







1、AI 编译器
TPU,张量处理器
AI编译器,把不同框架下的搭建起来的模型,转换为统一形式的中间表达 IR,然后通过 IR 转换成可以在特定芯片平台上运行的二进制模型
Top,芯片无关层:图优化、量化、推理
Tpu,芯片相关层,权重重排、算子切分、地址分配、推理
2、TPU-MLIR
- 算子按照顺序一一对应进行转换:onnx --> origin.mlir
- 图优化:origin.mlir --> canonical.mlir
- F32/BF16 lowering: canonical.mlir --> tpu.mlir
- 多层优化操作,权重重排,网络切分:tpu.mlir --> model.bmodel
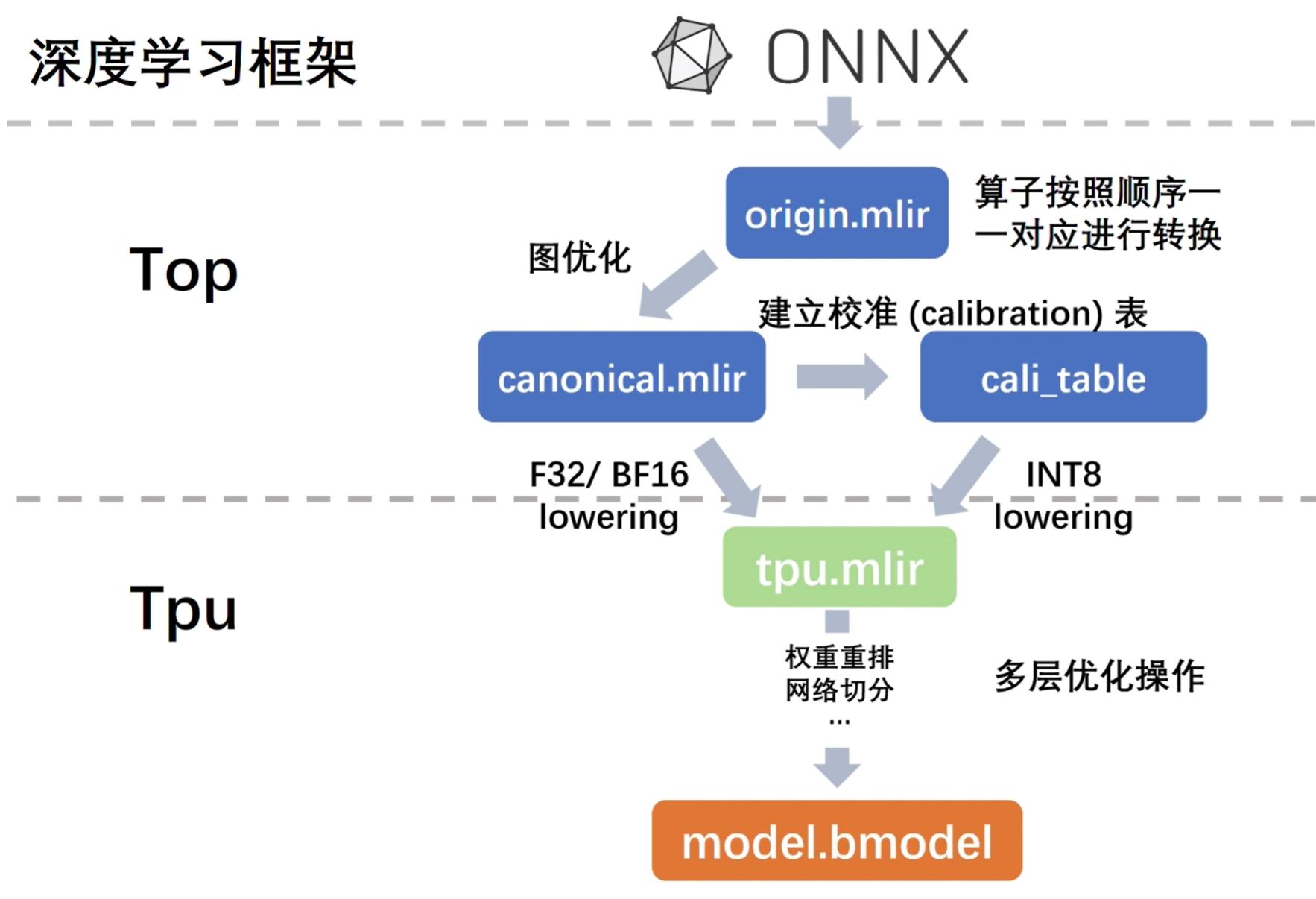
在模型转换过程中,会在各个阶段进行模型推理,并对比结果,以确保转换的正确性,量化过程会产生偏差
3、MLIR 语法介绍
LLVM 下的子项目,自带 Tensor 类型
在深度学习中,IR 可以理解为深度学习模型的一个中间表达形式
对于越高级的 IR,就越接近源代码,提取源代码意图的难度就越低,但是针对特定硬件优化代码的的难度就越高;对于越低级的 IR,这两点相反
由于 IR 的跨度越大,转换的开销就越大,因此需要多层中间表达。从统一通用的 IR,逐步抽象为针对特定硬件的 IR,最后针对目标生成特定的二进制文件
value,type,attract,operation
基于 ODS 框架进行 OP 定义,TableGen
4、TPU-MLIR 前端转换
原模型转换为 top 模型
前端转换工作流程:
前提 --> 输入 --> 初始化 converter --> 生成 MLIR 文本 --> 输出
在初始化 converter 步骤中,提取的主要信息:模型输入、输出名称,算子输出形状,算子权重等
生成 MLIR 文本:把相关信息逐一插入
5、dialect conversion
把一系列在目标 dialect 上非法的算子转换为合法算子
mlir 既支持部分转化,也支持全转换
6、lowering in TPU-MLIR
lowering,芯片无关层转换为芯片相关层
top-to-tpu 基本过程:
- top 层 OP 成分为 f32 和 int8 两种,前者可以直接转换成 f32/f16/bf16 的 tpu 算子,也可以经过校准量化,转换成 int8 的 tpu 算子;而后者则只能转换成 int8 的 tpu 算子
针对不同的芯片,需要有不同的 patterns 实现和 pass 实现
7、量化概述
量化的动机
深度学习网路部署到硬件设备难度高的原因:
- 大量权重导致内存过大
- 深度学习模型计算量庞大
解决方案:
- 高性能专用芯片(例如 TPU)
- 模型压缩(例如 量化)
量化的本质
本质:将权重与激活值,由 32 位的浮点型的范围很大的数值,映射到由低位固定点表示的小范围内(如 INT8)
为什么可以这样呢:
- 低位的运算成本更低
- 低位数据的搬移效率更高
–> 推理效率提高
量化类型:
- 训练后量化:直接对预训练过的模型进行量化操作,无需或者仅需少量的 data,易于实现
- 量化感知训练:在训练过程中模拟量化重新训练模型,需要带标签的数据,量化后更接近 F32 模型的精度
量化方案:
- 均匀量化
- 对称量化
- 有符号
- 无符号
- 非对称量化
- 对称量化
- 量化颗粒度的考虑
量化推导
r = S ( q − Z ) r =S(q - Z) r=S(q−Z)

量化校准
min/max, KLD
量化感知训练
-
训练后量化:轻量化 + 提高效率,但是会降低精度
- 精度下降原因:量化误差,截断误差,multiplier 和 shift 代替 scale也会有误差
-
量化感知训练优势:缓和量化造成的精度下降的问题,达成更低位的量化(INT4)
-
量化感知训练实现方式:
-
插入 FakeQuant 算子,将 weight 和 activation 量化成低位精度再反量化回 FP32 引入量化误差
-
量化参数
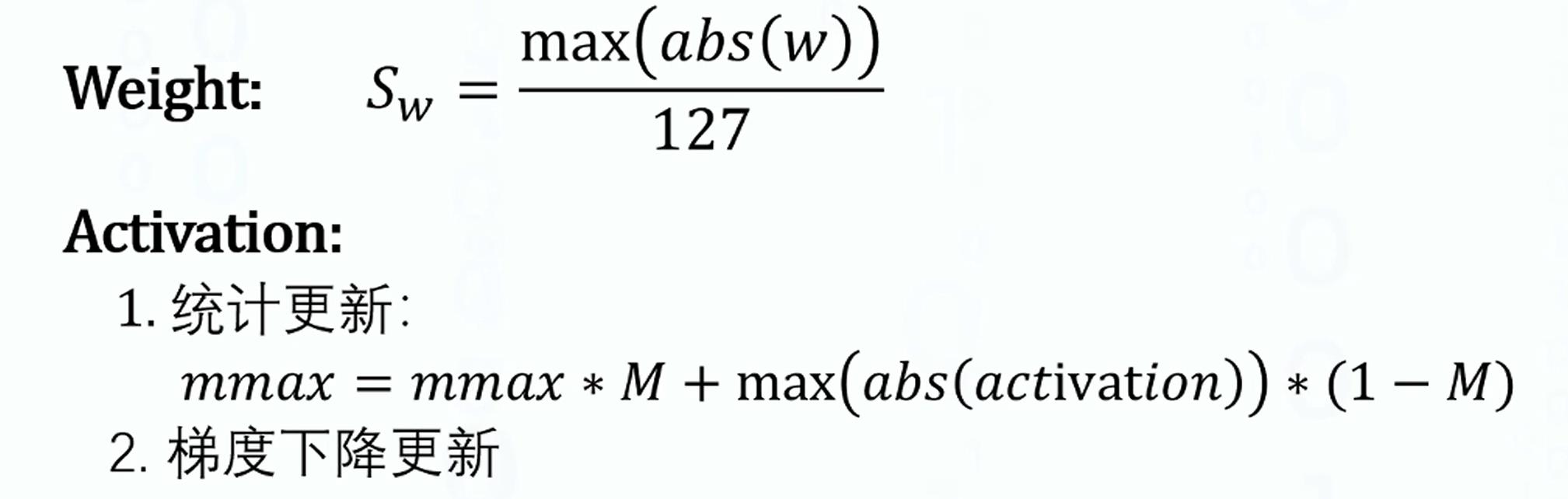
-
-
伪量化算子梯度:离散阶梯函数,不可导 --> QAT 算法
-
QAT特点:
- 优势:缓和量化造成的精度下降问题;达成更低位i的量化
- 劣势:重训练的开销
8、精度验证
model_eval.py
预处理信息包含在 mlir 中
9、pattern rewriting
dag to dag transformation(dag,有向无环图)
- pattern definition
- pattern rewriter
- pattern application
整体逻辑:不断地去循环尝试匹配 patterns,然后 rewrite,当没有任何的 patterns 被匹配成功,或者循环的次数超过最大值的时候,就结束调用
9、TPU-MLIR 模型适配
10、TPU-MLIR 图优化
图优化是工具链的重要性能优化手段
指令发射 --> 读数据 --> 运算 --> 写数据
图优化实现:
- 算子融合,减少 指令发射、读数据、写数据等的时间
- 算子融合实现:BN,scale 融合进 conv
- BN 转换成 scale
- 多个 scale 转换成一个新的 scale
- conv 和 scale 的融合
- 算子融合实现:BN,scale 融合进 conv


















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









