






系列文章目录
前言
我们知道目标检测数据集中数据和标签需要一一对应,一旦对图像数据做了增强处理后(目标bbox发生改变),标签也需要做相应的修改。
比较work的数据增强方法:
Mosaic
MixUp
Resize
LetterBox
RandomCrop
RandomFlip
RandomHSV
RandomBlur
RandomNoise
RandomAffine
RandomTranslation
Normalize
ImageToTensor
这些都是很容易就能嵌入到我们的训练框架中,下面介绍一种比较有用的方法,对小目标和目标背景缺乏的场景下涨点明显。也是一种解决样本少,不均衡的方法。
一、增强效果
GitHub:Detection_Augmentation
如下图,图片只含有一个目标,我们可以将另外一张图里的目标扣下来,贴到这一张图上去,熟悉目标检测的都知道当我们训练业务场景的数据时,这样增强对模型的泛化能力的提升是很积极的, 下面具体讲解如何实现。
label:1 0.5751 0.3541666666666667 0.28125 0.38

下图是将目标贴到原图里,并且label文件也保持下来了,第二行开始为新增的三个目标。
1 0.571875 0.35 0.28125 0.38
1 0.2 0.15 0.1875 0.25
2 0.875 0.4666666666666667 0.1875 0.25
3 0.51875 0.775 0.1875 0.25

二、方法讲解
此方法是在yolo标签格式下完成的,如果你们的数据标签是VOC或coco格式,需先转换成yolo格式,增强之后在转回来。
1. 原图数据
待增强的图像和标签文件
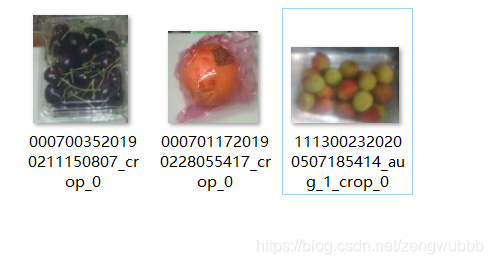
2. 截取目标roi
python crop_image.py # 根据bbox截取目标roi,并保存图片
3. 运行demo.py
import os
import random
from os.path import join
import aug
import Helpers as hp
from util import *
# ###########Pipeline##############
"""
1 准备数据集和yolo格式标签, 如果自己的数据集是voc或coco格式的,先转换成yolo格式,增强后在转回来
2 run crop_image.py 裁剪出目标并保存图片
3 run demo.py 随机将裁剪出目标图片贴到需要增强的数据集上,并且保存增强后的图片集和label文件
"""
base_dir = os.getcwd()
save_base_dir = join(base_dir, 'save_path')
check_dir(save_base_dir)
# imgs_dir = [f.strip() for f in open(join(base_dir, 'sea.txt')).readlines()]
imgs_dir = [os.path.join('fruit', f) for f in os.listdir('fruit') if f.endswith('jpg')]
labels_dir = hp.replace_labels(imgs_dir)
# print(imgs_dir, '\n', labels_dir)
# small_imgs_dir = [f.strip() for f in open(join(base_dir, 'dpj_small.txt')).readlines()]
small_imgs_dir = [os.path.join('fruit_image', f) for f in os.listdir('fruit_image') if f.endswith('jpg')]
random.shuffle(small_imgs_dir) # 目标图片打乱
# print(small_imgs_dir)
times = 3 # 随机选择增加多少个目标
for image_dir, label_dir in zip(imgs_dir, labels_dir):
# print(image_dir, label_dir)
small_img = []
for x in range(times):
if small_imgs_dir == []:
small_imgs_dir = [os.path.join('fruit_image', f) for f in os.listdir('fruit_image') if f.endswith('jpg')]
random.shuffle(small_imgs_dir)
small_img.append(small_imgs_dir.pop())
# print("ok")
aug.copysmallobjects(image_dir, label_dir, save_base_dir, small_img, times)
aug.py
new_bboxes = random_add_patches(roi.shape, # 此函数roi目标贴到原图像上,返回的bbox为roi在原图上的bbox,
rescale_labels, # 并且bbox不会挡住图片上原有的目标
image.shape,
paste_number=1, # 将该roi目标复制几次并贴到到原图上
iou_thresh=0) # iou_thresh 原图上的bbox和贴上去的roi的bbox的阈值
当paste_number=1时是第二幅图的结果,当paste_number=2时每个roi目标会复制两张,随机贴在原图上,iou_thresh可以设置目标之间的交并比,,如下图;

Mixup
此为博客取图,仅作效果展示,运行以下代码可生成下图和对应的label文件


import cv2
import os
import random
import numpy as np
import xml.etree.ElementTree as ET
import xml.dom.minidom
img_path = 'image/' # 原始图片文件夹路径
save_path = 'mixup/' # mixup的图片文件夹路径
xml_path = 'xml/' # 原始图片对应的标注文件xml文件夹的路径
save_xml = 'mixup_xml/' # mixup的图片对应的标注文件xml的文件夹路径
img_names = os.listdir(img_path)
img_num = len(img_names)
print('img_num:', img_num)
for imgname in img_names:
imgpath = img_path + imgname
if not imgpath.endswith('jpg'):
continue
img = cv2.imread(imgpath)
img_h, img_w = img.shape[0], img.shape[1]
print(img_h,img_w)
i = random.randint(0, img_num - 1)
print('i:', i)
add_path = img_path + img_names[i]
addimg = cv2.imread(add_path)
add_h, add_w = addimg.shape[0], addimg.shape[1]
if add_h != img_h or add_w != img_w:
print('resize!')
addimg = cv2.resize(addimg, (img_w, img_h), interpolation=cv2.INTER_LINEAR)
scale_h, scale_w = img_h / add_h, img_w / add_w
lam = np.random.beta(1.5, 1.5)
print(lam)
mixed_img = lam * img + (1 - lam) * addimg
save_img = save_path + imgname[:-4] + '_3.jpg'
cv2.imwrite(save_img, mixed_img)
print(save_img)
print(imgname, img_names[i])
if imgname != img_names[i]:
xmlfile1 = xml_path + imgname[:-4] + '.xml'
xmlfile2 = xml_path + img_names[i][:-4] + '.xml'
print(xmlfile1,xmlfile2)
tree1 = ET.parse(xmlfile1)
tree2 = ET.parse(xmlfile2)
doc = xml.dom.minidom.Document()
root = doc.createElement("annotation")
doc.appendChild(root)
for folds in tree1.findall("folder"):
folder = doc.createElement("folder")
folder.appendChild(doc.createTextNode(str(folds.text)))
root.appendChild(folder)
for filenames in tree1.findall("filename"):
filename = doc.createElement("filename")
filename.appendChild(doc.createTextNode(str(filenames.text)))
root.appendChild(filename)
for paths in tree1.findall("path"):
path = doc.createElement("path")
path.appendChild(doc.createTextNode(str(paths.text)))
root.appendChild(path)
for sources in tree1.findall("source"):
source = doc.createElement("source")
database = doc.createElement("database")
database.appendChild(doc.createTextNode(str("Unknow")))
source.appendChild(database)
root.appendChild(source)
for sizes in tree1.findall("size"):
size = doc.createElement("size")
width = doc.createElement("width")
height = doc.createElement("height")
depth = doc.createElement("depth")
width.appendChild(doc.createTextNode(str(img_w)))
height.appendChild(doc.createTextNode(str(img_h)))
depth.appendChild(doc.createTextNode(str(3)))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
root.appendChild(size)
nodeframe = doc.createElement("frame")
nodeframe.appendChild(doc.createTextNode(imgname[:-4] + '_3'))
objects = []
for obj in tree1.findall("object"):
obj_struct = {}
obj_struct["name"] = obj.find("name").text
obj_struct["pose"] = obj.find("pose").text
obj_struct["truncated"] = obj.find("truncated").text
obj_struct["difficult"] = obj.find("difficult").text
bbox = obj.find("bndbox")
obj_struct["bbox"] = [int(bbox.find("xmin").text),
int(bbox.find("ymin").text),
int(bbox.find("xmax").text),
int(bbox.find("ymax").text)]
objects.append(obj_struct)
for obj in tree2.findall("object"):
obj_struct = {}
obj_struct["name"] = obj.find("name").text
obj_struct["pose"] = obj.find("pose").text
obj_struct["truncated"] = obj.find("truncated").text
obj_struct["difficult"] = obj.find("difficult").text # 有的版本的labelImg改参数为小写difficult
bbox = obj.find("bndbox")
obj_struct["bbox"] = [int(int(bbox.find("xmin").text) * scale_w),
int(int(bbox.find("ymin").text) * scale_h),
int(int(bbox.find("xmax").text) * scale_w),
int(int(bbox.find("ymax").text) * scale_h)]
objects.append(obj_struct)
for obj in objects:
nodeobject = doc.createElement("object")
nodename = doc.createElement("name")
nodepose = doc.createElement("pose")
nodetruncated = doc.createElement("truncated")
nodedifficult = doc.createElement("difficult")
nodebndbox = doc.createElement("bndbox")
nodexmin = doc.createElement("xmin")
nodeymin = doc.createElement("ymin")
nodexmax = doc.createElement("xmax")
nodeymax = doc.createElement("ymax")
nodename.appendChild(doc.createTextNode(obj["name"]))
nodepose.appendChild(doc.createTextNode(obj["pose"]))
nodepose.appendChild(doc.createTextNode(obj["truncated"]))
nodedifficult.appendChild(doc.createTextNode(obj["difficult"]))
nodexmin.appendChild(doc.createTextNode(str(obj["bbox"][0])))
nodeymin.appendChild(doc.createTextNode(str(obj["bbox"][1])))
nodexmax.appendChild(doc.createTextNode(str(obj["bbox"][2])))
nodeymax.appendChild(doc.createTextNode(str(obj["bbox"][3])))
nodebndbox.appendChild(nodexmin)
nodebndbox.appendChild(nodeymin)
nodebndbox.appendChild(nodexmax)
nodebndbox.appendChild(nodeymax)
nodeobject.appendChild(nodename)
nodeobject.appendChild(nodepose)
nodeobject.appendChild(nodetruncated)
nodeobject.appendChild(nodedifficult)
nodeobject.appendChild(nodebndbox)
root.appendChild(nodeobject)
fp = open(save_xml + imgname[:-4] + "_3.xml", "w")
doc.writexml(fp, indent='\t', addindent='\t', newl='\n', encoding="utf-8")
fp.close()
else:
xmlfile1 = xml_path + imgname[:-4] + '.xml'
print(xmlfile1)
tree1 = ET.parse(xmlfile1)
doc = xml.dom.minidom.Document()
root = doc.createElement("annotation")
doc.appendChild(root)
for folds in tree1.findall("folder"):
folder=doc.createElement("folder")
folder.appendChild(doc.createTextNode(str(folds.text)))
root.appendChild(folder)
for filenames in tree1.findall("filename"):
filename=doc.createElement("filename")
filename.appendChild(doc.createTextNode(str(filenames.text)))
root.appendChild(filename)
for paths in tree1.findall("path"):
path = doc.createElement("path")
path.appendChild(doc.createTextNode(str(paths.text)))
root.appendChild(path)
for sources in tree1.findall("source"):
source = doc.createElement("source")
database = doc.createElement("database")
database.appendChild(doc.createTextNode(str("Unknow")))
source.appendChild(database)
root.appendChild(source)
for sizes in tree1.findall("size"):
size = doc.createElement("size")
width = doc.createElement("width")
height = doc.createElement("height")
depth = doc.createElement("depth")
width.appendChild(doc.createTextNode(str(img_w)))
height.appendChild(doc.createTextNode(str(img_h)))
depth.appendChild(doc.createTextNode(str(3)))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
root.appendChild(size)
nodeframe = doc.createElement("frame")
nodeframe.appendChild(doc.createTextNode(imgname[:-4] + '_3'))
objects = []
for obj in tree1.findall("object"):
obj_struct = {}
obj_struct["name"] = obj.find("name").text
obj_struct["pose"] = obj.find("pose").text
obj_struct["truncated"] = obj.find("truncated").text
obj_struct["difficult"] = obj.find("difficult").text
bbox = obj.find("bndbox")
obj_struct["bbox"] = [int(bbox.find("xmin").text),
int(bbox.find("ymin").text),
int(bbox.find("xmax").text),
int(bbox.find("ymax").text)]
objects.append(obj_struct)
for obj in objects:
nodeobject = doc.createElement("object")
nodename = doc.createElement("name")
nodepose = doc.createElement("pose")
nodetruncated = doc.createElement("truncated")
nodedifficult = doc.createElement("difficult")
nodebndbox = doc.createElement("bndbox")
nodexmin = doc.createElement("xmin")
nodeymin = doc.createElement("ymin")
nodexmax = doc.createElement("xmax")
nodeymax = doc.createElement("ymax")
nodename.appendChild(doc.createTextNode(obj["name"]))
nodepose.appendChild(doc.createTextNode(obj["pose"]))
nodetruncated.appendChild(doc.createTextNode(obj["truncated"]))
nodedifficult.appendChild(doc.createTextNode(obj["difficult"]))
nodexmin.appendChild(doc.createTextNode(str(obj["bbox"][0])))
nodeymin.appendChild(doc.createTextNode(str(obj["bbox"][1])))
nodexmax.appendChild(doc.createTextNode(str(obj["bbox"][2])))
nodeymax.appendChild(doc.createTextNode(str(obj["bbox"][3])))
nodebndbox.appendChild(nodexmin)
nodebndbox.appendChild(nodeymin)
nodebndbox.appendChild(nodexmax)
nodebndbox.appendChild(nodeymax)
nodeobject.appendChild(nodename)
nodeobject.appendChild(nodepose)
nodeobject.appendChild(nodetruncated)
nodeobject.appendChild(nodedifficult)
nodeobject.appendChild(nodebndbox)
root.appendChild(nodeobject)
fp = open(save_xml + imgname[:-4] + "_3.xml", "w")
doc.writexml(fp, indent='\t', addindent='\t', newl='\n', encoding="utf-8")
fp.close()
如需完整代码可联系我。

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









