







数据读取部分
pytorch官方文档链接 :这里
Dataset
数据类,需要自己实现,后续需要传入torch.utils.data.DataLoader中
需要自己实现对数据的读取类myDataset,myDataset需要继承torch.utils.data.Dataset
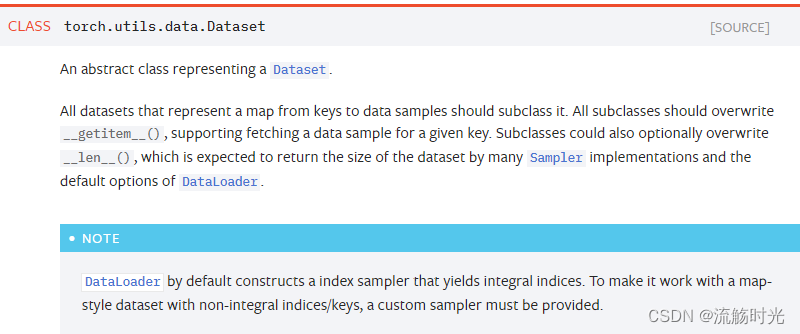
在myDataset中需要:
- 重写
__getitem__()方法,该函数声明形式为:def __getitem__(self,idx):,内部需要自行实现根据索引获取一个对应的数据- 输入:idx : 索引
- 输出:索引对应的数据,形式可以自己设定,如
(image,box,label),或者组织成一个类的形式等等
- 重写
__len__()方法,返回数据量的大小 - 其他可以根据自己需求添加辅助函数,例如随机打乱,数据增强,数据格式转换等等
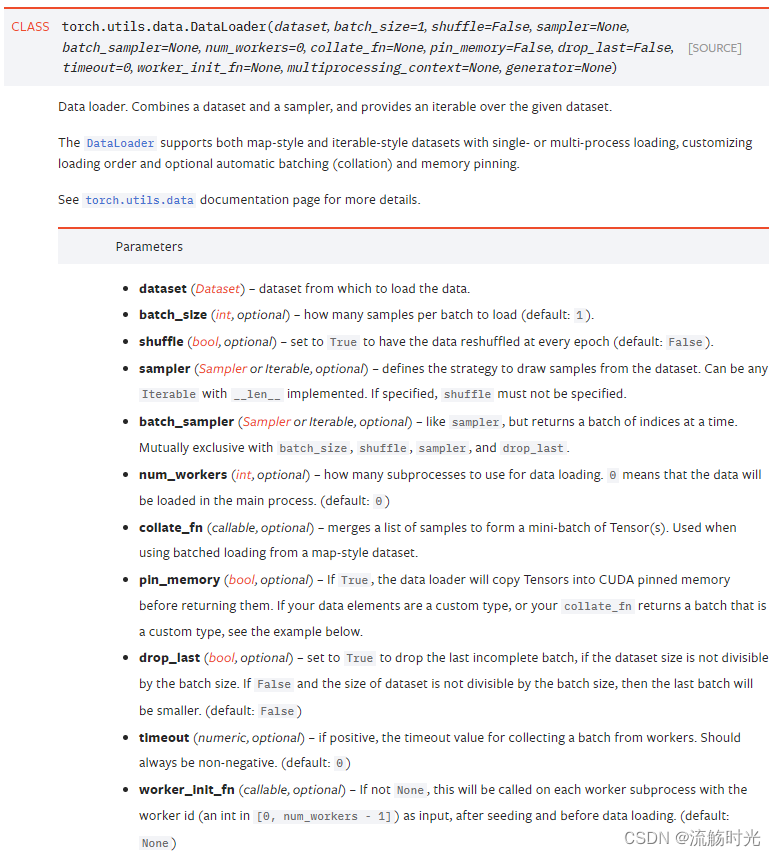
DataLoader
torch.utils.data.DataLoader
torch中提供的数据加载器,可以视为对用户自定义数据类的一层封装,以便于调用时形式能够统一一些
内部会根据参数将数据分成多个batch,每次通过迭代器送出一组数据(内部实现了__iter__(),即可以使用for循环进行遍历),并且里面还提供了多线程处理数据的选项
类的声明如下:
使用方法
from torch.utils.data import DataLoader
# 自己定义的数据类
trainDataset = myDataset(...)
# 调用DataLoader进行封装,参数按需设定
trainData = DataLoader(trainDataset,...)
# 遍历,根据自己在myDataset所设定的数据形式进行读取
for iteration,batchData in enumerate(trainData):
images,boxes,labels = batchData[0],batchData[1],batchData[2]
模型
根据自己的需求创建对应的网络模型类myModule,需要继承torch.nn.Module,同时在类的初始化函数__init__()中需要调用父类的初始化函数,即:
class myModule(nn.Module):
def __init__(self, ... ):
super(myModule,self).__init__()
# function body
# 各模块的定义
# 网络层的初始化等
def forward(self,x, ... ):
# 前向计算
# 模型实例化
model = myModule(...)
训练
优化器设置
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
损失函数设置
loss_func = nn.CrossEntropyLoss() # 损失函数的实例化,可以使用现成的,也可以按需进行修改为自己设计的损失函数
设备设置
os.environ["CUDA_VISIBLE_DEVICES"] = '1' # 本行代码必须在 import torch之前,否则设定无效
模型训练
# 迭代次数
max_epochs=100
for epoch in range(max_epochs):
for step, (x,label) in enumerate(dataloader):
optimizer.zero_grad() ##清零梯度
output= model(x) # 前向传播
loss = loss_func(output, label) # 计算损失
loss.backward() ##反向传播
optimizer.step() ##更新梯度参数
保存、加载模型
# 仅保存、加载参数
torch.save(model.state_dict(),'../model.pkl')
model.load_state_dict(torch.load('../model.pkl'))
#---------------------------------------------------------------------------------#
# 保存、加载整个模型和参数
torch.save(model,'../model.pkl')
model = torch.load('../model.pkl')
#---------------------------------------------------------------------------------#
# 多个模型参数保存
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)
# 模型参数加载
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
如有错误还请指正















 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









