







目录
第4章 隐马尔可夫模型与序列标注
4.1 序列标注问题
4.2 隐马尔可夫模型
4.3 隐马尔可夫模型的样本生成
4.4 隐马尔可夫模型的训练
4.5 隐马尔可夫模型的预测
4.6 隐马尔可夫模型应用于中文分词
4.7 性能评测
4.8 总结
第4章 隐马尔可夫模型与序列标注
比如这句话:
头上戴着束发嵌宝紫金冠,齐眉勒着二龙抢珠金抹额
加粗词语是现代入相对陌生的两个“新词”,但我们依然认识它们。当读者读到“戴着”时,心里就已经开始期待一个描述帽饰的名词了。另外,既然存在“披肩”这样的构词法,那么“抹额”的含义也就不难猜测了。人类不需要死记硬背整部词典,而拥有动态组词的能力,生搬硬套现代汉语词典的话,反而查不到这两个饰品词汇。 这说明词语级别的模型天然缺乏OOV召回能力,我们需要更细颗粒度的模型。比词语更细的颗粒就是字符,如果字符级模型能够掌握汉字组词的规律,那么它就能够由字构词、动态地识别新词汇,而不局限于词典了。 具体说来,只要将每个汉字组词时所处的位置(首尾等)作为标签,则中文分词就转化为给定汉字序列找出标签序列的问题。一般而言,由字构词是序列标注模型的一种应用。 在所有“序列标注”模型中,隐马尔可夫模型是最基础的一种。 本章先介绍序列标注问题的定义及应用,然后讲述并实现隐马尔可夫模型,最终将其应用到中文分词上去。
序列标注指的是给定一个序列x=x1x2…xn,找出序列中每个元素对应标签y=y1y2…yn的问题。其中y所有可能的取值集合称为标注集(tagset)。比如,输入一个自然数序列,输出它们的奇偶性,按顺序排列成另一个序列。此时标注集为{奇,偶},标注过程如图4-1所示。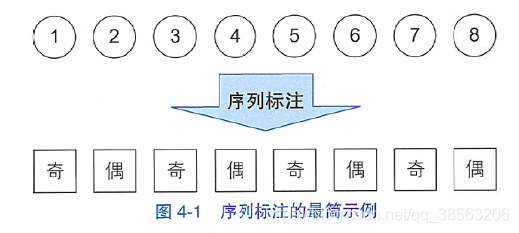 图4-1序列标注的最简示例
图4-1序列标注的最简示例
数字奇偶性的判断只取决于当前元素,这是最简单的情况。然而,大多数情况下,需要考虑前后元素以及之前的标签才能决定当前标签。比如扑克牌游戏“小猫钓鱼”中,双方轮流出牌,第一次出现相同牌时出牌人收走相同两张牌之间的所有牌。如果将出牌顺序记录为序列x,出牌后是否应当收牌作为标签序列y,那么游戏就转化为序列标注问题了,如图4-2所示。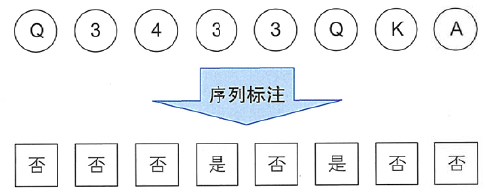 图4-2小猫钓鱼转化为序列标注问题
图4-2小猫钓鱼转化为序列标注问题
注意这三次出3时是否收牌的标签都不一样,因为根据游戏规则,只有第二次出3时桌上才有相同牌,而第三次出3时前两次的已经被收走了,所以第三次不会触发收牌。 求解序列标注问题的模型一般称为序列标注器(tagger),通常由模型从一个标注数据集{X,Y}={(xi,yi)},i=1,…,K中学习相关知识后再进行预测。在NLP问题中,x通常是字符或词语,而y则是待预测的组词角色或词性等标签。无论是第3章介绍的中文分词、第7章中的词性标注还是第8章中的命名实体识别,都可以转化为序列标注问题。
4.1.1 序列标注与中文分词
考虑一个字符序列(字符串)x,想象切词器真的是在拿刀切割字符串。那么每个字符xi,在分词时无非充当如下两种角色:要么在i之后切开,要么
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









