







文章目录
Q-learning


Sarsa


Sarsa(λ)



Deep Q Network

Nature DQN

当状态空间比较小的情况下用 q learning 还是可以的,但是在复杂的情况下,例如一个视频游戏,它的状态空间非常大,如果迭代地计算每一个 q 值是非常耗费时间耗费资源的。
这个时候我们就想不是直接的用迭代的方式去计算扣只,而是找到一个最优的 q 函数。
找这个最优的q函数的方法就是用神经网络。
我们用一个深度神经网络来为每一组状态行为估计它们的 q 值,进而近似的估计出最优的 q 函数。
将 Q learning 和深度神经网络相结合就是 DQN


Double DQN

简单来说,DDQN通过解耦目标Q值动作的选择和目标Q值的计算这两步,来达到消除过度估计的问题

Prioritized Experience Replay (DQN)

DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差。今天我们在DDQN的基础上,对经验回放部分的逻辑做优化。对应的算法是Prioritized Replay DQN。

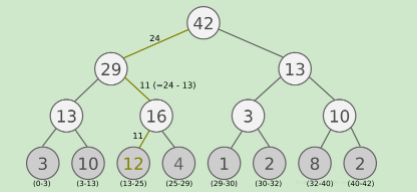


这个博客讲的特别好:https://www.cnblogs.com/pinard/p/9797695.html
Dueling DQN
前面讲到的DDQN中,我们通过优化目标Q值的计算来优化算法,在Prioritized Replay DQN中,我们通过优化经验回放池按权重采样来优化算法。而在Dueling DQN中,我们尝试通过优化神经网络的结构来优化算法。



感谢大佬!!!https://www.cnblogs.com/pinard/category/1254674.html 啃完他的这些文章!!绝对有用!!!太赞了!!!

















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









