







前言
今天开始整理讲解Product-based Neural Network(PNN)模型,前面讲解的AutoRec和Deep Crossing模型是在神经网络的复杂度和层数方面进行的进化,而这两个模型也是使用深度学习从用户和物品相似度的角度来进行系统推荐的。其中对AutoRec和DeepCrossing这两个模型有些遗忘的小伙伴可以看看我这篇文章,推荐算法之AutoRec与Deep Crossing模型,但是这两个模型在特征交叉这个方面并没有进行很合理的设计,更多的是使用了全连接层来增加了模型的复杂度和使得所有特征进行了一个统一的交叉。这样存在着很大的问题,即两个毫不相关的特征也较交叉在了一起,这就使得对模型权重有所影响。所以为了更好地使两两特征更好的交叉,于是新加披国立大学在2017年提出了基于深度学习的协同过滤模型NeuralCF。我在前面也进行了讲解,文章推荐系统之NerualCF。但是NeuralCF也存在这很多问题,比如这个模型是基于协同过滤的思想来构造的,所以在这个模型中并没有引入更多的其它类型的特征,这在实际应用中也是浪费了很多的有用信息。所以PNN模型是在加入多组特征的基础上研究的特征交叉, 这个模型和Deep Crossing模型的架构类似, 只不过把Deep Crossing的stacking层换成了Product层, 也就是不同特征的embedding向量不再是简单的堆叠, 而是两两交互, 更有针对性的获取特征之间的交叉信息。它们的演化关系依然拿书上的一张图片, 便于梳理关系脉络, 对知识有个宏观的把握:

一、PNN模型简介
PNN是2016年上海交大团队在ICDM会议上提出的一个模型。模型的结构类似于DeepCrossing,先来看一下模型架构:
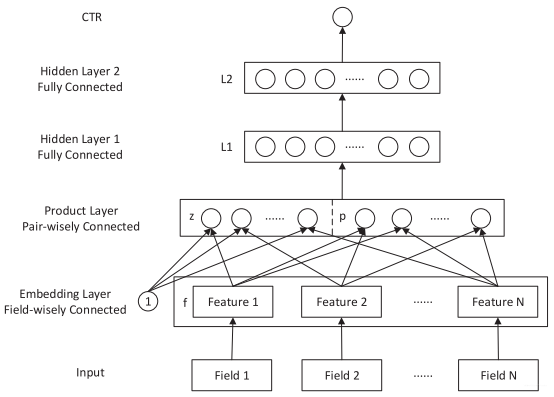
PNN模型在输入、Embedding层, 多层神经网络及最后的输出层与DeepCrossing并没有区别, 唯一的就是Stacking层换成了这里的Product层。 这主要是解决了DeepCrossing把所有特征进行了无差别交叉, 这就使得有一些毫不相关的特征进行了混杂。 所以PNN的解决方案就是设计了Product层, 专门进行特征之间的交叉的, 并且还提出了两种特征交叉的方式。所以接下来我们会着重将一些Product这一层。
二、数据embedding
对于embedding有很多种方式,这个后面也会专门写文章来进行总结,在这里也就是简单说一句,还是一句话,embedding就是使得稀疏向量变成稠密向量。如上图所示模型输入是由N个特征域组成,并且都是离散的分类特征,首先需要对其进行one-shot编码,但是在真正实现中是用一个LableEncoder编码,这就相当于为这一个特征域建立了一个字典,当要取这一个用户或者物品特征这一个特征域的时候,就可以直接读取字典来进行获取,然后进行embedding即可,embedding操作可以用下述公式简单来表示:
![]()
其中x是某一个用户包含多个特征域的输入特征向量,下标i代表此时要进行提取的这一特征域,W是embedding层的参数权重。但是前面也提过真正进行操作的时候,直接进行字典提取就可以,后续可以看代码细节。对于i的每一个特征值, 都是一个1 × M 的向量, 这里的M表示隐向量的维度。这里还要注意一个细节, 就是如果这些输入都是类别型特征, 那数值型的怎么办? 数值型特征不在这里了, 需要等类别型特征交叉完了之后, 再统一合并,细节也会在代码中体现。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









