







 本文分析了在COCO数据集上,小目标检测相对于大目标的性能差距,指出小目标样本不足和位置多样性低是主要原因。为此,提出了两种策略:一是对包含小目标的图像进行过采样,二是通过复制粘贴小目标来增强数据,增加位置多样性。实验结果显示,这两种方法能显著提升小目标检测的AP,与现有最先进的Mask R-CNN相比,分别实现了9.7%和7.1%的相对改进。
本文分析了在COCO数据集上,小目标检测相对于大目标的性能差距,指出小目标样本不足和位置多样性低是主要原因。为此,提出了两种策略:一是对包含小目标的图像进行过采样,二是通过复制粘贴小目标来增强数据,增加位置多样性。实验结果显示,这两种方法能显著提升小目标检测的AP,与现有最先进的Mask R-CNN相比,分别实现了9.7%和7.1%的相对改进。

前言
这篇论文和CutMix思路有点类似,不过该篇论文主要是针对小目标数据的增强,CutMix注重的是数据增强中正则化,泛化的问题。该篇论文发布于2019CVPR
Abstract
近年来,目标检测取得了令人瞩目的进展。尽管有这些改进,但在检测大小目标之间的性能仍有很大差距。我们在具有挑战性的数据集MS COCO上分析了当前最先进的模型Mask RCNN。我们表明,小的ground truth目标和预测的Anchor之间的重叠远低于预期的IoU阈值。我们推测这是由两个因素造成的;
(1) 只有少数图像包含小目标
(2)即使在包含小目标的每个图像中,小目标也显示得不够。
因此,我们建议使用小目标对这些图像进行过采样,并通过多次复制粘贴小目标来增强每个图像。它允许我们在大物体和小物体上权衡探测器的质量。我们评估了不同的粘贴增强策略,最终,与MS COCO上当前最先进的方法相比,我们在实例分割和小目标检测方面实现了9.7%的相对改进和7.1%的相对改进。
Introduction
COCO数据集上这几年的
A
P
s
m
a
l
l
AP_{small}
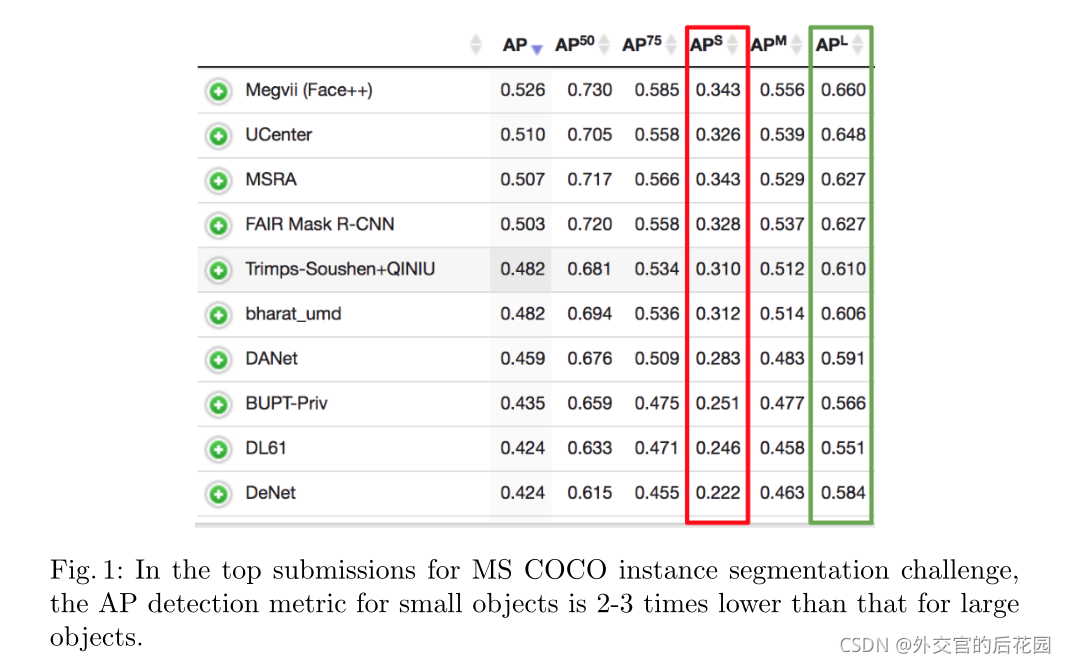
APsmall指标提升没有多大的突破,相比大目标指标低了2-3倍,如下图
COCO数据集中对小中大目标的定义:

Mask-RCNN预测结果中很多小目标被忽略,如下:
100只鸟类只有6只被标记出来

随着越来越复杂的系统部署在现实世界中,小目标检测和分割需要更多的关注。因此,我们提出了一种改进小目标检测的新方法。
我们将重点放在最先进的物体检测器Mask R-CNN[18]上,这是一个具有挑战性的数据集,即MS COCO。我们注意到这个数据集关于小目标的两个属性。
- 首先,我们观察到数据集中包含小目标的图像相对较少,这可能会使任何检测模型偏向于更多地关注中型和大型目标。
- 其次,小物体覆盖的面积要小得多,这意味着小物体的位置缺乏多样性。我们推测,这使得目标检测模型很难在测试时推广到小目标,因为它们出现在图像中探索较少的部分。
作者提出了解决方案:
- 我们通过对包含小目标的图像进行过采样来解决第一个问题。
- 第二个问题是通过在每个包含小目标的图像中多次复制粘贴小目标来解决的。
这里两个问题其实都是为了增加数据集中小目标的个数,只是采用了不同的方法实现。
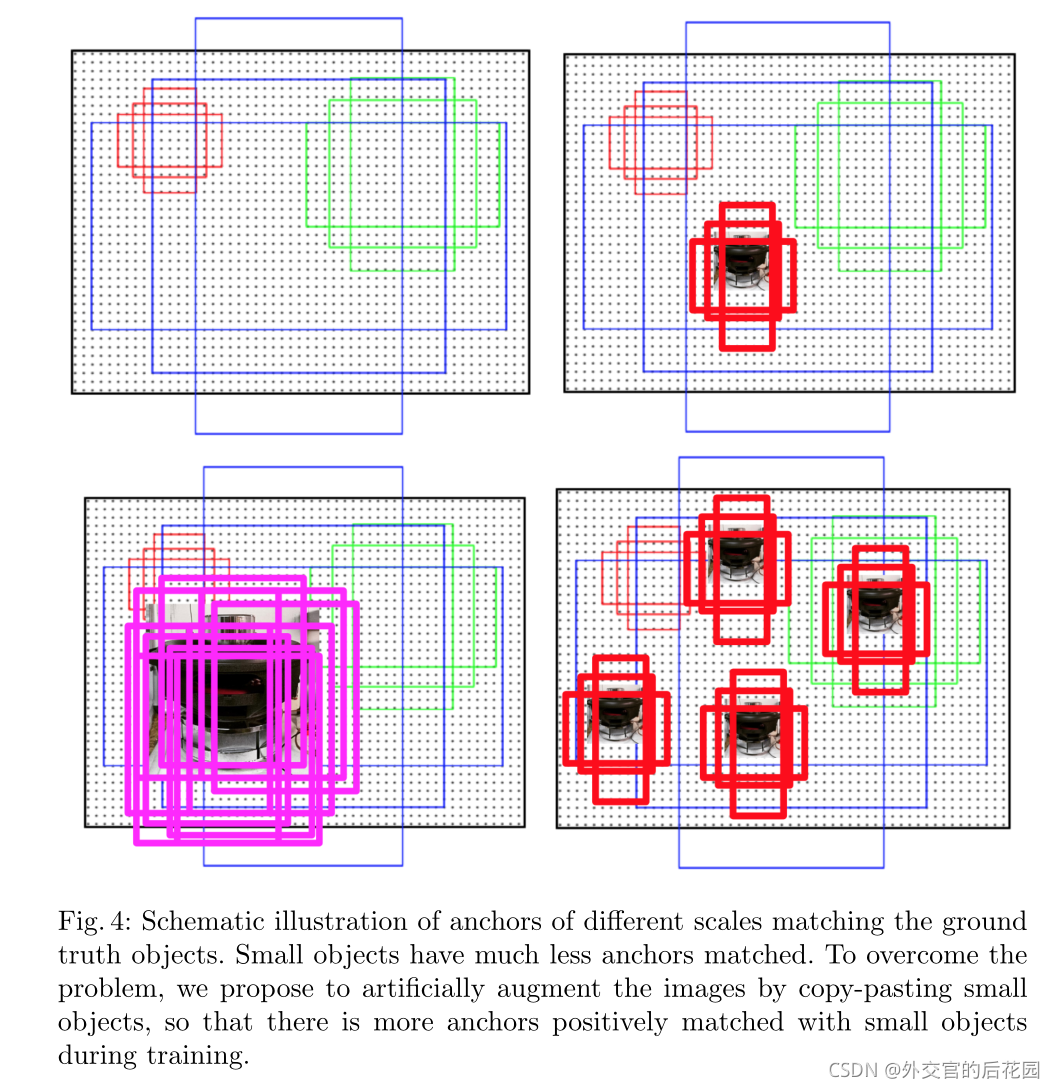
粘贴每个目标时,我们确保粘贴的目标不会与任何现有目标重叠。这增加了小目标位置的多样性,同时确保这些目标出现在正确的上下文中,如图3所示。每个图像中小目标数量的增加进一步解决了少量正匹配Anchor的问题,我们在第3节中对其进行了定量分析。总体而言,与MS COCO上当前最先进的方法Mask R-CNN相比,我们在实例分割和小目标目标检测方面分别实现了9.7%和7.1%的相对改进。

Related Work
小目标检测:小目标可通过以下两种方案来提高性能
- 提高输入图像分辨率
- 将高分辨率特征与低分辨率图像的高维特征融合
Identifying issues with detecting small objects
该节概述了MS COCO数据集和作者实验中使用的目标检测模型。然后讨论了MSCOCO数据集和训练中使用的Anchor匹配过程中导致小目标检测困难的问题
MSCOCO数据集中
s
m
a
l
l
,
m
e
d
i
u
m
,
l
a
r
g
e
small,medium,large
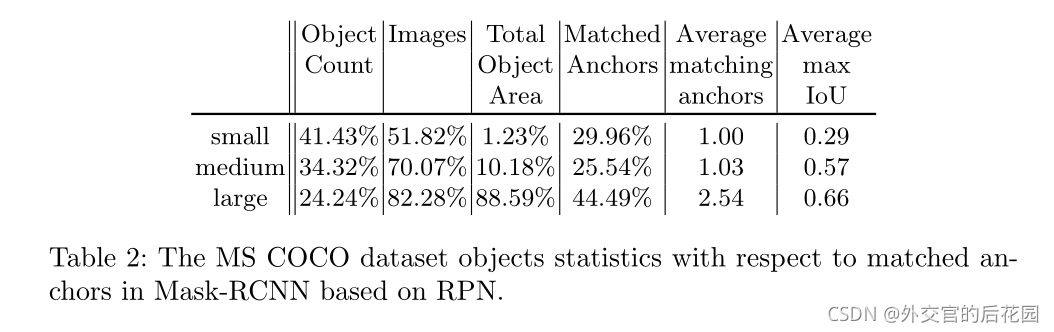
small,medium,large目标的占比和相应与Anchor匹配的程度等其他信息如下(基于RPN网络的Mask-RCNN)
MS COCO
我们使用MS COCO检测数据集进行了实验[25]。MS COCO 2017检测数据集包含118287张培训图像、5000张验证图像和40670张测试图像。来自80个类别的860001和36781目标使用ground truth边界框和实例遮罩进行注释。
在MS COCO检测挑战中,主要评估指标是平均精度(AP)。一般来说,AP被定义为所有召回值的真实阳性与所有阳性比率的平均值。由于目标需要定位并正确分类,因此,如果预测的遮罩或边界框的IoU高于0.5,则正确的分类仅算作真正的阳性检测。AP分数在80个类别和10个IoU阈值上取平均值,平均分布在0.5和0.95之间。这些指标还包括跨不同目标尺度测量的AP。在这项工作中,我们的主要兴趣是小目标上的AP。
Mask R-CNN
我们使用特征金字塔网络(FPN)生成object proposals。它从五个尺度
(
3
2
2
,
6
4
2
,
12
8
2
,
25
6
2
,
51
2
2
)
(32^2,64^2,128^2,256^2,512^2)
(322,642,1282,2562,5122)和三个纵横比
(
1
,
0.5
,
2
)
(1,0.5,2)
(1,0.5,2)预测与十五个Anchor Boxes相关的object proposals。如果Anchor在任何ground truth值框上的IoU高于0.7,或者在ground truth边界框上的IoU最高,Anchor就会收到一个正标签。

Small object detection by Mask R-CNN on MS COCO
在MS COCO中,训练集中出现的所有目标中有41.43%是小目标,而中目标和大目标分别只有34.4%和24.2%。另一方面,只有大约一半的训练图像包含任何小目标,而70.07%和82.28%的训练图像分别包含中型和大型目标。请参见表2中的目标计数和图像。这证实了小物体检测问题背后的第一个问题:小物体的例子很少。
通过考虑每个尺寸类别的目标总面积,第二个问题很明显。只有1.23%的标注像素属于小目标。中等大小的目标占用的面积已经超过8倍,占注释像素总数的10.18%,而大多数像素,82.28%标记为大型目标的一部分。在此数据集上训练的任何检测器都无法在图像和像素之间看到足够多的小目标。
如本节前面所述,如果region proposal网络中的每个预测Anchor都和ground truth具有最高的IoU,或者对于任何ground truth,其IoU都高于0.7,则每个预测Anchor都会收到一个positive标签。此过程非常有利于大型目标,因为跨越多个滑动窗口位置的大型目标通常具有具有多个Anchor定框的高IoU,而小型目标可能仅与具有低IoU的单个Anchor框匹配。如表2所示,只有29.96%的正匹配Anchor与小物体配对,而44.49%的正匹配Anchor与大物体配对。
从另一个角度来看,它意味着每个大目标有2.54个匹配的Anchor,而每个小目标只有一个匹配的Anchor。此外,正如平均最大IoU度量所揭示的,即使是小目标的最佳匹配Anchor框也通常具有较低的IoU值。小型目标的平均最大IoU仅为0.29,而中型和大型目标的最佳匹配定位点约为IoU的两倍,分别为0.57和0.66。我们在图5中通过可视化几个例子来说明这种现象。这些观察结果表明,小目标对计算区域建议损失的贡献要小得多,这使整个网络偏向于大目标和中等目标。
Oversampling and Augmentation
Oversampling
我们通过在训练期间对图像进行过采样来解决包含小目标的图像相对较少的问题[4]。这是一种轻松而直接的方法来缓解MS COCO数据集的这个问题,并提高小目标检测的性能。在实验中,我们改变过采样率,研究过采样不仅对小目标检测的影响,而且对中、大目标检测的影响。
Augmentation
在过采样的基础上,我们还引入了集中于小目标的数据集扩充。MS COCO数据集中提供的实例分割掩码允许我们从原始位置复制任何目标。然后将副本粘贴到不同的位置。通过增加每个图像中小目标的数量,匹配的定位点的数量会增加。这反过来又提高了小目标在训练期间对计算RPN损失函数的贡献。
在将目标粘贴到新位置之前,我们对其应用随机变换。我们通过更改目标大小±20%来缩放目标,并将其旋转±15%◦. 我们只考虑非被遮挡的目标,因为粘贴不相交的分割掩模与不可见的部分之间往往导致不太现实的图像。我们确保新粘贴的目标不会与任何现有目标重叠,并且距离图像边界至少五个像素。
在图4中,我们以图形方式说明了建议的增强策略,以及它如何在训练期间增加匹配Anchor的数量,从而更好地检测小目标。
实验

当粘贴一个小目标的副本时,有两件事要考虑。首先,我们必须确定粘贴的目标是否与任何其他目标重叠。虽然我们选择不引入任何重叠,但我们通过实验验证它是否是一种好的策略。其次,是否执行附加步骤以平滑粘贴目标的边缘是设计的选择。我们实验了不同滤波器尺寸的高斯边界模糊是否比不进行进一步处理更有效。
Result and Analysis
Oversampling
通过在训练期间更频繁地对小目标图像进行采样(见表3),可以改进AP在小目标分割和检测方面的能力。通过3倍过采样观察到最大增益,这使小目标的AP增加了1%(对应于8.85%的相对改善)。虽然中等目标尺度上的性能受影响较小,但大目标检测和分割性能始终受到过采样的影响,这意味着必须根据小目标和大目标之间的相对重要性来选择比率。
Augmentation
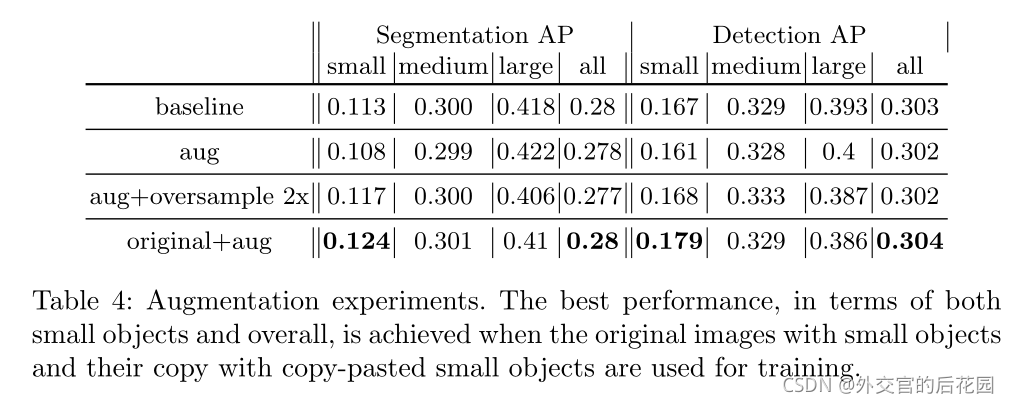
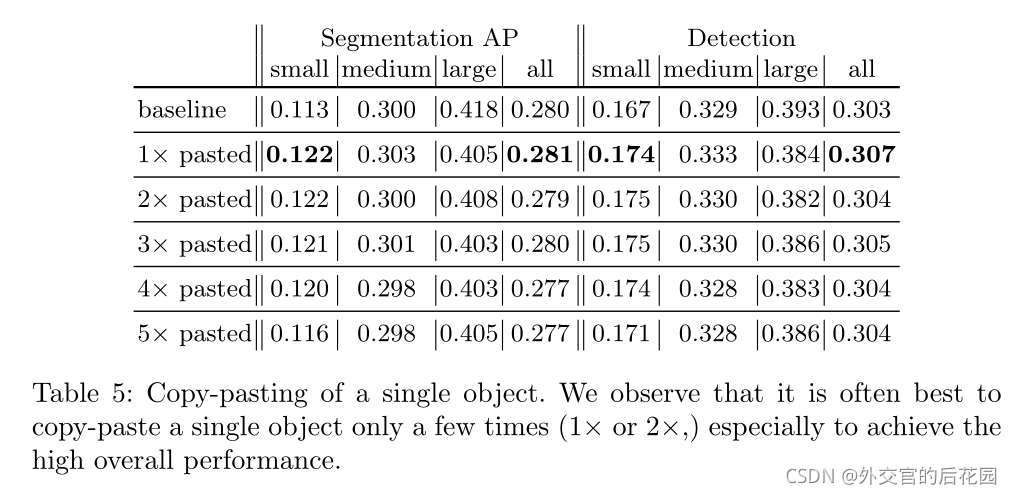
复制粘贴单个目标。我们观察到,通常最好只复制粘贴单个目标几次(1倍或2倍),尤其是为了获得较高的总体性能。
通过将过采样和增强相结合,以p=0.5(原始+aug)的概率实现最佳效果,原始与增强小目标的比率为2:1。此设置比单独过采样产生更好的结果,证实了所提出的粘贴小目标策略的有效性。
Copy-Pasting strategies
复制粘贴单个目标在表5中,我们可以看到,复制粘贴单个目标会在小目标上产生更好的模型,但是,在大图像上的性能下降很小。这些结果本身也比两次过采样好。
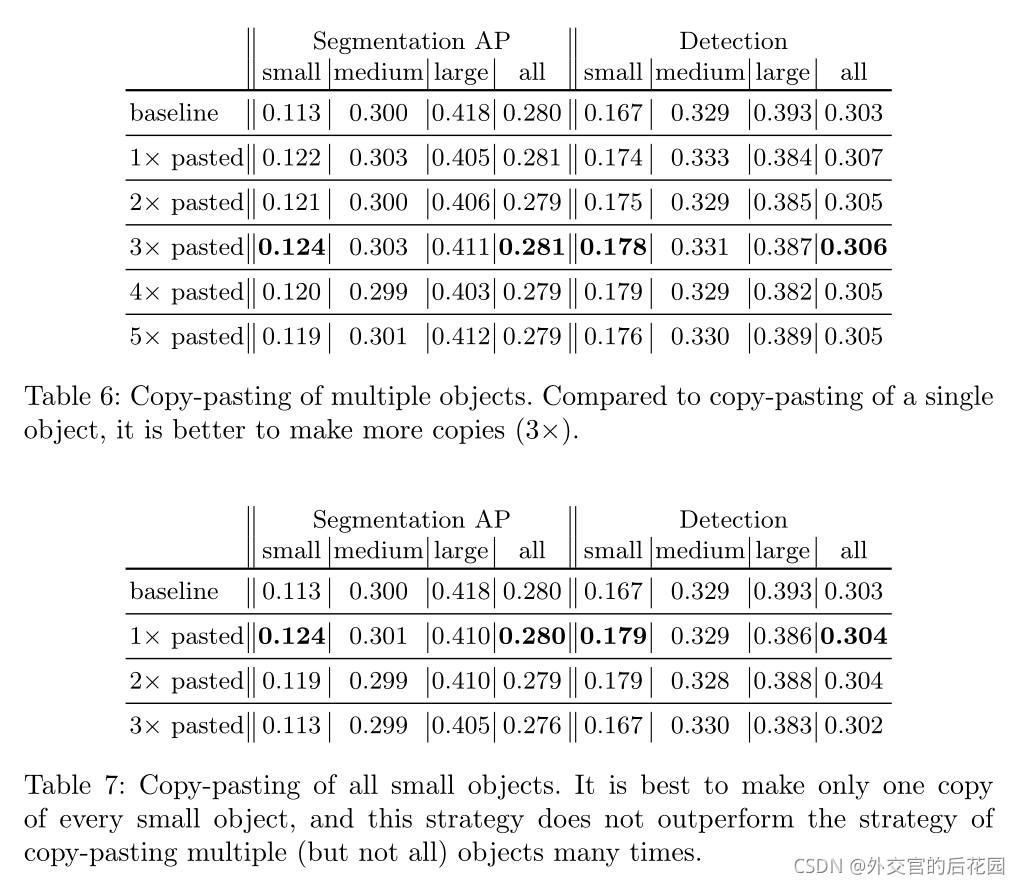
如表6所示,每个图像复制粘贴多个小目标比仅复制粘贴单个目标要好。在本例中,我们看到了每个目标最多粘贴三次的好处。
表7列出了复制粘贴每个图像中所有小目标的结果。我们发现,在一次增加所有目标时,分割和检测的结果都是最好的。我们怀疑这背后有两个可能的原因。首先,通过拥有所有小目标的多个副本,原始小目标与粘贴小目标的比率迅速降低。其次,每个图像中的目标数量会成倍增加,这会导致训练图像和测试图像之间更大的不匹配。
多次添加同一目标不会产生任何性能改进。
Pasting Algorithms
如表8所示,在不考虑其他目标已经占据区域的情况下,随机粘贴到图像中会导致小图像的性能较差。

不同粘贴算法的结果。我们观察到,在复制粘贴小目标时,不引入任何重叠是至关重要的,并且不建议对粘贴目标的边缘进行高斯模糊。
这证明我们的设计选择可以避免粘贴目标和现有目标之间的任何重叠。此外,粘贴目标边缘的高斯模糊并未显示出任何改善,这表明最好按原样粘贴目标,除非采用更复杂的融合策略。
Conclusion
我们研究了小目标检测问题。我们发现,小目标平均精度差的原因之一是在训练数据中缺乏小目标的表示。对于现有的最先进的目标检测器来说尤其如此,它需要有足够的目标,以便预测Anchor在训练期间匹配。为了克服这个问题,我们提出了两种策略来扩充原始的MS COCO数据库。首先,我们展示了通过在训练期间对包含小目标的图像进行过采样,可以轻松提高小目标的性能。其次,提出了一种基于复制粘贴小目标的增广算法。我们的实验证明,与Mask R-CNN在MS COCO上获得的最新技术相比,小目标的实例分割和目标检测的相对改善率分别为9.7%和7.1%。正如实验所证实的,所提出的一组增强方法提供了小目标和大目标预测质量之间的折衷。
源码及实验
作者在原论文并没有给出源码地址,待更新。。。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









