







下面是
Relation with skip gram
skip gram:

接下来在整个corPus 中训练:

但在vast corpus 难以求所有的
Q
i
,
j
Q_{i,j}
Qi,j,采用近似


但对于两分布中的交叉熵损失是有弊端的:即低概率高权值
并且上式中的
Q
i
,
j
Q_{i,j}
Qi,j还是难以normalized,因此

不归一化带来的问题是
Q
h
a
t
,
P
h
a
t
Q_{hat},P_{hat}
Qhat,Phat很大,故采用以下对数形式
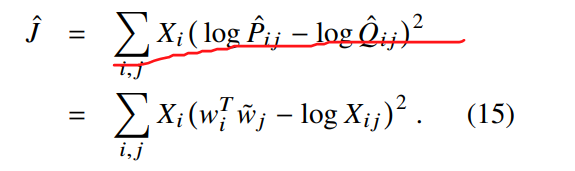
还是无法优化,因此,不再使用context word (
X
i
,
j
X_{i,j}
Xi,j)作为权重,改用
f
(
X
i
j
)
f(X_{ij})
f(Xij)
















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









