin{bmatrix} x\\y\\z\\1 \end{bmatrix}
λcj
uvw
normalized=Tcjci
xyz1
其中
[
x
y
z
]
\begin{bmatrix} x\\y\\z \end{bmatrix}
xyz
代表
c
i
c_i
ci系下的3d坐标,其中
z
z
z就是我们要求的
c
i
c_i
ci系下的深度,左边整体是
c
j
c_j
cj系下的3d坐标,
λ
c
j
\lambda_{c_j}
λcj仅为推导中的临时变量,与
c
i
c_i
ci系下的深度有关。因为要对各个观测都建立方程,构建系数矩阵D的各个block,所以需要统一标准,这里是将观测normalized到单位球面(理论上来说都转到归一化平面也是可以的)。
另外说一句,我们所有的三角化求的都是camera系下的深度,我们初始化求出的尺度 s s s 也是将camera下的translation转换为world系下的米制单位。
需要明确,每次triangulate计算的都是某个landmark的start_frame(即imu_i)帧对应的camera系下的深度
z
c
i
z_{c_i}
zci,所以当marg掉start_frame时,其深度也要做相应的改变,比如代码中将深度传递到start_frame的下一帧,对应函数是removeBackShiftDepth(),讲到marg时可以回来看看这部分。
可能是为了保证代码的松耦合,不能假设传入的point就一定是 [ u , v , 1 ] T [u,v,1]^T [u,v,1]T,用更一般的形式去进行三角化能够保证三角化模块的正常运行。
代码中构建的[R0|t0],这样来理解:
T
c
0
b
[
i
]
∗
T
b
c
=
T
c
0
c
[
i
]
=
[
R
0
∣
t
0
]
T_{c_0b_{[i]}}*T_{bc} = T_{c_0c_{[i]}} = [R0|t0]
Tc0b[i]∗Tbc=Tc0c[i]=[R0∣t0]
要注意 c 0 c_0 c0是WINDOW[ l l l]的camera帧,而不是WINDOW[0]的camera帧,千万不要被下标搞混乱,后面表示 c 0 c_0 c0系都直接是 c 0 c_0 c0表示,而WINDOW[ i i i]帧则会加上方括号。
2.4.3.2 将Ps转换为 c 0 P b 0 b k ^{c_0}P_{b_0b_k} c0Pb0bk(难理解)
利用公式(6)转换成
c
0
P
b
0
b
k
^{c_0}P_{b_0b_k}
c0Pb0bk:
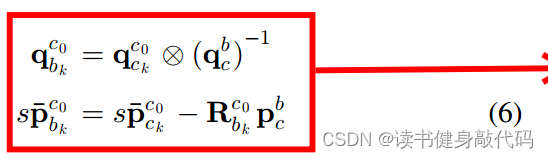
但是在代码中这块写的比较费解
//2.这里将Ps转换为(c0)tb0_bk
for (int i = frame_count; i >= 0; i--) {
//论文式(6),看起来Rs应该是Rc0_b[k](这个时候c0应该还没变为world,所以应该是在恢复米制单位)
Ps[i] = s * Ps[i] - Rs[i] * TIC[0] - (s * Ps[0] - Rs[0] * TIC[0]);//这里输入的Ps还是tc0_bk,输出的Ps是(c0)tb0_bk,是在c0系下看的这个translation
//TIC[0]为0, 第一项s * Ps[i] - Rs[i] * TIC[0]=s*Ps[i],即s*tc0_b[k]=s*tc0_c[k](因为此时Ps=tc0_b[k])
ROS_INFO_STREAM("TIC[0]:" << TIC[0].transpose()
<< "\ns * Ps[i] - Rs[i] * TIC[0]: " << (s * Ps[i] - Rs[i] * TIC[0]).transpose()
<< "\ns * Ps[i]: " << (s * Ps[i]).transpose()
<< "\nl_: " << l_
<< "\nPs[0]: " << Ps[0].transpose()//看他是否为0,如果不是0则证明我把c0和c[0]弄混了
<< "\ns * Ps[0]: " << (s * Ps[0]).transpose());
}
按照论文中的公式(6),上面循环中干的事情如下,以下公式观测坐标系写在左上角,
如
(
c
0
P
c
0
b
k
)
(^{c_0}P_{c_0b_k})
(c0Pc0bk)代表在
c
0
c_0
c0系下看从
c
0
c_0
c0系到
b
k
b_k
bk的平移向量
c
0
P
b
0
b
[
k
]
=
s
(
c
0
P
c
0
b
[
k
]
)
−
s
(
c
0
P
c
0
b
[
0
]
)
=
s
(
c
0
P
c
0
c
[
k
]
)
−
R
c
0
b
[
k
]
(
P
b
c
)
−
(
s
(
c
0
P
c
0
c
[
0
]
)
−
R
c
0
b
[
0
]
(
P
b
c
)
)
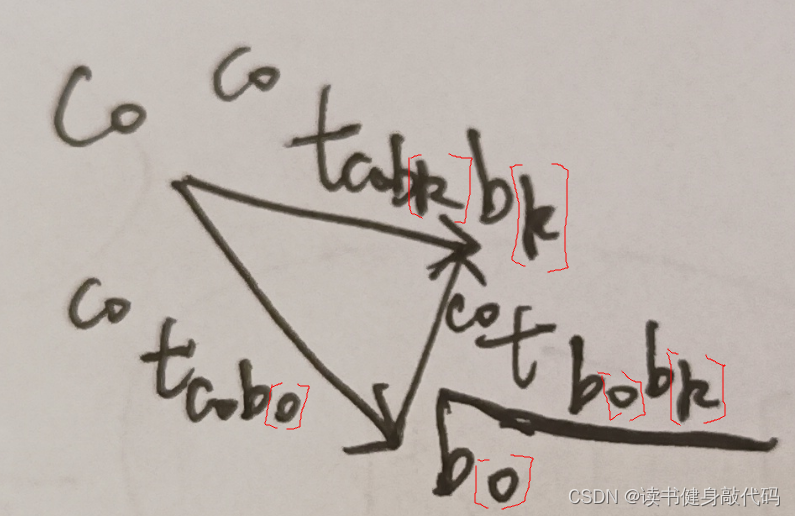
\begin{align} ^{c_0}P_{b_0b_{[k]}} &=s(^{c_0}P_{c_0b_{[k]}}) - s(^{c_0}P_{c_0b_{[0]}}) \notag \\ &=s(^{c_0}P_{c_0c_[k]})-R_{c_0b_{[k]}}(P_{bc})-(s(^{c_0}P_{c_0c_{[0]}})-R_{c_0b_{[0]}}(P_{bc})) \tag{A} \end{align}
c0Pb0b[k]=s(c0Pc0b[k])−s(c0Pc0b[0])=s(c0Pc0c[k])−Rc0b[k](Pbc)−(s(c0Pc0c[0])−Rc0b[0](Pbc))(A)
上式中
- P b c P_{bc} Pbc表示标定的外参 T b c T_{bc} Tbc的平移部分,由于没有对标定平移,所以 T b c = 0 T_{bc}=0 Tbc=0
-
(
c
0
P
c
0
c
[
0
]
)
(^{c_0}P_{c_0c_{[0]}})
(c0Pc0c[0]) 的取值根据l帧选取的不同而不同,
- 当 l = 0 l=0 l=0时, ( c 0 P c 0 c [ 0 ] ) = 0 (^{c_0}P_{c_0c_{[0]}})=0 (c0Pc0c[0])=0;
- 当
l
=
0
l=0
l=0时,
(
c
0
P
c
0
c
[
0
]
)
≠
0
(^{c_0}P_{c_0c_{[0]}})\neq0
(c0Pc0c[0])=0;


图示:
这里需要再次强调的是,计算的结果是表示在
c
0
c_0
c0观测的平移,而非
b
0
b_0
b0系下,如果理解为
b
0
b_0
b0系,那么后面的Ps[i] = rot_diff * Ps[i];这一句就无法解释了。
前面说了从all_image_frame[i].T中取出的Ps[]是
T
c
0
b
[
k
]
T_{c_0b_{[k]}}
Tc0b[k]的平移部分,即
P
c
0
b
[
k
]
P_{c_0b_{[k]}}
Pc0b[k],但是代码中直接将Ps[]当做
P
c
0
c
[
k
]
使用
P_{c_0c_{[k]}}使用
Pc0c[k]使用,这里依赖一个点:外参
T
b
c
T_{bc}
Tbc的平移
P
b
c
P_{bc}
Pbc设为
[
0
,
0
,
0
]
T
[0,0,0]^T
[0,0,0]T,将
P
b
c
P_{bc}
Pbc带入s上式
(
A
)
(\bm A)
(A)即可直接使用Ps。
2.4.3.3 速度和深度处理
对速度和深度进行处理
- body系下的速度转为 c 0 c_0 c0系下的速度: ( c 0 v k ) = ( c 0 R c 0 b k ) ( b k v k ) (^{c_0}v_k)=(^{c_0}R_{c_0b_k})(^{b_k}v_k) (c0vk)=(c0Rc0bk)(bkvk)
- 使用 s s s恢复刚才重新三角化的landmark的深度
int kv = -1;
map<double, ImageFrame>::iterator frame_i;
for (frame_i = all_image_frame.begin(); frame_i != all_image_frame.end(); frame_i++)
{
if(frame_i->second.is_key_frame)
{
kv++;
Vs[kv] = frame_i->second.R * x.segment<3>(kv * 3);//更新bk系下的速度:Rc0_bk * (bk)vk = (c0)vk
}
}
for (auto &it_per_id : f_manager.feature)
{
it_per_id.used_num = it_per_id.feature_per_frame.size();
if (!(it_per_id.used_num >= 2 && it_per_id.start_frame < WINDOW_SIZE - 2))
continue;
it_per_id.estimated_depth *= s;//恢复真实世界下尺度的深度
}
2.4.3.2 执行重力对齐 (重点,难理解)
这部分最难理解之处在于
y
a
w
yaw
yaw角的转换,重力对齐之后,
c
0
c_0
c0帧(即WINDOW内的
[
l
]
[l]
[l]帧)的重力跟world系已完成对齐,WINDOW内
c
0
c_0
c0(即此时WINDOW内的第
[
0
]
[0]
[0]帧)的yaw在world系下为0,而
c
0
c_0
c0帧对齐到world系后,其yaw确不为0。
这部分参考这篇博客里面的视频,讲的还算清楚。
下面是我的理解:
先上代码,有一些debug语句
//utility.cpp
#include <ros/ros.h>
Eigen::Matrix3d Utility::g2R(const Eigen::Vector3d &g)
{
Eigen::Matrix3d R0;
Eigen::Vector3d ng1 = g.normalized();
Eigen::Vector3d ng2{0, 0, 1.0};//真正z轴方向
R0 = Eigen::Quaterniond::FromTwoVectors(ng1, ng2).toRotationMatrix();//这是计算从ng1->ng2的旋转Rng2_ng1=Rgw_gc0
double yaw = Utility::R2ypr(R0).x();
R0 = Utility::ypr2R(Eigen::Vector3d{-yaw, 0, 0}) * R0;//-yaw即抵消在yaw方向上的旋转,只剩下pitch和roll方向的旋转,保证跟重力的z轴方向相同,不管yaw
ROS_DEBUG_STREAM("\nhere0 yaw = \n" << yaw <<
"\nR0.yaw = \n" << Utility::R2ypr(R0).x());
// R0 = Utility::ypr2R(Eigen::Vector3d{-90, 0, 0}) * R0;
return R0;
}
//estimator.cpp
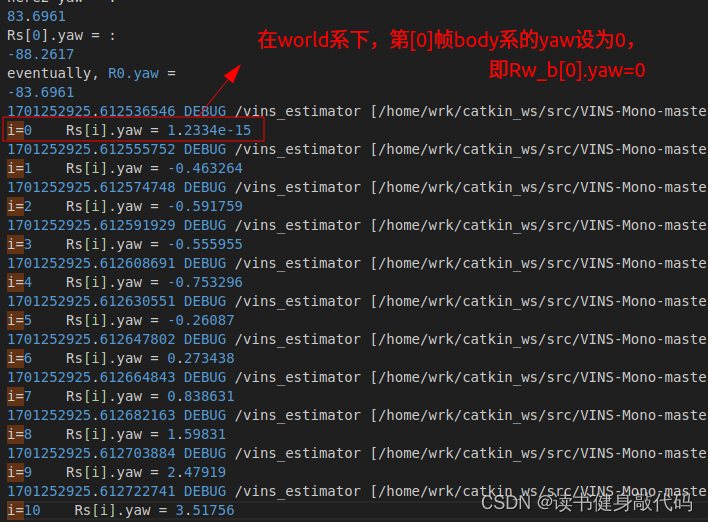
//g是world系下的重力向量,Rs[0]是Rc0_b0
ROS_DEBUG_STREAM("\nRs[0] is Rc0_b0:\n" << Rs[0]
<<"\nRbc^T:\n" << RIC[0].transpose());
Matrix3d R0 = Utility::g2R(g);//求出gc0->gw(0,0,1)的pitch和roll方向的旋转R0
ROS_DEBUG_STREAM("\nhere1 R0.yaw = \n" << Utility::R2ypr(R0).x());
Eigen::Vector3d here1_Rs0_ypr = Utility::R2ypr(Rs[0]);
double here1_Rs0_yaw = here1_Rs0_ypr.x();//Rs[0].yaw
double yaw = Utility::R2ypr(R0 * Rs[0]).x();
R0 = Utility::ypr2R(Eigen::Vector3d{-yaw, 0, 0}) * R0;
ROS_DEBUG_STREAM("\nhere2 yaw = :\n" << yaw <<
"\nRs[0].yaw = :\n" << here1_Rs0_yaw <<
"\neventually, R0.yaw = \n" << Utility::R2ypr(R0).x());
g = R0 * g;//g旋转到world系:Rwc0*g^(c0)=g^w
//Matrix3d rot_diff = R0 * Rs[0].transpose();
Matrix3d rot_diff = R0;
//(PRV)w_b[k] = Rw_b[0] * (PRV)c0_b[k]
for (int i = 0; i <= frame_count; i++)
{
Ps[i] = rot_diff * Ps[i];
Rs[i] = rot_diff * Rs[i];//(w)vb0_bk
Vs[i] = rot_diff * Vs[i];//(w)vb0_bk
ROS_DEBUG_STREAM("\ni=" << i <<" Rs[i].yaw = \n" << Utility::R2ypr(Rs[i]).x());
}
g2R函数中FromTwoVectors计算( c 0 g ^{c0}g c0g)方向到真正重力方向 ( w g ) (^wg) (wg)的变换矩阵R0,
即 R ( w g ) ( c 0 g ) R_{(^wg)(^{c0}g)} R(wg)(c0g),计算出与 R ( w g ) ( c 0 g ) R_{(^wg)(^{c0}g)} R(wg)(c0g)的yaw角,反向补偿在R0上,消去了R0中yaw角方向的旋转,只剩下pitch和roll方向的旋转,因为yaw不可观,我们只需要转pitch和roll(合在一起应该叫tilt角)就能把( c 0 g ^{c0}g c0g)的方向调整到与 ( w g ) ( 即 [ 0 , 0 , 1 ] T ) (^wg)(即[0,0,1]^T) (wg)(即[0,0,1]T)同向了,且转完之后, c 0 c_0 c0系在world系下的。-
double yaw = Utility::R2ypr(R0 * Rs[0]).x();这一句,R0 * Rs[0]即
( w R ( w g ) ( c 0 g ) ) ∗ ( c 0 R c 0 b [ 0 ] ) = R w c 0 ∗ R c 0 b [ 0 ] = ( w R w b [ 0 ] ) (^{w}R_{(^wg)(^{c0}g)})*(^{c_0}R_{c_0b_{[0]}})=R_{wc_0}*R_{c_0b_{[0]}}=(^{w}R_{wb_{[0]}}) (wR(wg)(c0g))∗(c0Rc0b[0])=Rwc0∗Rc0b[0]=(wRwb[0])是将第[0]帧body到camera的旋转 转换成 第[0]帧body到world的旋转。 - 取
(
w
R
w
b
[
0
]
)
(^{w}R_{wb_{[0]}})
(wRwb[0])的yaw角,取反旋转,补偿到
R0上,即补偿到 R w c 0 R_{wc_0} Rwc0上。(这一步最难理解) rot_diff就是 R w b [ 0 ] = ( w R w b [ 0 ] ) . y a w ∗ ( w R w c 0 ) R_{wb_{[0]}}=(^{w}R_{wb_{[0]}}).yaw * (^wR_{wc_{0}}) Rwb[0]=(wRwb[0]).yaw∗(wRwc0)- 最后,将估计的重力向量旋转到真正的world系,并将pose转到world系下(这里
rot_diff我们还按照 R w c 0 R_{wc_0} Rwc0来记,但是我们知道rot_diff使得world绑定在 c 0 c_0 c0系,且 b [ 0 ] b_{[0]} b[0]系在world下yaw=0): ( P R V ) w b [ k ] = R w c 0 ∗ ( P R V ) c 0 b [ k ] (PRV)_{wb_{[k]}} = R_{wc_0} * (PRV)_{c_0b_{[k]}} (PRV)wb[k]=Rwc0∗(PRV)c0b[k]
其中rot_diff这样理解:
- 对于
(
P
R
V
)
c
0
b
[
k
]
(PRV)_{c_0b_{[k]}}
(PRV)c0b[k],左乘一个
g2R()得到的 R ( w g ) ( c 0 g ) R_{(^wg)(^{c0}g)} R(wg)(c0g)(只含tilt,没有yaw方向的旋转),此时 z z z 轴已和 [ 0 , 0 , 1 ] T [0,0,1]^T [0,0,1]T的重力向量方向对齐,且 c 0 c_0 c0的yaw方向为world系下的0 - 再左乘一个yaw方向的旋转使得此时world系下的yaw=0的帧位于 b [ 0 ] b_{[0]} b[0]帧 。所以最终的打印如下图所示,body第[0]帧 R w b [ 0 ] R_{wb_{[0]}} Rwb[0],Rs[0].yaw=0(虽然不严格等于0,但是相当接近了),虽然yaw=0的帧在 b [ 0 ] b_{[0]} b[0]系,但是world其实还是绑定在 c 0 c_0 c0(即 c [ l ] ) c_{[l]}) c[l])系下的,如果做导航的话,navi系的第[0]帧应该就是 b [ 0 ] b_{[0]} b[0]系了。
希望我讲清楚了,看的糊涂的同学可以看看上面说的那个视频,对理解会有帮助。
至此,已经完成了VINS-MONO整个系统的全部初始化工作,简单回顾一下,我们完成了:
- 旋转约束外参的旋转部分 R b c R_{bc} Rbc的估计
- Visual SfM求得初始pose,并在此基础上使用旋转约束标定陀螺仪bias b g b_g bg
- 根据预积分约束,将每帧的速度,重力向量,系统的尺度放进一个向量中,构建最小二乘问题求解出这些变量,对于重力向量我们使用了一种新的参数化方式将重力向量参数化为 2 DoF的向量,并重新优化4次执行重力细化。
- 结合以上初始化结果,将估计的重力向量对齐到真正的world系,并将 P R V PRV PRV转化为world系下的量。
下一篇将讲述后端求解部分。















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









