









MICCAI2022 Challenge: Glaucoma Oct Analysis and Layer Segmentation (GOALS)
MICCAI2022 Challenge: GOALS
GOALS比赛总结
比赛介绍
比赛背景Challenge Description
GOALS挑战赛是由百度在MICCAI 2022上举办的国际眼科赛事。MICCAI是由国际医学图像计算和计算机辅助干预协会 (Medical Image Computing and Computer Assisted Intervention Society) 举办的跨医学影像计算和计算机辅助介入两个领域的综合性学术会议,是该领域的顶级会议。与此同时,百度将在MICCAI 2022上组织第九届眼科医学影像分析研讨会Ophthalmic Medical Image Analysis (OMIA9)。
赛题背景Task Background
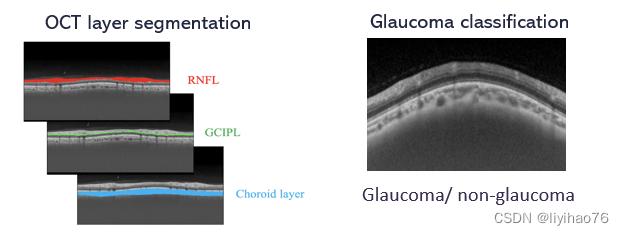
光学相干断层扫描(OCT)因其无接触、非侵入性的特点,已成为眼部疾病诊疗中的常规检查,可为医生提供视网膜结构图像。与只能提供视网膜表面信息的彩色眼底图像相比,OCT图像可以提供视网膜的横断面信息,因此可以更准确地分析视网膜结构。层的分割和厚度量化对许多视网膜和视神经疾病的诊断有帮助,例如青光眼、黄斑变性或糖尿病性视网膜病变。在青光眼的诊断中,使用OCT比使用眼底彩色图像更容易发现早期病例。因此,本次挑战赛围绕OCT图像设计了两个任务:
- 环扫OCT图像的层分割任务,以确定视网膜神经纤维层、神经节细胞丛层和脉络膜层,这有助于青光眼的诊断和区分;
- 青光眼的自动诊断任务。
赛程赛制Schedule setting

比赛结果
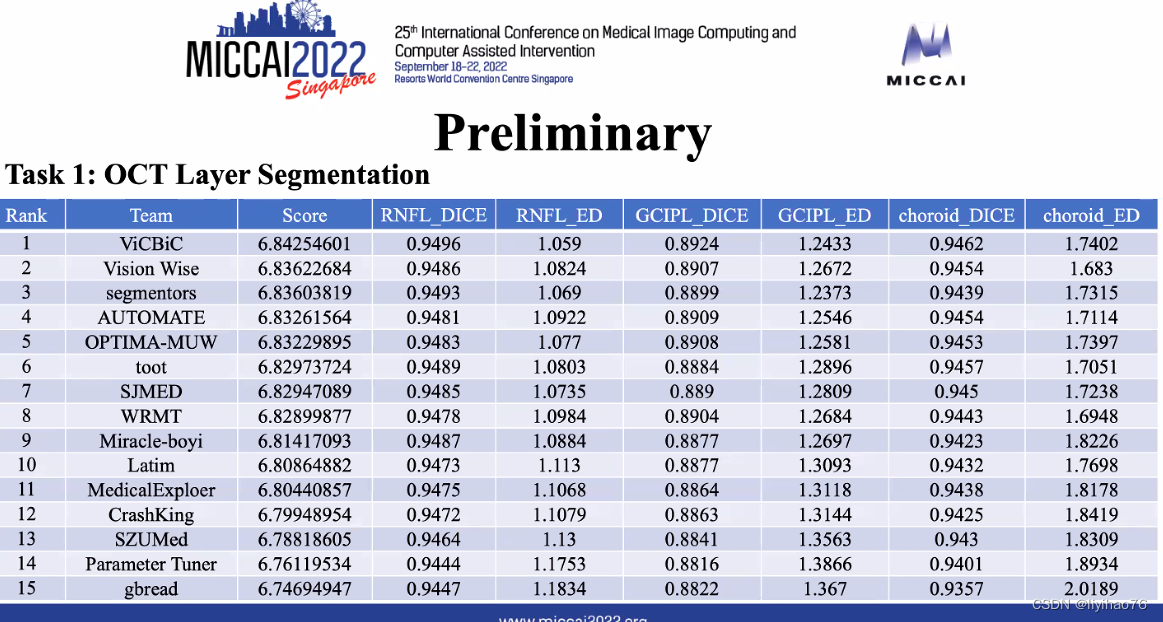
初赛结果-分割任务
初赛结果-分类任务

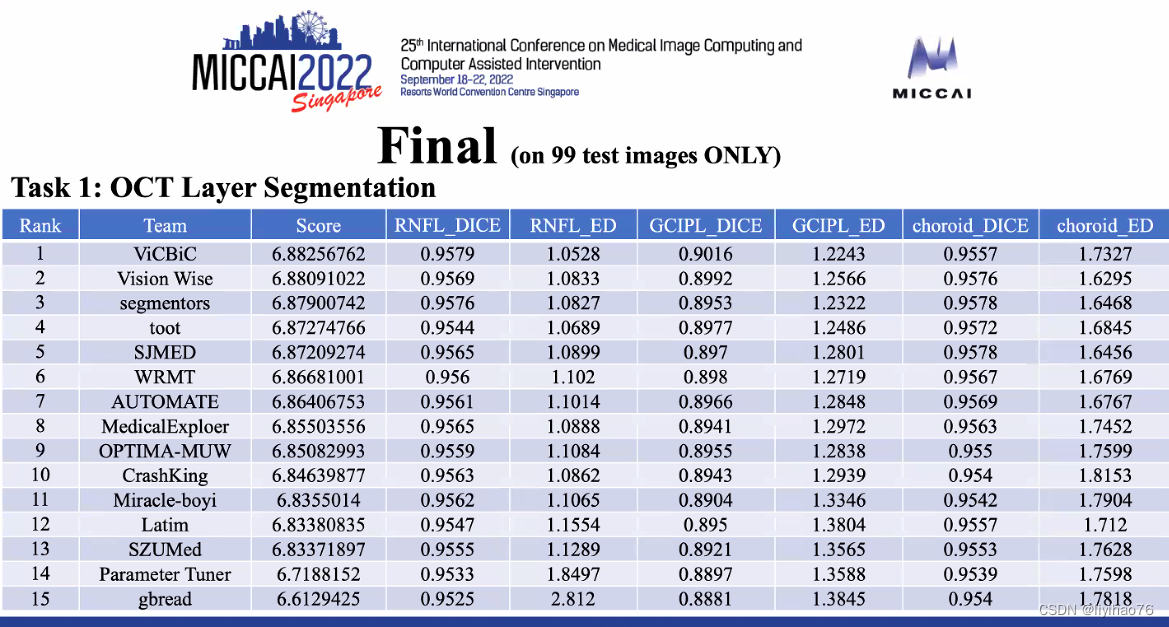
决赛结果-分割任务
决赛结果-分类任务

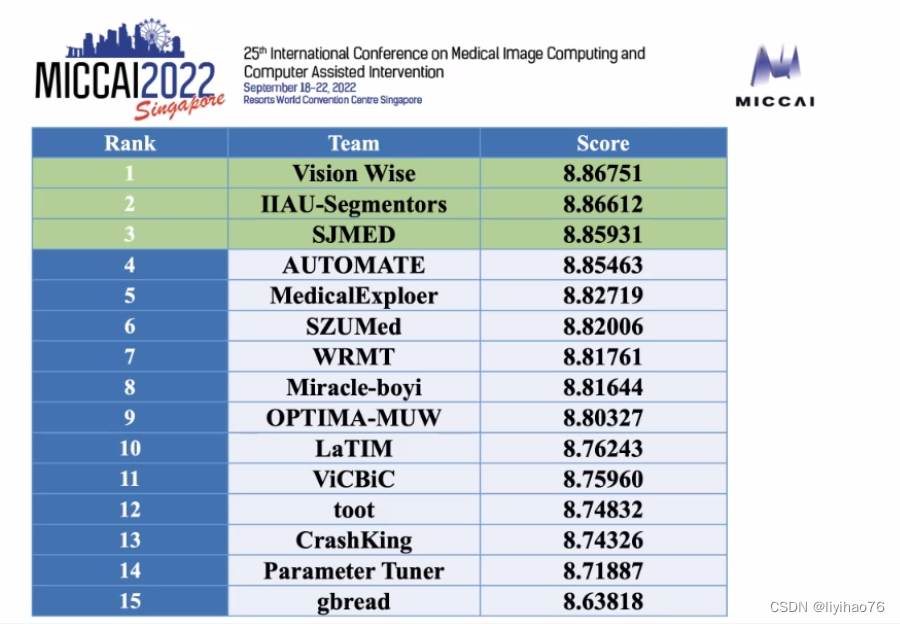
决赛结果-总分(结合两个任务)
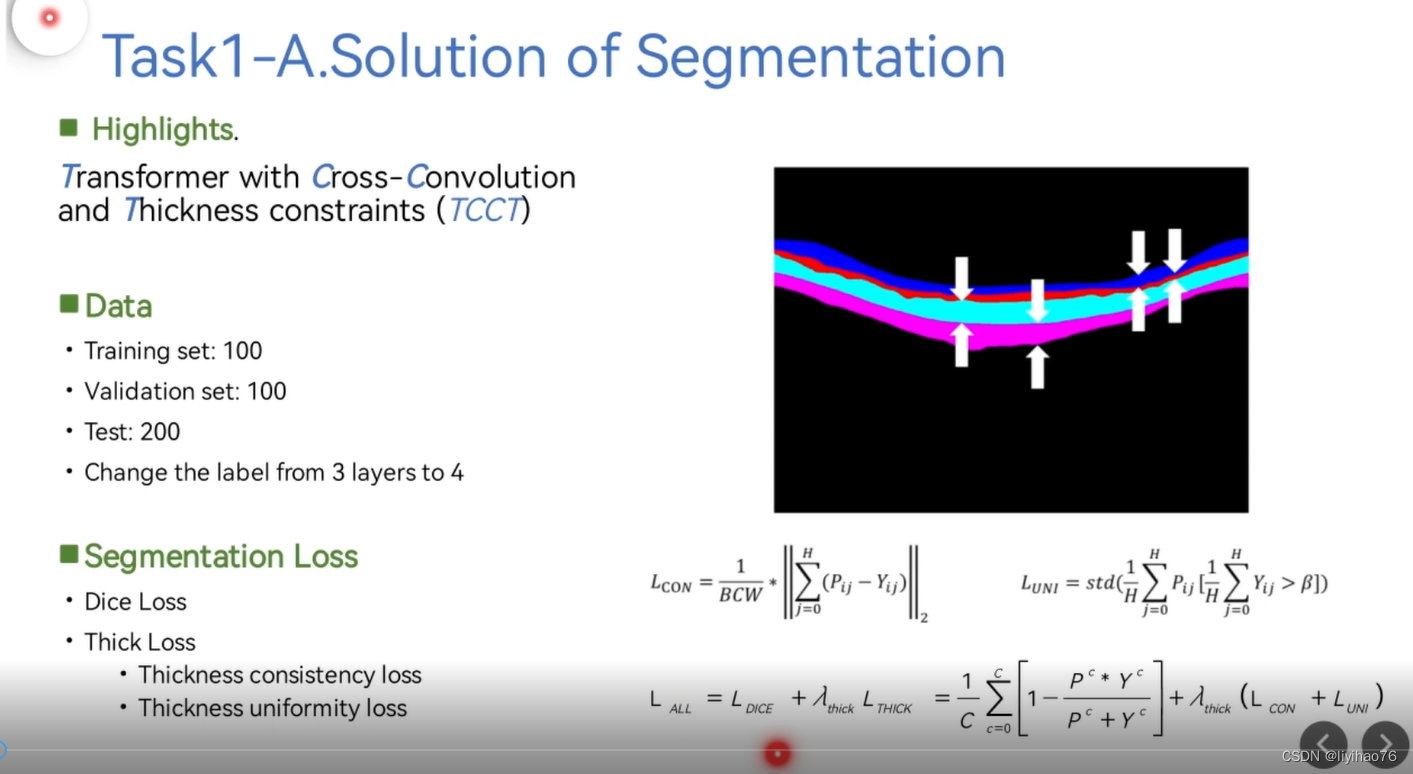
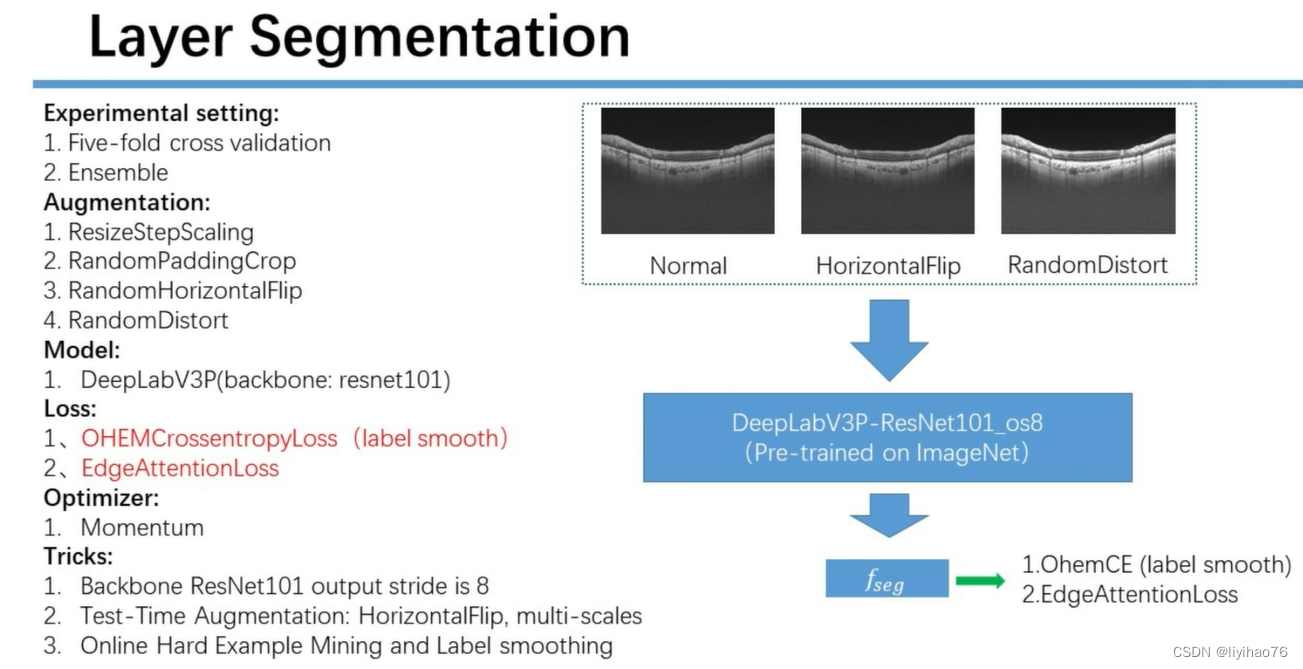
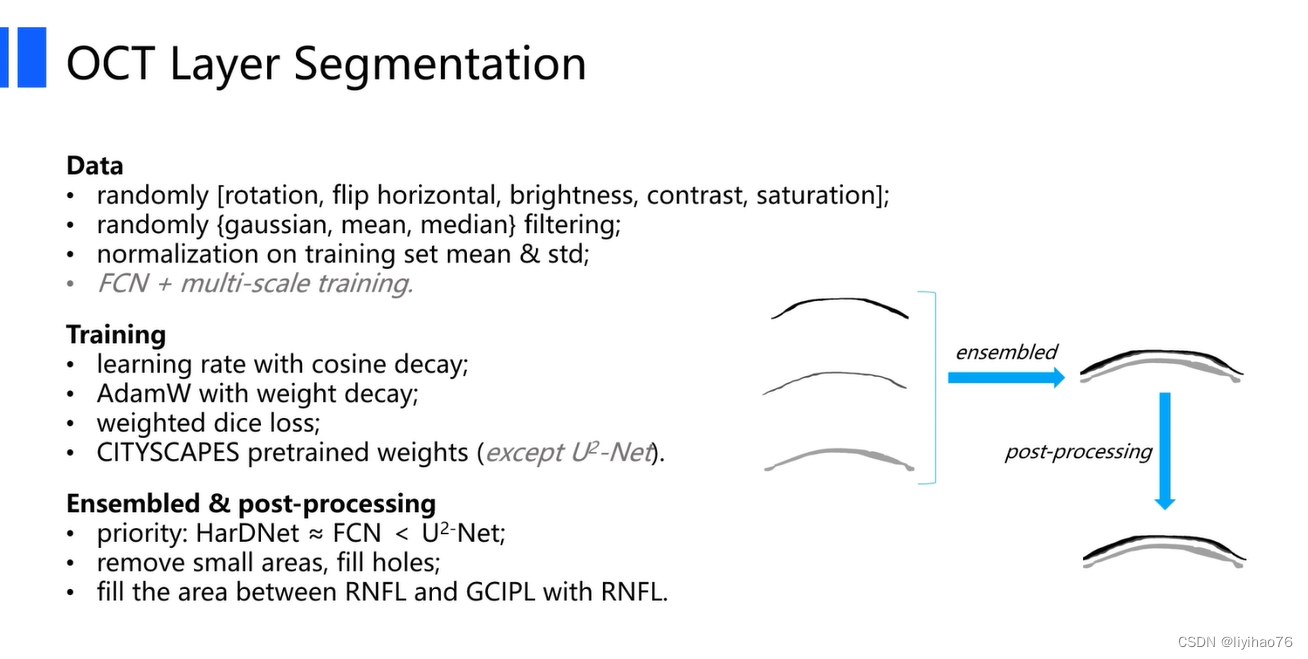
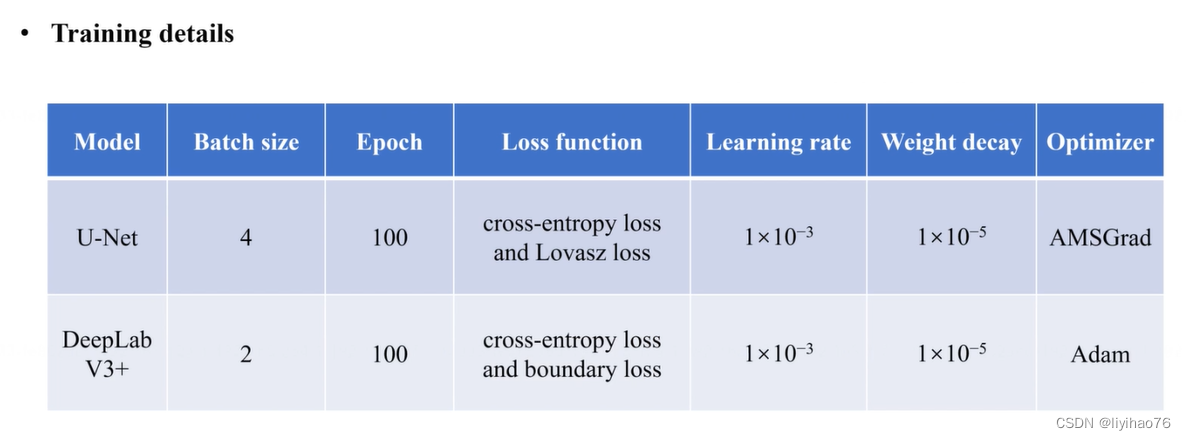
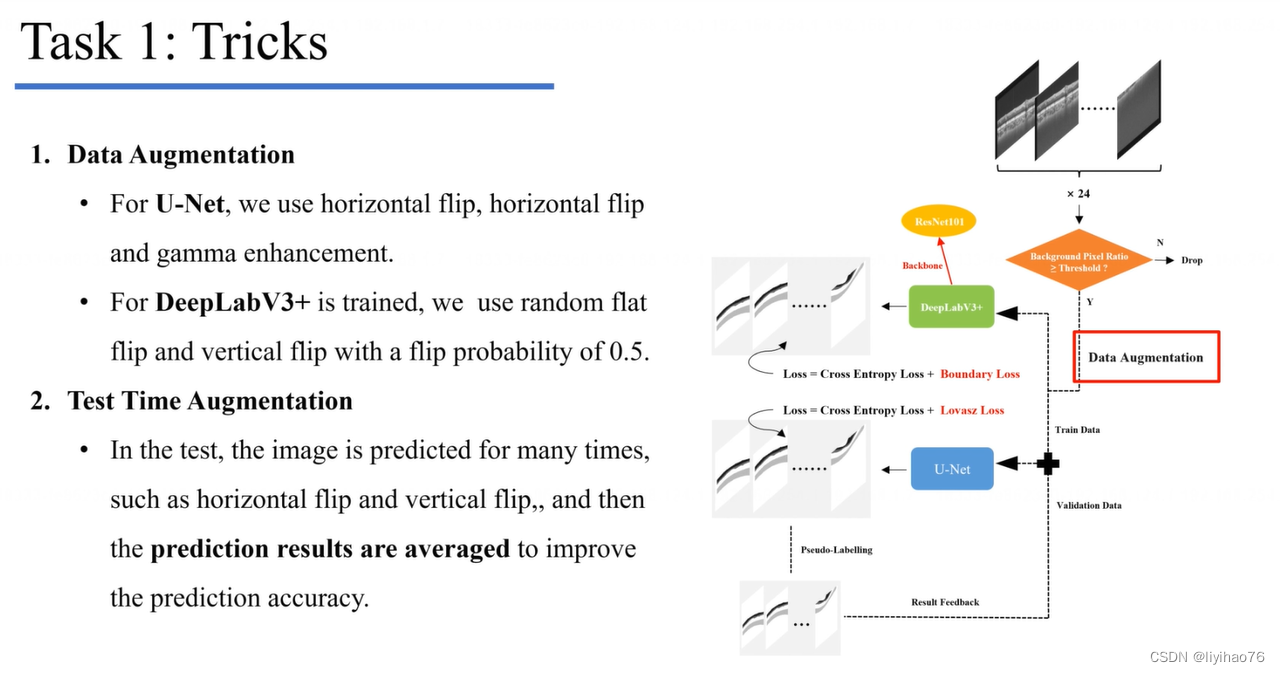
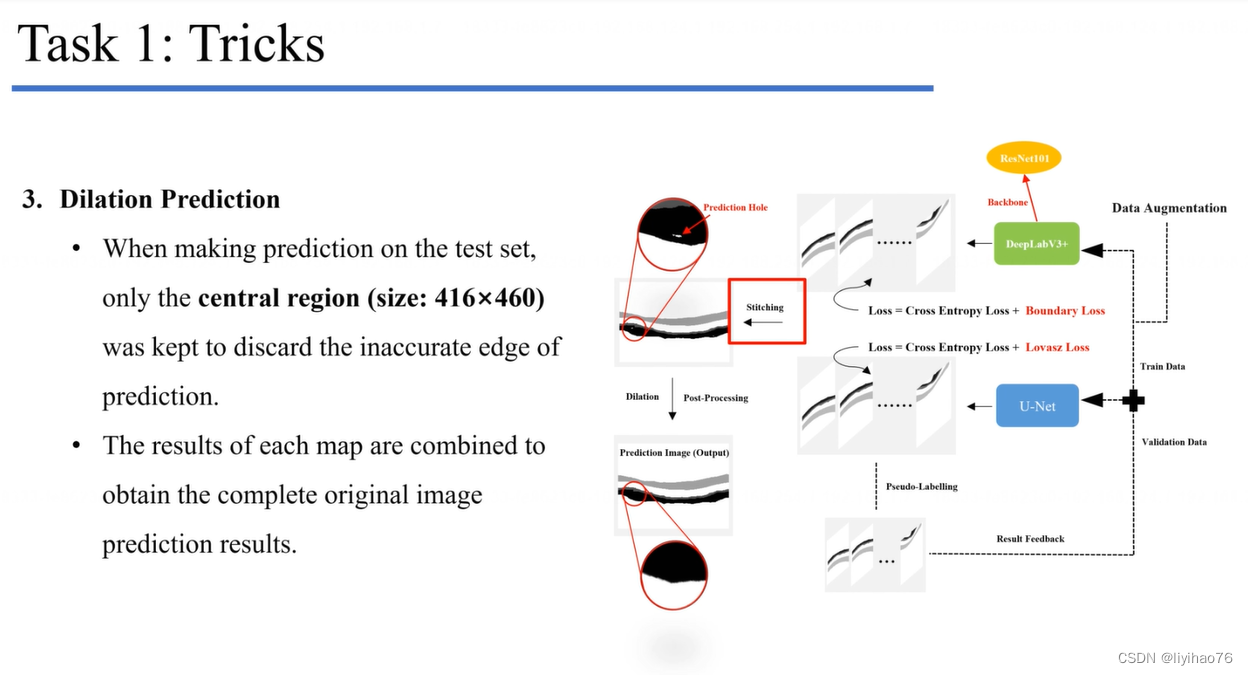
任务一:环扫OCT图像的层分割
Configuration overview
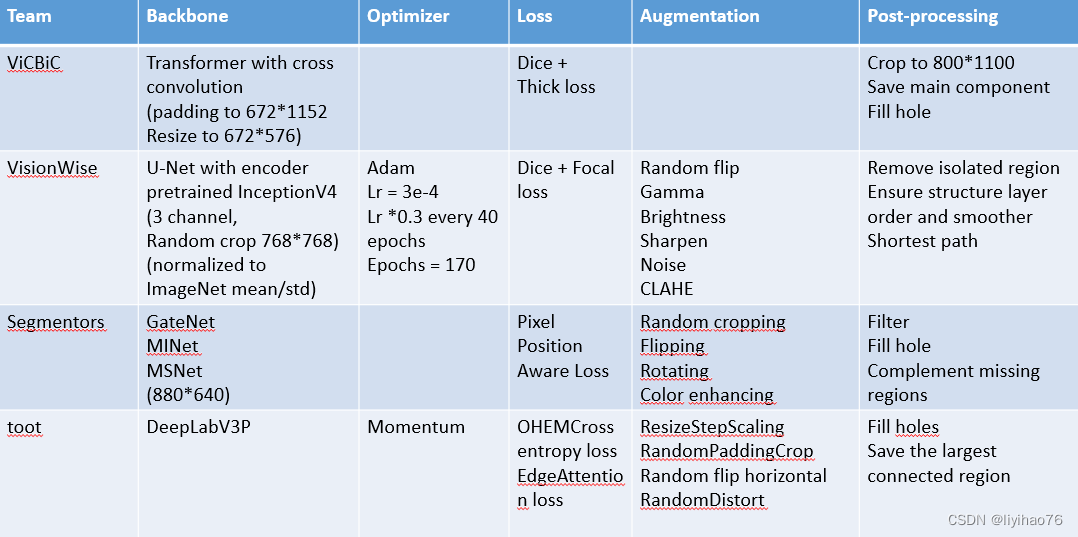

ViCBiC
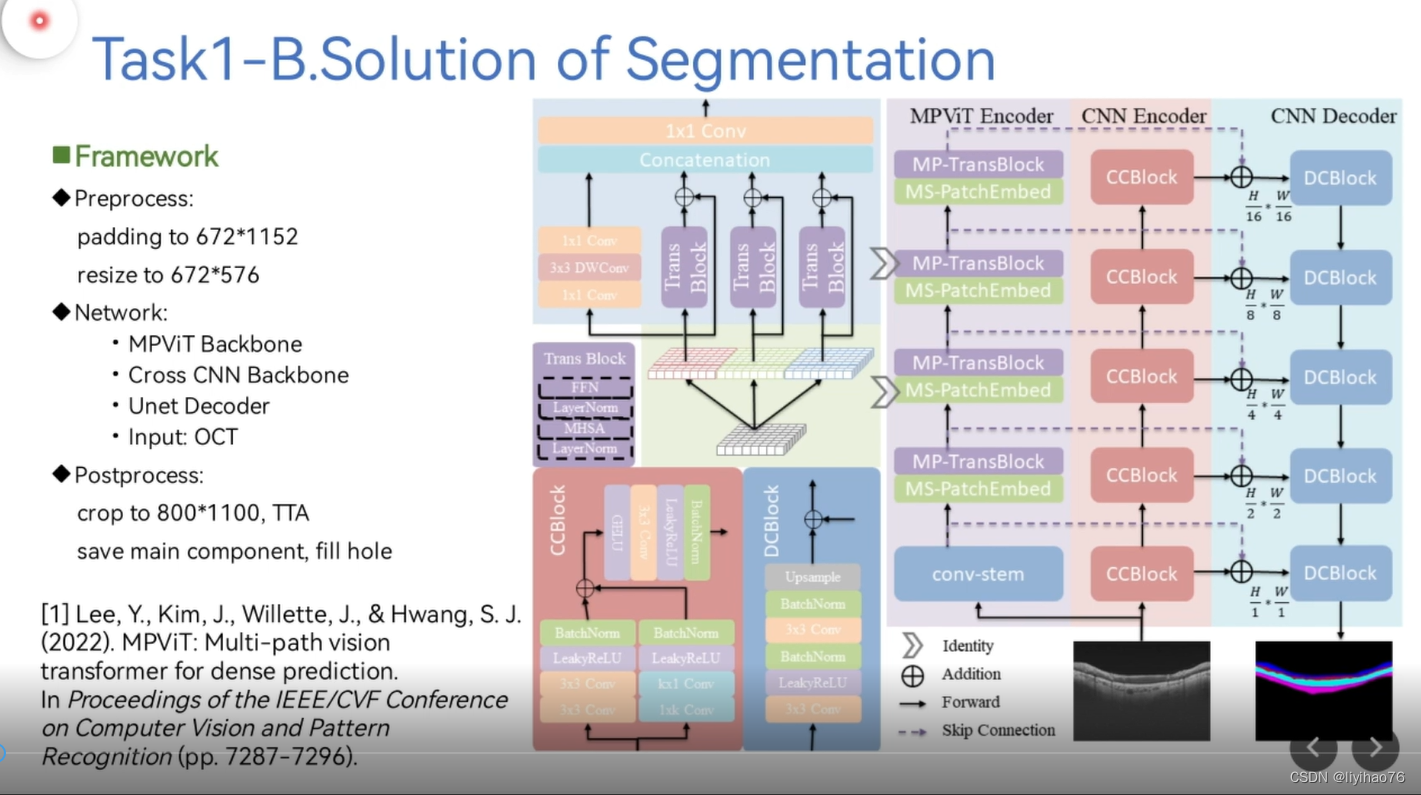
CNN Encoder和CNN Decoder组成了u型结构,然后在skip connection的时候加上Multi-Path Vision Transformer提取出来的特征。CCBlock模块中用双支路提取特征,非对称卷积支路的作用是增大感受野。
其中Multi-Path Vision Transformer基于文章 MPViT : Multi-Path Vision Transformer for Dense Prediction.
论文链接 代码链接
论文分析
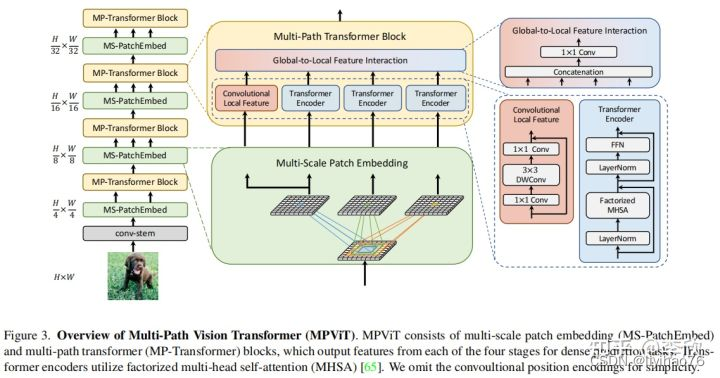
密集的计算机视觉任务,如目标检测和分割,需要有效的多尺度特征表示,以检测或分类不同大小的物体或区域。Vision Transformer(ViT)构建了一个简单的多阶段结构(即精细到粗糙),用于使用单尺度patch的多尺度表示。然而ViT的变体专注于降低自注意的二次复杂度,较少关注构建有效的多尺度表示。在这项工作中,作者以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。
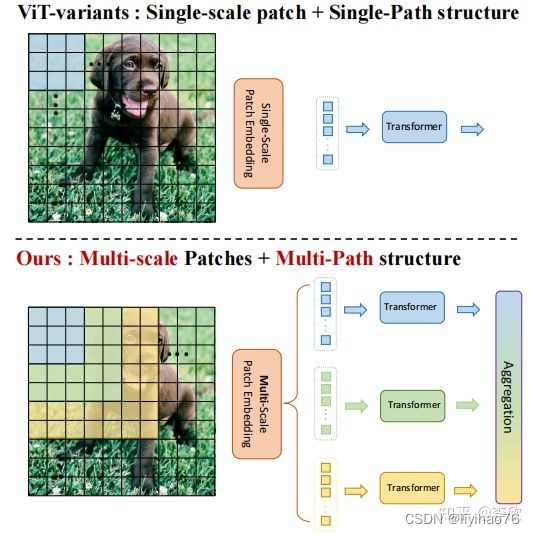
通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。
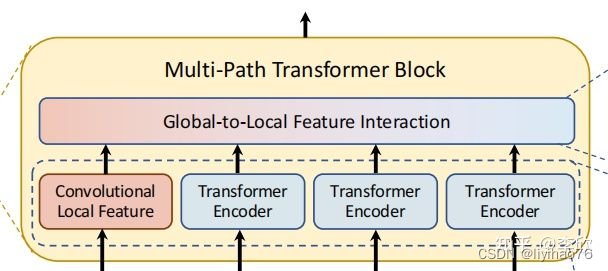
在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
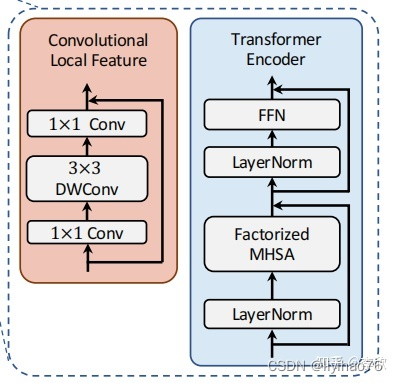
原因:Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。相反,cnn可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。因此,MPViT以一种互补的方式将CNN与Transformer结合起来。
Highlights
- 全新的分割网络
- 网络分割时进行四层分割,将中间两层的空白部分看作一层
- 使用了Thick loss
- 预测时使用了TTA
VisionWise

在比赛中,我们往往使用albumentations库函数进行图像的预处理,因为这个预处理库的运行速度非常的快,而且封装了大量的图像增强的方法。图像任务的话这个库函数非常滴奈斯。CLAHE的英文是Contrast Limited Adaptive Histogram Equalization 限制对比度的自适应直方图均衡。CLAHE算法的主要作用在于增强图像的对比度同时能够抑制噪声,典型的效果如下图所示。(a) original (b) CLAHE enhanced
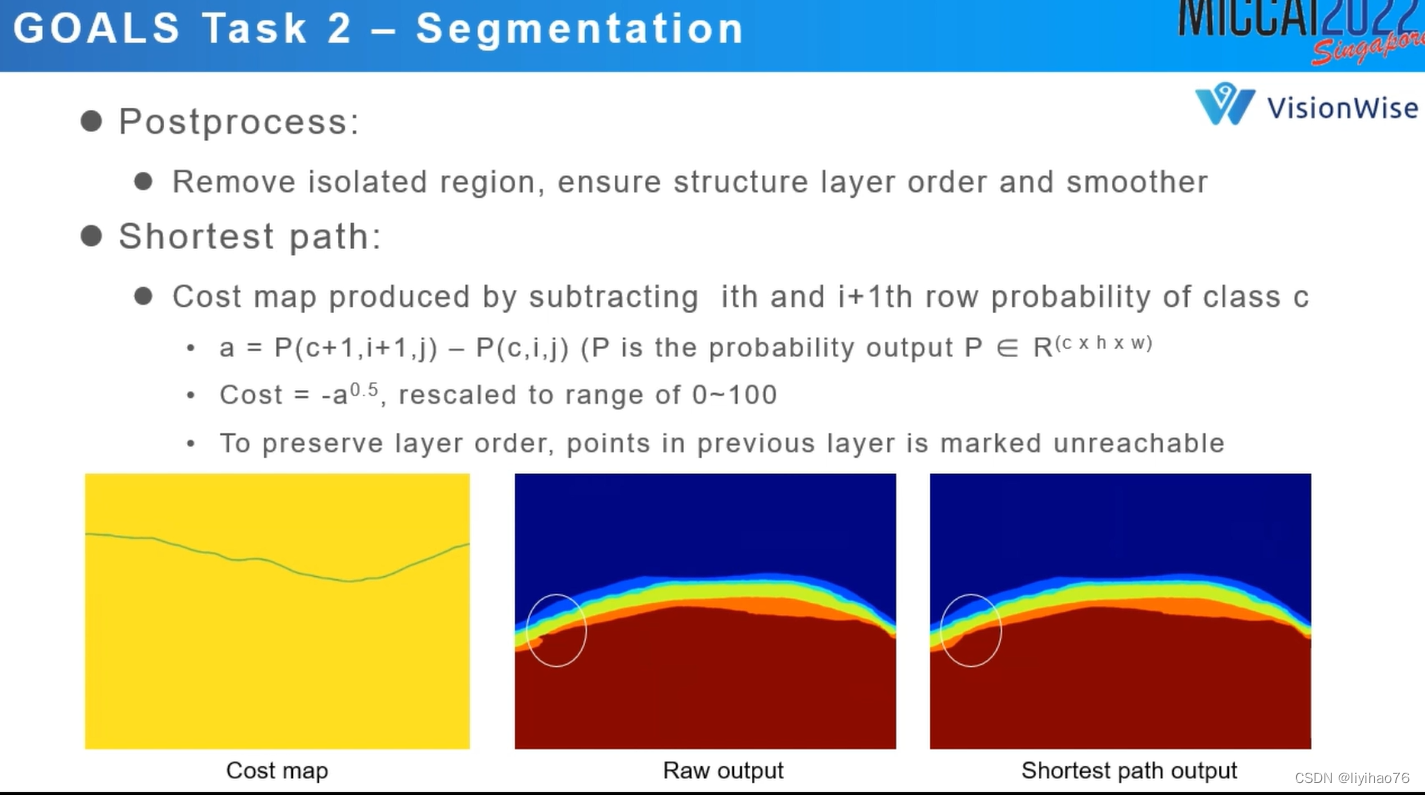
作者将原本的4分类变成了6分类,在对每一层边缘的确定上使用了shortest path策略
a = 下一层分类的最高层的概率 - 这一层分类最低点的概率
理想情况下,每层之间的边缘明确,则概率为100%-100%=0
实际情况下我们要找的应该是一个模糊的边缘点,这一层和下一层分类概率都在50%左右
最小化a的点既是我们所找的边界

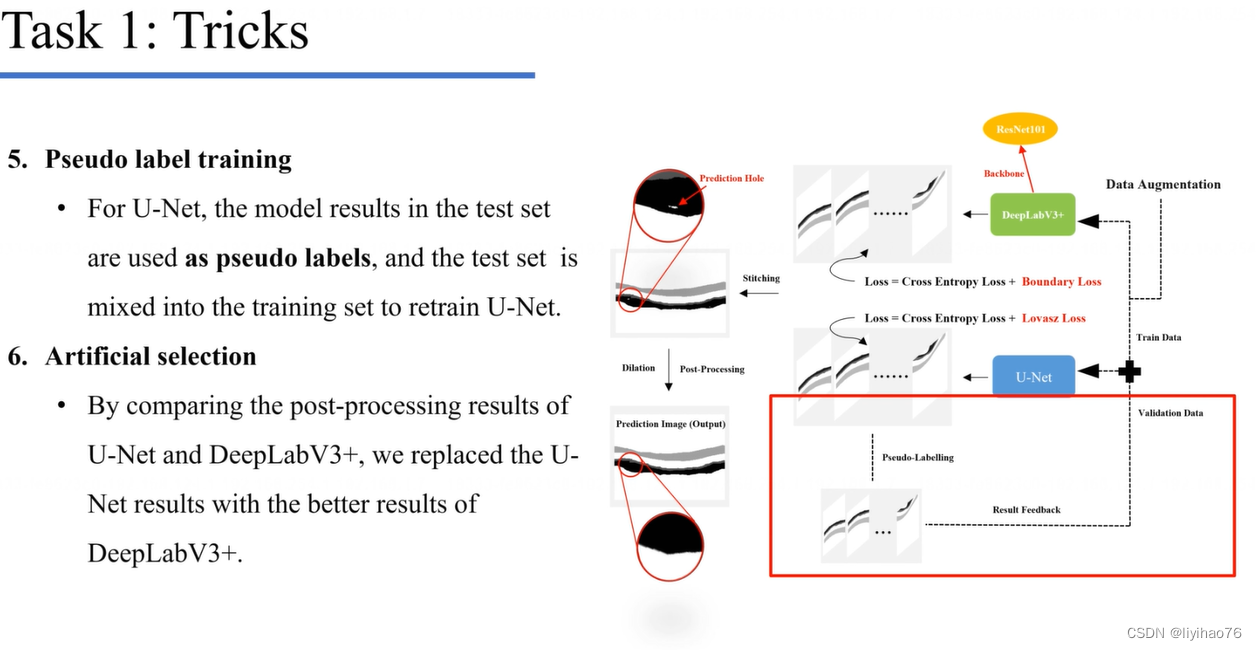
分割中的伪标签策略
选择高置信度的结果当作伪标签
对每个预测产生的结果制作一个置信度图,每个像素的值对应着这个像素类的最大概率,如果整张置信度图的值没有小于0.4的,我们可以将其看作高置信度的结果,并将其当作伪标签。
进行两轮的伪标签学习
Highlights
- 将4分类任务变成6分类,对每个隔断的层都进行分割
- 数据增强中使用了CLAHE
- 使用了shortest path策略确定边缘
- 预测时使用了TTA
- 伪标签学习策略
Segmentors
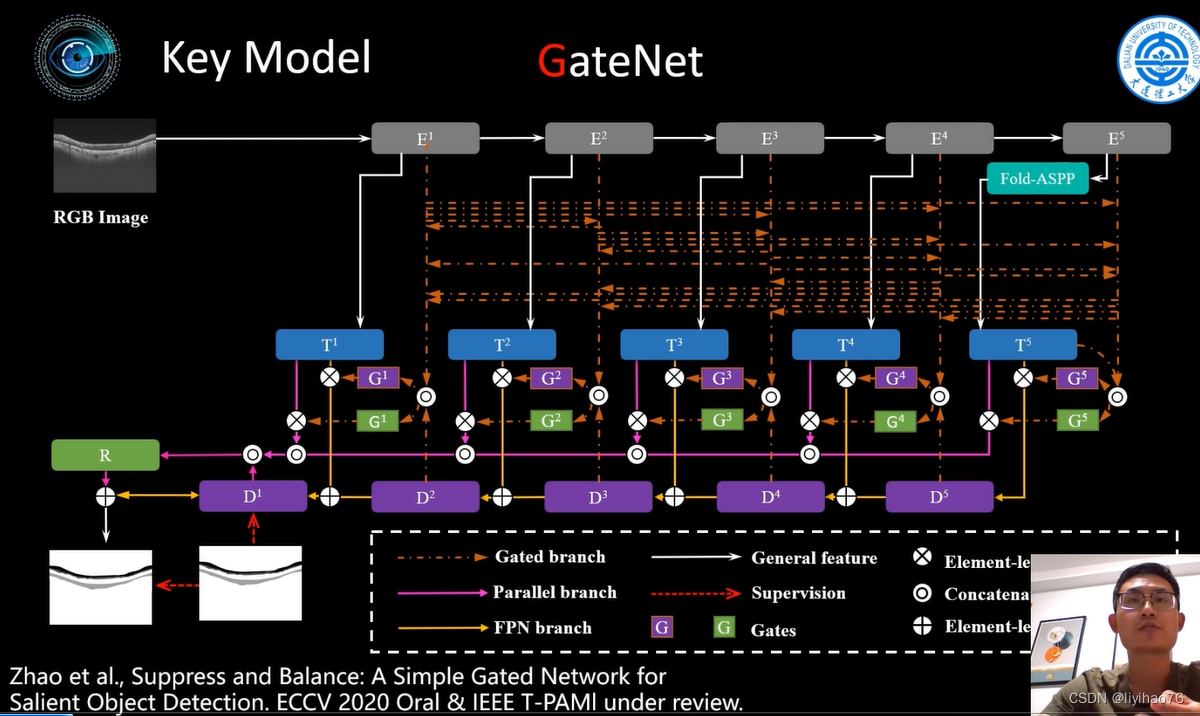
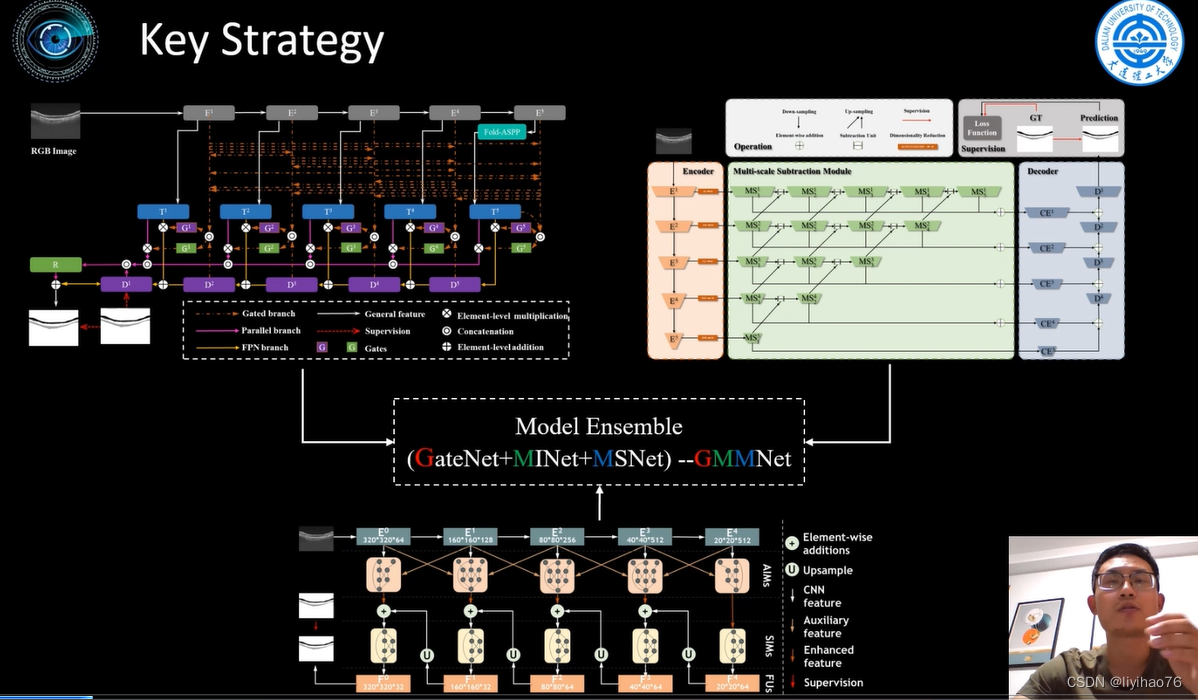
第一种网络来源于作者团队自己的文章 Suppress and Balance: A Simple Gated Network for Salient Object Detection
论文 代码
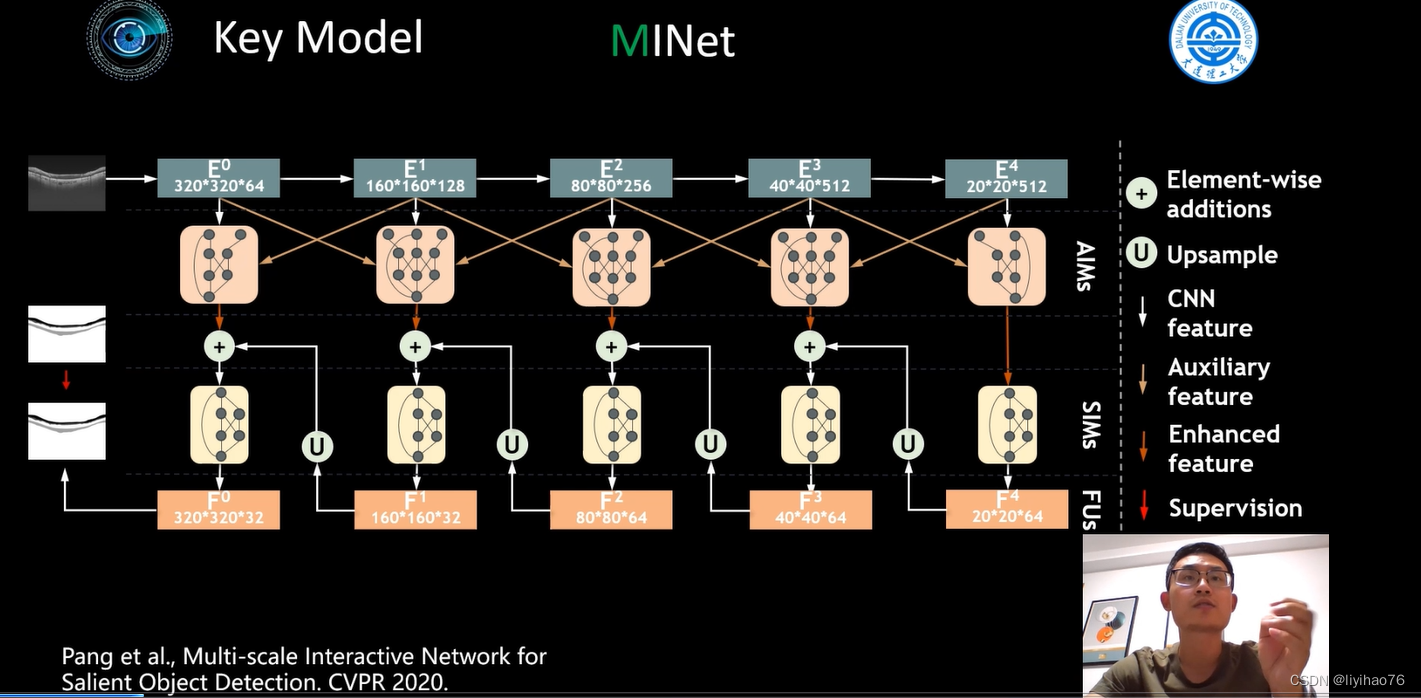
第二种网络同样是作者自己团队发过的文章 Multi-scale Interactive Network for Salient Object Detection
论文 代码
对目标检测相关方法不太熟悉,先不分析

第三种网络是作者自己去年发的文章 Automatic Polyp Segmentation via Multi-scale Subtraction Network
论文 代码

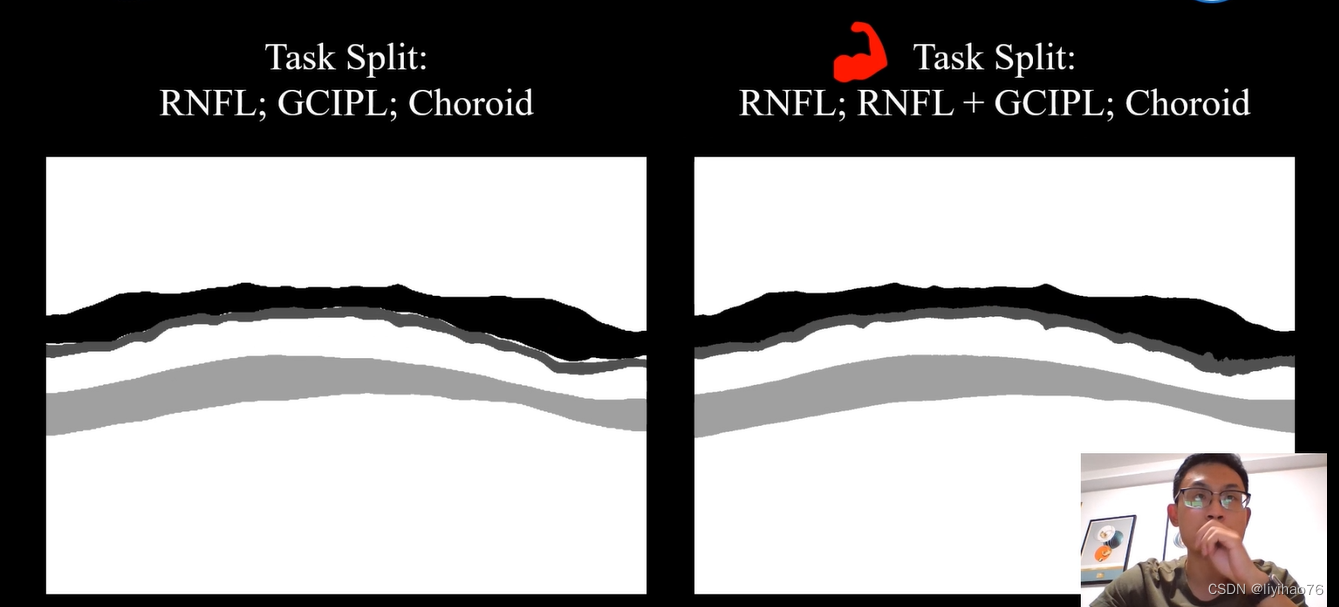
作者将原始的3层分割任务变成右边的3种任务,当rnfl和gcipl一起分割时效果更好。

多尺度训练/测试作为一种提升性能的有效技巧被应用在MS COCO等比赛中。输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。
最早见于“Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”这篇文章。训练时,预先定义几个固定的尺度,每个epoch随机选择一个尺度进行训练。
测试时,生成几个不同尺度的feature map,对每个Region Proposal,在不同的feature map上也有不同的尺度,我们选择最接近某一固定尺寸(即检测头部的输入尺寸)的Region Proposal作为后续的输入。
CRF常用于对FCN等预测后的图像进行优化处理
在使用FCN进行预测时,我们独立于周围像素给每个像素贴上标签,这可能会导致粗分割。CRF接受两个输入,一个是原始图像,另一个是每个像素的预测概率。对于全连接的CRF模型,CRF使用了一种高效的推理算法,在任意特征空间中,两个边势由高斯核的线性组合定义。该算法在将类分配给特定像素的同时,也考虑了周围像素的影响,从而得到更好的语义分割结果。
【图像后处理】python实现全连接CRFs后处理
BCE损失函数的三个缺点 :1》背景占优势的图像中, 前景像素的丢失将被稀释; 2》平等对待所有像素,没有主次之分; 3》独立计算每个像素的损失,忽略图像的全局结构。
Pixel Position Aware Loss----提出了一个带权重的BCE和IOU Loss。将不同的权值分配给不同的像素,扩展了二进制交叉熵。每个像素的权重由其周围的像素决定。难分像素会得到更大的权重,而容易的像素会得到更小的权重。
Highlights
- 使用了3种自己提出的网络,真的厉害
- 对分割任务的重新划分
- 多尺度训练/推理策略(常用于目标检测比赛)
- CRF分割后处理
toot
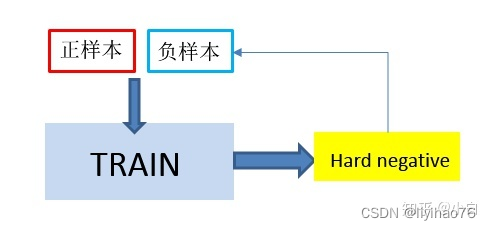
难分样本挖掘(hard example mining)机制
对于每一个网络,相当于一个桶,总有样本效果比较好,有的样本比较差,多用效果差的样本进行训练,那提高了整个网络的短板,总体的效果也会有提升。
难例挖掘是指,针对模型训练过程中导致损失值很大的一些样本(使模型很大概率分类错误的样本),重新训练它们。
维护一个错误分类样本池, 把每个batch训练数据中的出错率很大的样本放入该样本池中,当积累到一个batch以后,将这些样本放回网络重新训练。
用分类器对样本进行分类,把其中错误分类的样本(hard negative)放入负样本集合再继续训练分类器。
关键是找出影响网络性能的一些训练样本,针对性的进行处理。
CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining(oral)将难分样本挖掘(hard example mining)机制嵌入到SGD算法中,使得Fast R-CNN在训练的过程中根据region proposal的损失自动选取合适的Region Proposal作为正负例训练。
上面的论文就是讲的在线的方法:Online Hard Example Mining,简称OHEM
即:训练的时候选择hard negative来进行迭代,从而提高训练的效果。
简单来说就是从ROI中选择hard,而不是简单的采样。
Forward: 全部的ROI通过网络,根据loss排序;
Backward:根据排序,选择B/N个loss值最大的(worst)样本来后向传播更新model的weights.

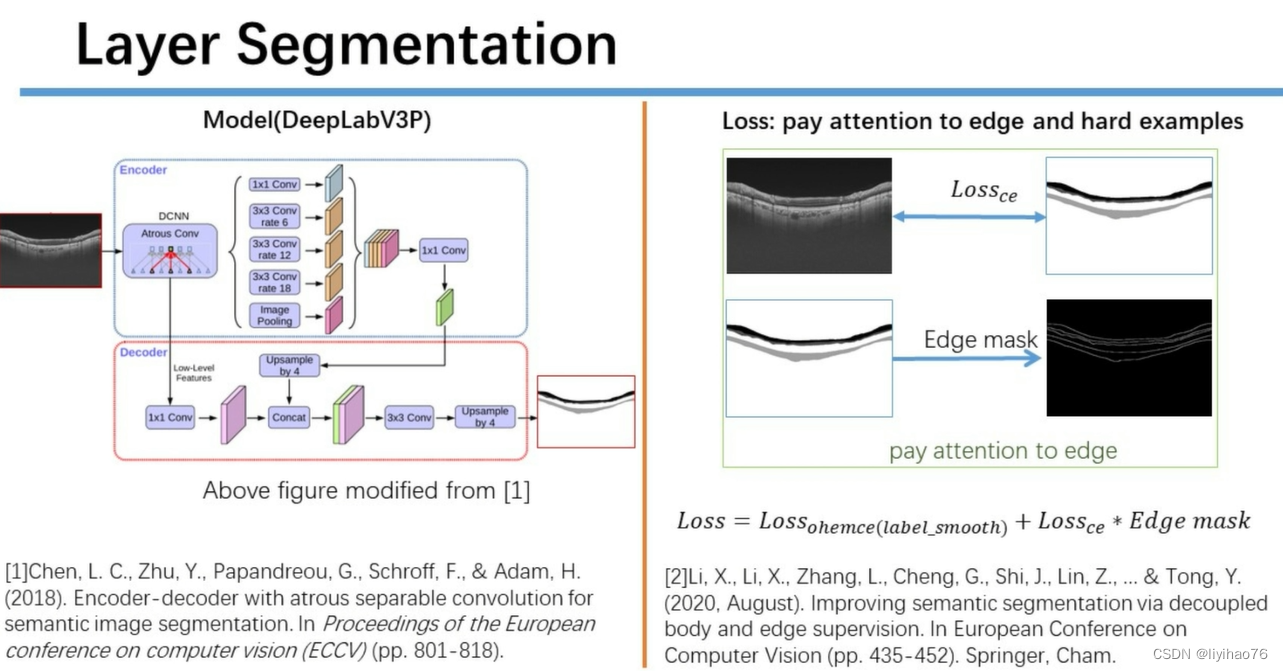
虽然全卷积网络(FCNs)在许多主要的语义分割baseline中表现出色,但它们仍然存在以下局限性:首先,FCNs的感受野(Receptive Field,RF)随着网络深度的增加而缓慢增长(仅线性增长),这种有限的RF无法完全模拟图像中像素之间的长距离依赖关系。此外,FCNs中的下采样操作会导致模糊的预测,因为与原始图像相比,细微的细节会在显著降低的分辨率中消失,由于像素的模糊性和噪声发生在物体主体内部,很难对其进行分类。因此,预测的分割边界往往是模糊的,边界细节远远不能令人满意,这导致性能下降,特别是在小物体上。
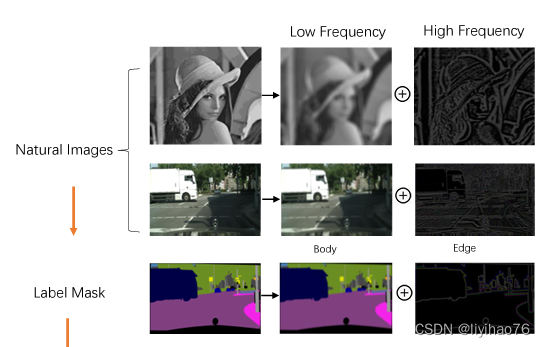
另一方面,人类通过感知物体主体和边缘信息来区分物体是很自然的。受此启发,本文以明确的方式探索主体和边缘之间的关系,以获得最终的语义分割结果。如图1(a)前两行所示,一个自然的图像可以分解为一个低空间频率分量,它描述了平滑变化的结构,以及一个高空间频率分量,它描述了快速变化的结构。首先应用均值或高斯滤波器进行平滑处理,其余高频部分可通过减法获得。同样的,分割mask也可以用这种方式解耦,其中细微细节的边缘部分可以通过减法从主体部分获得。 受这一结论的启发,假设用于语义分割的特征图也可以解耦为两个部分:主体特征和边缘特征(见图1(b))。前者包含了物体内部低频的平滑表示,而后者则有高频的sharper细节信息。
这里作者应该是用预测出来的label的边缘和gt的边缘计算ce?来实现pay attention to edge
Highlights
- TTA
- Online Hard Example Mining
- Edge loss
SJMED
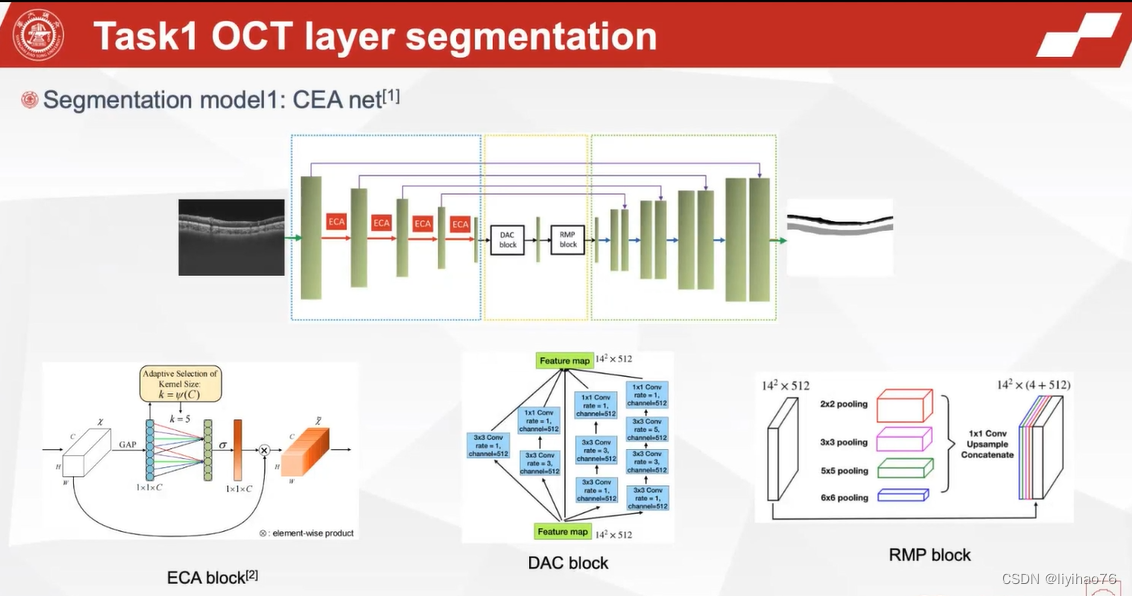
网络来自Automatic choroid layer segmentation in OCT images via context efficient adaptive network
文章未公开 代码未开源
ECA(Efficient Channel Attention) 注意力机制
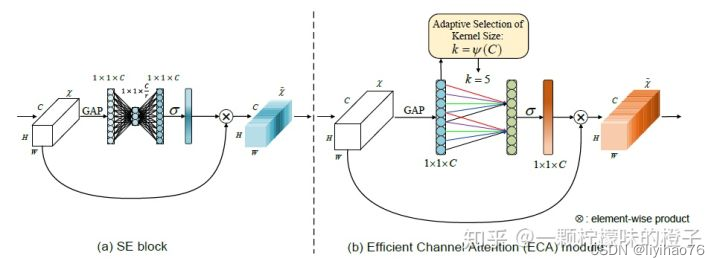
SE 注意力机制首先对输入特征图进行了通道压缩,而这样的压缩降维对于学习通道之间的依赖关系有不利影响,基于此理念,ECA 注意力机制避免降维,用1 维卷积高效实现了局部跨通道交互,提取通道间的依赖关系。具体步骤如下:
①将输入特征图进行全局平均池化操作;
②进行卷积核大小为 k 的 1 维卷积操作,并经过 Sigmoid 激活函数得到各个通道的权重w
③将权重与原始输入特征图对应元素相乘,得到最终输出特征图。
可以看到,ECA 注意力机制相比其他两个注意力机制来说,思想和运算都极为简便,对网络处理速度的影响最小,但 ECA 注意力只用到了通道注意力,其准确度还需实验来证明。
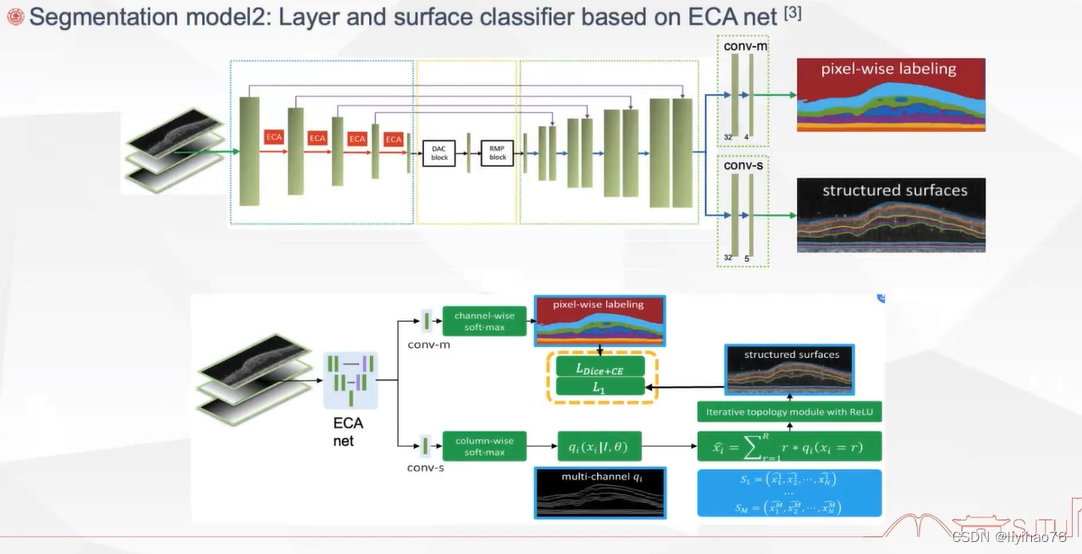
和上一个作者一样考虑到了边缘,单独计算了一个loss
structured layer surface segmentation for retina oct using fully convolutional regression networks
论文
代码未开源
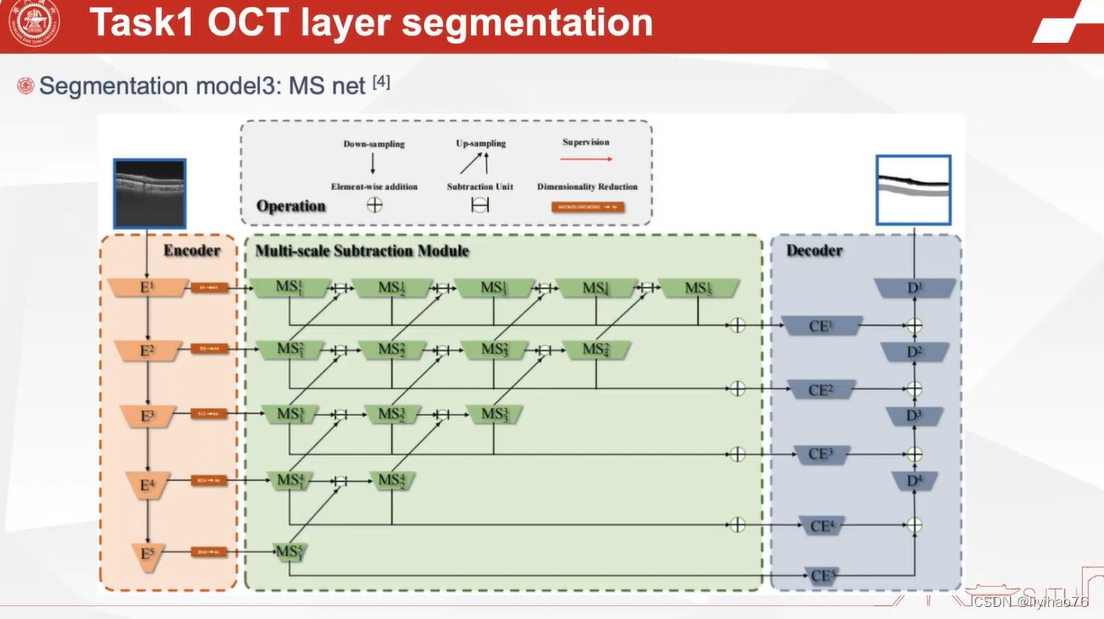
Automatic Polyp Segmentation via Multi-scale Subtraction Network
论文 代码


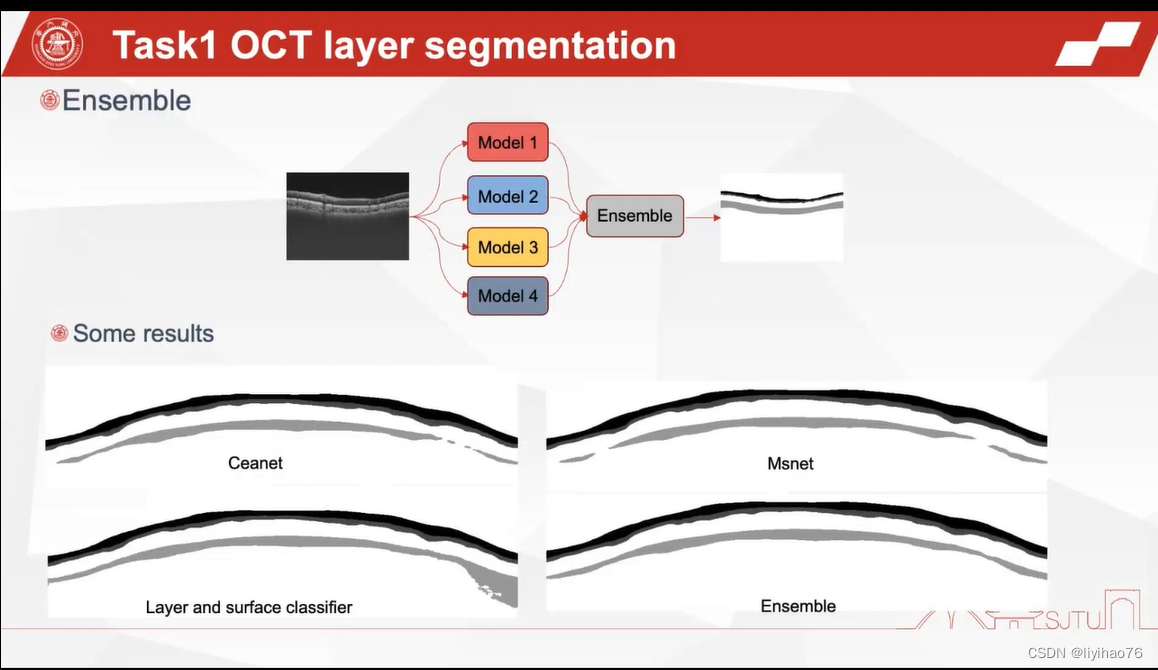

Highlights
- 使用了四种比较新颖的网络
WRMT
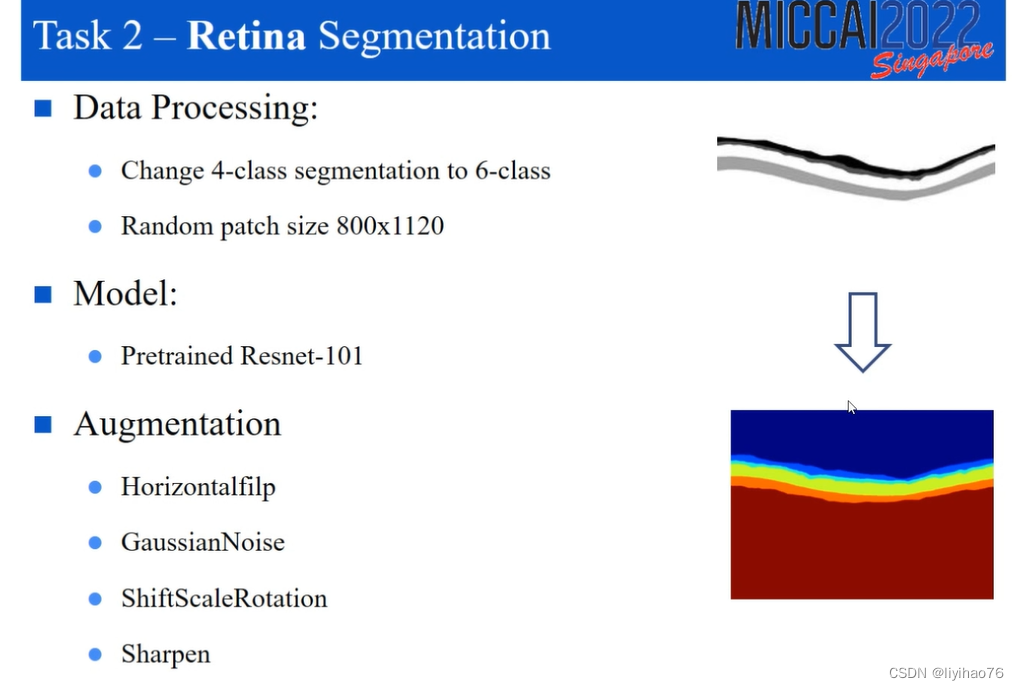
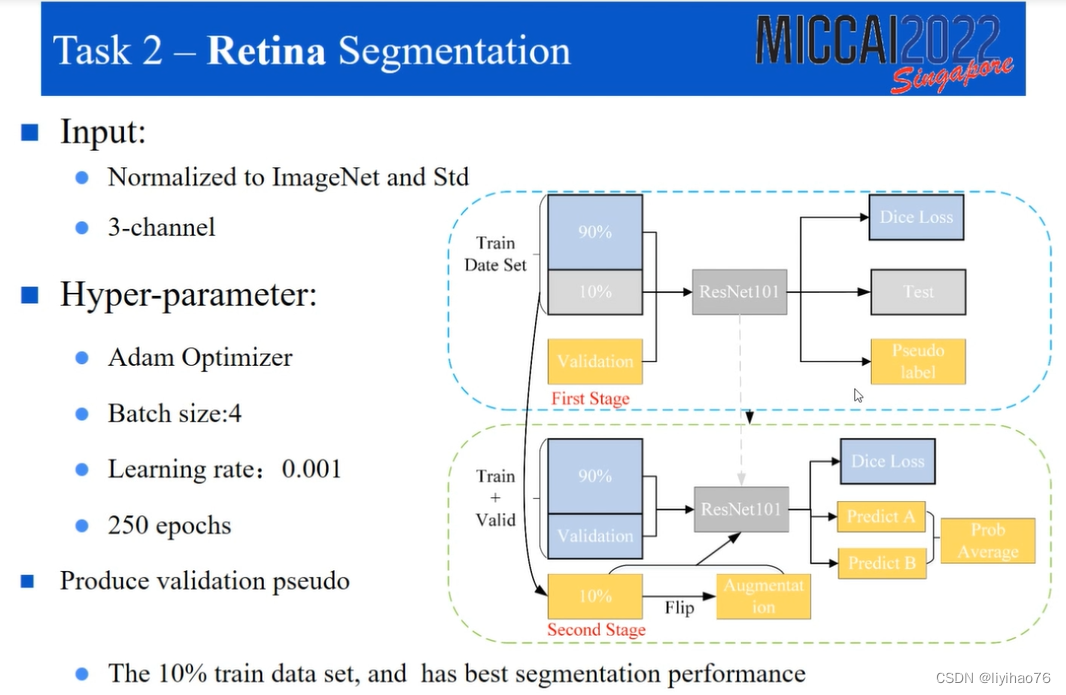
Highlights
- 将原始任务变成六分类任务
- 伪标签学习
AUTOMATE
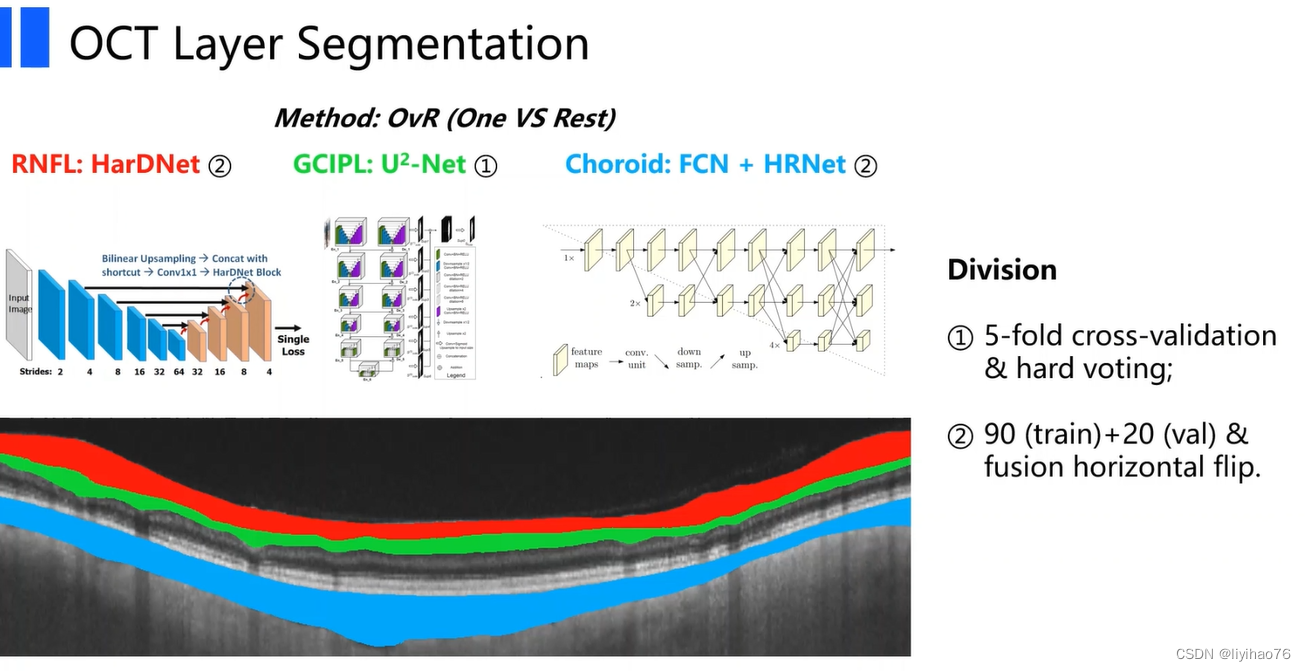
对每一层的分割使用不同的模型
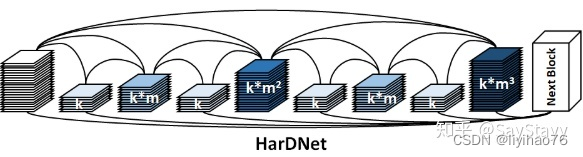
HarDNet指的是Harmonic DenseNet: A low memory traffic network,其突出的特点就是低内存占用率。过去几年,随着更强的计算能力和更大的数据集,我们能够训练更加复杂的网络。对于实时应用,我们面临的问题是如何在提高计算效率的同时,降低功耗。在这种情况下,作者们提出了HarDNet在两者之间寻求最佳平衡。
HarDNet可以用于图像分割和目标检测,其架构是基于Densely Connected Network。在HarDNet中,作者提出了Harmonic Dense Bocks的概念。如图1所示,可以看到该网络就像多个谐波。HarDNet的全称就是Harmonic Densely Connected Network。
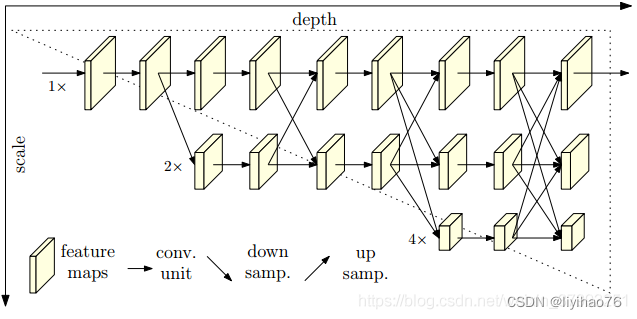
计算机视觉领域有很多任务是位置敏感的,比如目标检测、语义分割、实例分割等等。为了这些任务位置信息更加精准,很容易想到的做法就是维持高分辨率的feature map,事实上HRNet之前几乎所有的网络都是这么做的,通过下采样得到强语义信息,然后再上采样恢复高分辨率恢复位置信息(如下图所示),然而这种做法,会导致大量的有效信息在不断的上下采样过程中丢失。而HRNet通过并行多个分辨率的分支,加上不断进行不同分支之间的信息交互,同时达到强语义信息和精准位置信息的目的。

最大的创新点还是能够从头到尾保持高分辨率,而不同分支的信息交互是为了补充通道数减少带来的信息损耗,这种网络架构设计对于位置敏感的任务会有奇效。
我们从高分辨率子网作为第一阶段始,逐步增加高分辨率到低分辨率的子网(gradually add high-to-low resolution subnetworks),形成更多的阶段,并将多分辨率子网并行连接。在整个过程中,我们通过在并行的多分辨率子网络上反复交换信息来进行多尺度的重复融合。我们通过网络输出的高分辨率表示来估计关键点。生成的网络如图所示。
Highlights
- 换分为3个二分类分割任务,用不同的网络实现
- 多尺度训练
OPTIMA
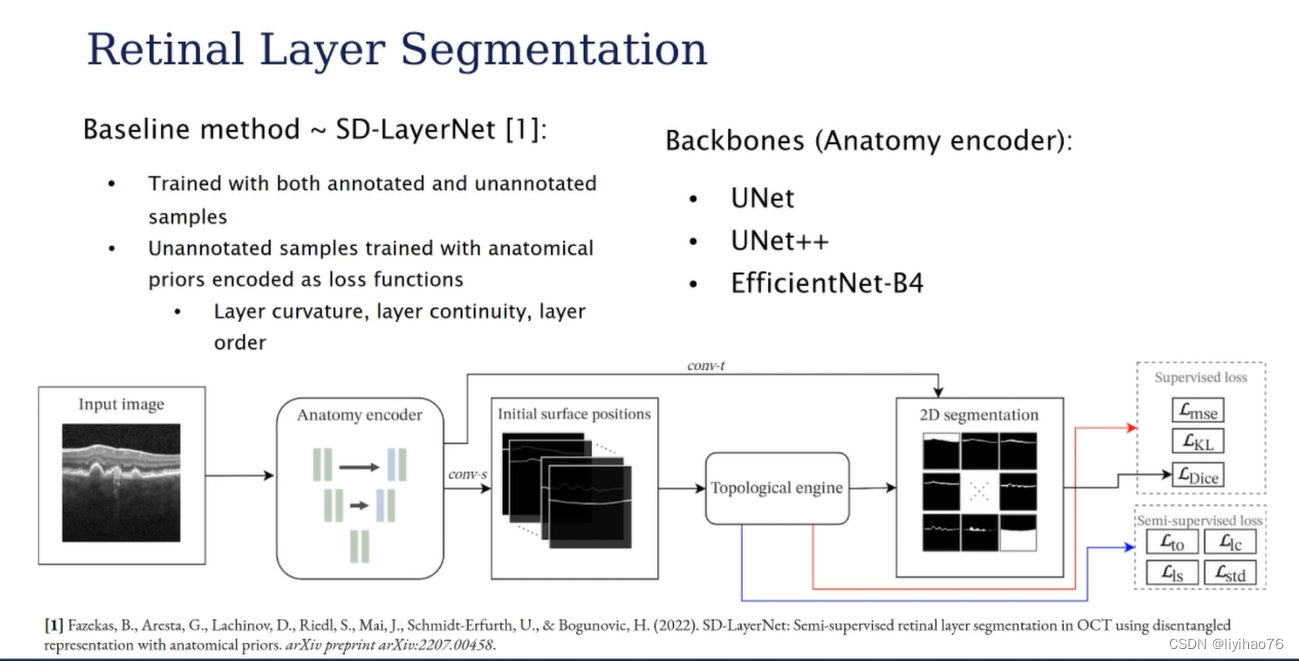
网络来自SD-LayerNet: Semi-supervised retinal layer segmentation in OCT using disentangled representation with anatomical priors
论文 代码未开源

Highlights
- 用半监督学习来实现分割任务
MedicalExploer

Boundary Label Relaxation
来自于 Boundary loss for highly unbalanced segmentation
物体边缘的分割历来是分割任务中比较难的地方,文章缓解这种问题的方法如下图:
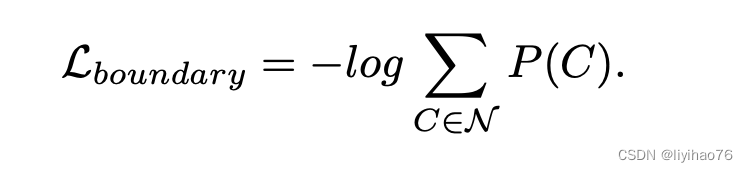
其中C是某像素周围3x3范围gt存在的种类数,直观来看softmax cross entropy中倾向于使单个类别的概率为1,本文中的label relaxation倾向于使得该像素成为相邻gt中若干类加在一起的概率为1,如果C只取一类就是标准的cross entropy,如果取全部类别相当于ignore。
提出了一种仅在训练期间应用的类标签空间的修改,它允许在一个边界像素处预测多个类。将边界像素定义为具有不同标记邻居的任何像素。为了简单起见,沿着类A和类B的边界对像素进行分类。建议最大化P(A∪B)的可能性,而不是最大化注释提供的目标标签的可能性。由于A类和B类是互斥的,目标是使A和B的并集最大化:

lovasz-softmax loss是对语义分割指标miou直接进行优化的一个loss,相比比较经典的dice loss有诸多优势。lovasz-softmax loss与cross entropy 结合使用fine-tune,效果更优
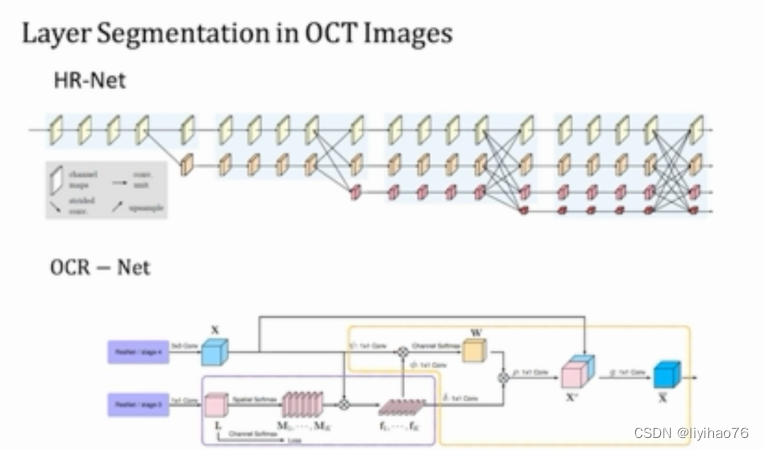
Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation
论文 代码
OCR是MSRA和中科院的一篇语义分割工作,结合每一类的类别语义信息给每个像素加权,再和原始的pixel特征concat组成最终每个像素的特征表示,个人理解其是一个类似coarse-to-fine的语义分割过程。
目前cityscape的分割任务中,排名最高的还是HRNetv2+OCR,参考paperswithcode
OCR的整体方法流程图如下

Highlights
- 组合了多种分割loss
CrashKing
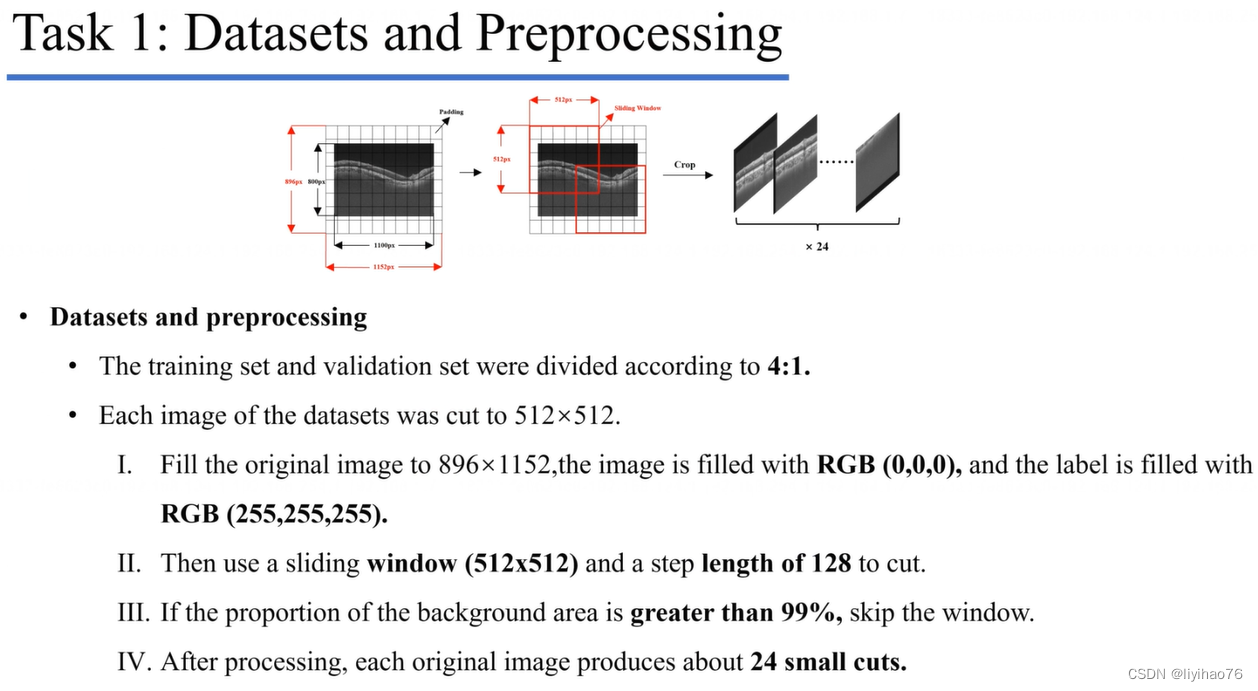

Highlights
- 用滑窗从原数据中产生多个patch
- 伪标签学习
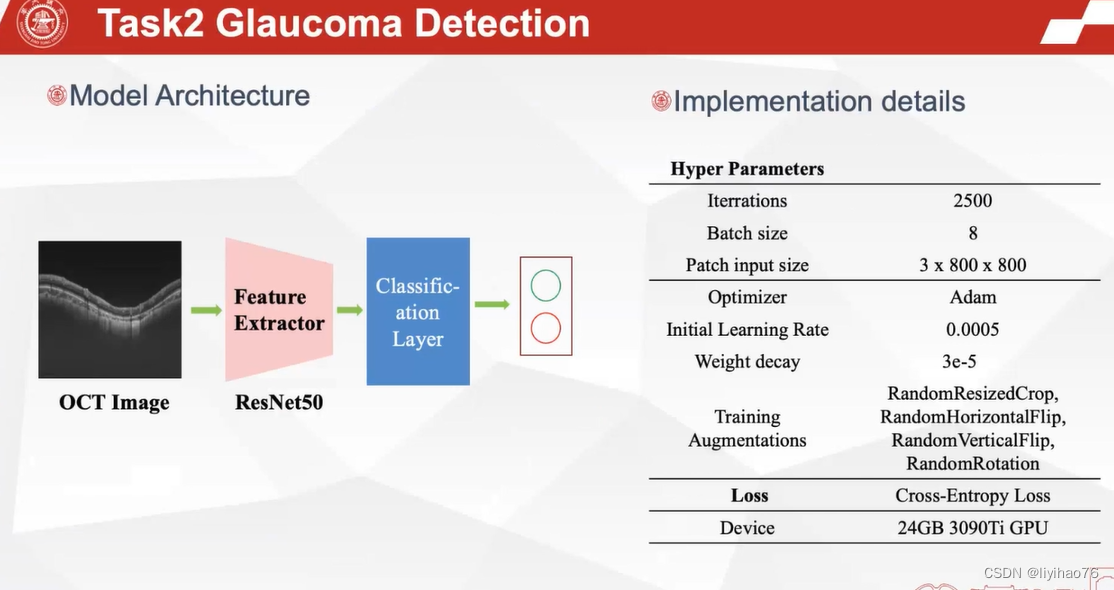
任务二:青光眼检测
Configuration overview
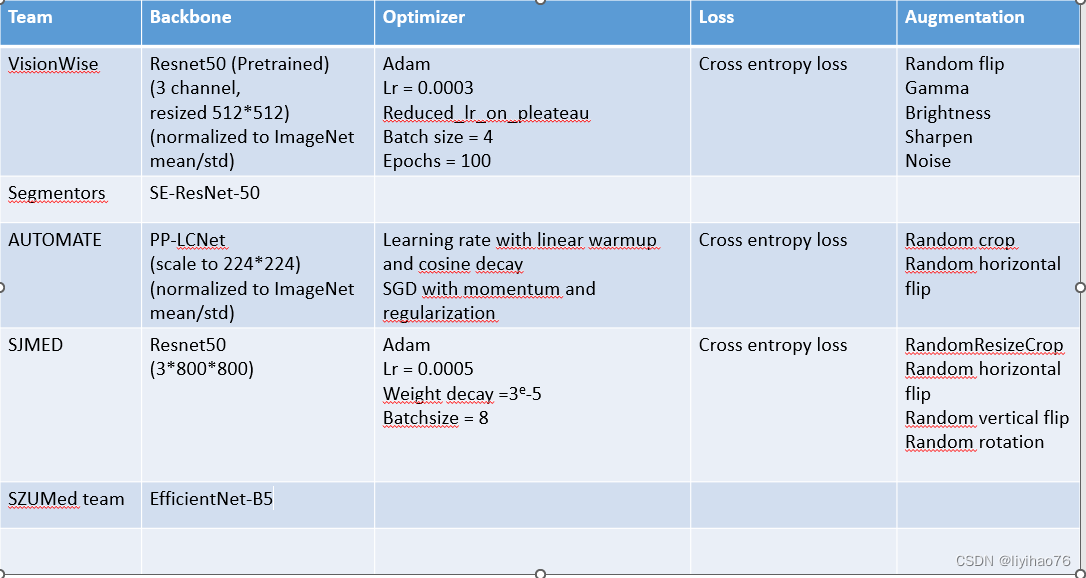
VisionWise


Highlights
- 伪标签学习
AUTOMATE

百度新出的一篇论文,提出了一种基于MKLDNN加速策略的轻量级CPU网络,即PP-LCNet,它提高了轻量级模型在多任务上的性能,对于计算机视觉的下游任务,如目标检测、语义分割等,也有很好的表现。以下是论文链接和开源的基于PaddlePaddle的实现。
文章 代码
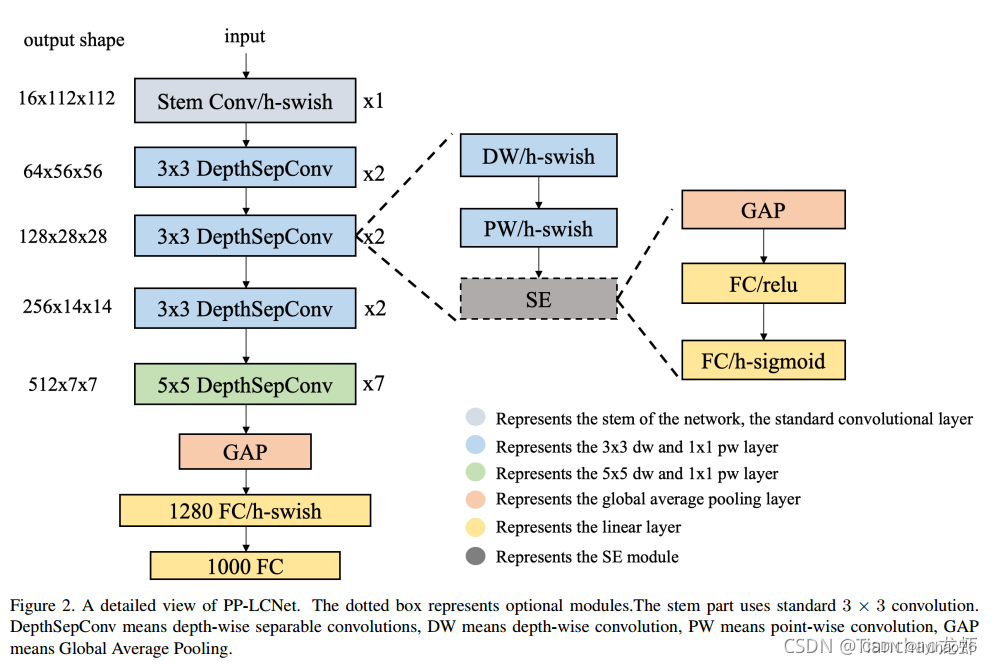
整体网络比较简单,使用了串联结构。同时使用了深度可分离卷积作为Basic block。这个block没有shortcuts连接,因此没有额外的拼接或者相加的操作。这些操作不仅会导致推理速度的下降,而且在小模型上不会提升精度。 从以下策略,对这个BaseNet网络进行优化。
MobileNet v3中提出了H-Swish, 本文也借鉴使用H-Swish。
SE模块是一个通道注意力模块,也在MobileNet v3中使用了。通过实验发现: 在网络的末尾,使用SE模块,会有较好的效果。因此,本文只在网络的末尾使用了SE模块。
分类的机器学习算法输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用前者进行投票叫做硬投票(Majority/Hard voting),使用后者进行分类叫做软投票(Soft voting)。 sklearn中的VotingClassifier是投票法的实现。
Hard Voting
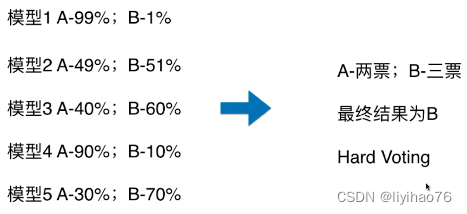
Soft Voting

Highlights
- 交叉验证 ,硬投票
SJMED















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









