







初级课(Beginner level)
Lesson 1:为啥需要AI
intel 视觉课程分布:
- 100 – 初级课程:(通识课)
- 200 – 中级课程:(OpenVINO technical with hands-on labs:OpenVINO 实验)
- 300 – 高级课程:(OpenVINO technical, system and product level: 了解OpenVINO 产品,系统)
课前思考
- How can Intel help me get started build an AI product?(英特尔如何帮助我开始开发人工智能产品?)
- Which hardware to choose?(选择哪种硬件?)
- How to collect data and train it? (如何收集和训练数据?)
- Which software to use? There are so many options…(使用哪种软件?有很多选择)
- What is a deep-learning model, where can I get one? (什么是深度学习模型,我在哪里可以得到一个?)
- How to process Video?(如何处理视频?)
什么是OpenVINO(Open visual inference and neural network optimization)
OpenVINO:是开放式视觉推理和神经网络优化
OpenVINO是英特尔构建AI应用程序的工具包,是免费的,有开源版本,易于使用
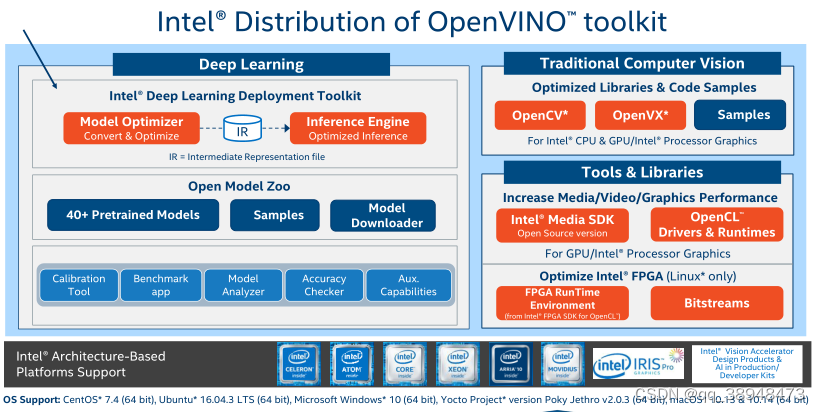
lesson1 课程总结
- 人工智能是我们管理“物联网”将收集的海量数据的唯一方法。
- 人工智能将改变我们未来所做的一切,它可能是构建智能系统的最佳方式
- 人工智能是一个广泛的能力-本课程专注于视觉应用
Lesson 2:什么是视频,什么是计算机视觉,该怎样在现代计算机上加速视觉
视频:无数图片的动态衔接,每个图片都由像素点构成
池化:获取像素点周围像素值,求其平均值,赋给其该点,图像模糊
锐化:扩大像素点变化差距,凸显边缘信息
opencv(开源计算机视觉库):调用该库函数,可以读写图像,并对图像进行颜色改变,调整大小,旋转,滤镜,模糊,锐化,寻找边缘,角落等
open VINO 的传统计算机视觉中,就包含了opencv
lesson2 课程总结
- 视频占互联网流量的80%•
- 视频是一系列连续的图像•
- 一个图像是一个像素阵列,每个像素有强度级别或颜色混合从R,G,B值。
- 可以操作像素来模糊,锐化或执行其他任务•
- 我们可以检测图像中的特征(边缘,线,角→对象)•、
- OpenCV是英特尔软件来加速计算机视觉•
- OpenCV包含在OpenVINO中
Lesson 3:如何加速视频处理
高清视频中
—1帧= 1920 × 1080像素
—1像素= 3字节(R,G,B)
—1帧= 1920 × 1080 × 3字节= 6,220,800字节(6.2MB)
—1秒= 6.2MB × 25 = 155 MB
— 1分钟= 9.3 GB
在当前的通讯环境下,完全没有足够的流量支撑1秒155MB的数据,所以在这个流程中需要尽可能的降低视频传输的流量
—1分钟youTube压缩= 71.9MB
压缩可根据空间冗余(Spatial Redundancy)和时间冗余(Temporal redundancy)来进行压缩
冗余—能够以较小的像素/位呈现大量数据。不丢失信息(无损)
视频格式以MP4为例,可以看做一个容器,包含了视频流,音频流,以及元数据比特率,分辨率…编解码器
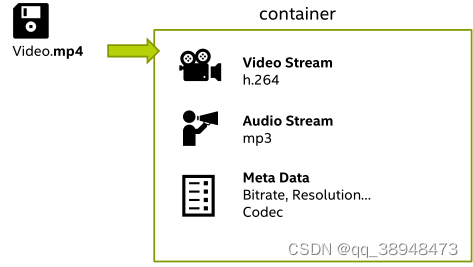
视频传播第I帧数据(经过B帧和P帧,B帧和P帧分别保留了I帧的部分信息),分布经历了编码Encode(Compress) ,解码Decode (Un-Compress)
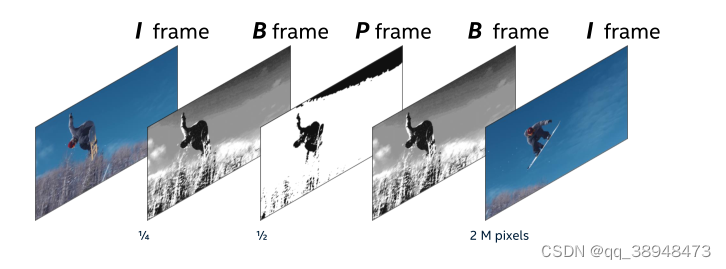
Lesson3 总结
- 视频压缩图像中利用冗余(框架)和跨帧代表相同数量的信息用更少的数据,来描述相同的图片
- 编解码器,视频容器文件,视频处理,在CPU上使用软件就可以完成,但英特尔集成gpu专用硬件,加快了处理速度
Lesson 4 如何加速视觉在神经网络上的应用
图像分类的过程:
概述:将图像锐化,获取图像中的特征,将特征赋予不同权重,通过公式来获取可能的概率,概率较大为该类,该类较小,则不为该类。
基础神经元:
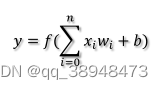
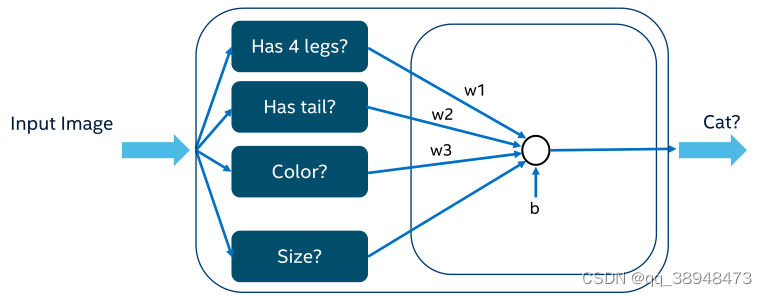
单独的层将对应特征赋予特定权重,给予结果,套入公式,获取对应概率,来判断结果。
神经网络:需要更多的层和非线性函数

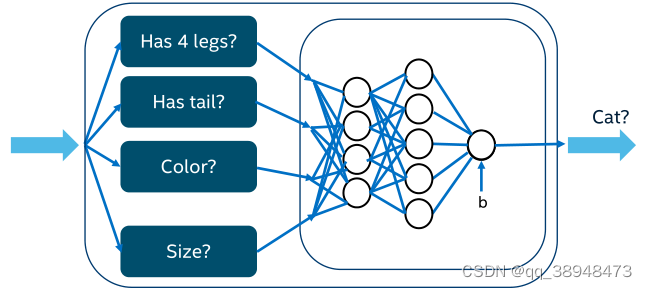
在大量层构建的神经网络中,计算流程如下:
首先随机生成神经网络中每个神经元对应的权重参数,
Forward:将图像输入神经网络中,根据神经网络中的计算权重,获得分类或推断的结果。
将预期结果与实际的损失进行评估,获取损失函数。
Backward:以损失函数为目标函数,求其最小化,使用梯度下降对更新神经网络中的参数矩阵。
如何加速神经网络
1.需要大量的操作和内存(Intel的CPU, iGPU, FPGA和VPU,都可以提供对应的操作和内存空间)
以Resnet50为例:

2.intel提供了DLDT - Deep Learning Deployment Toolkit
DLDT将预训练模型(pre-trained model:tensorflow 等深度学习框架构建好的)通过模型优化器(Model Optimizer)转换成IR格式的文件,然后通过推理引擎(Inference Engine)放在CPU这些硬件上运行,为AI应用提供服务。
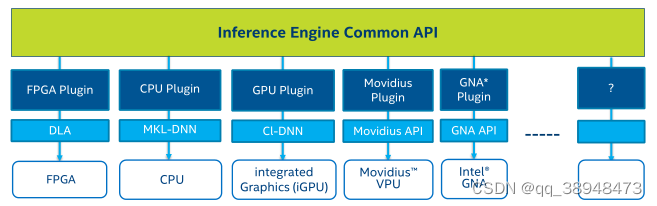
而推理引擎也针对不同类型的硬件提供了对应的API,方便神经网络在对应硬件上运行
Lesson4 总结
- DL模型可以用于分类、检测、分割和许多其他任务
- DLDT(深度学习部署工具包)是英特尔SW加速深度学习推断,是OpenVINO的一部分
Lesson 5: 视频分析管道
视频处理
针对每一帧的操作:

Decode:视频首先要解码(未压缩)
Pre Processing:(选择特定的帧进行缩放,调整大小,绘制用户感兴趣的区域) 提高图像的数据质量
Inference: 使用一个或多个深度模型来推理
Post-Processing:将图像经过模型处理后的,进一步处理(如,高亮标签,在分类中渲染正确框架)
Encode:将处理后的视频进行压缩(Compress the video back)
跳帧执行的操作:
 
Lesson 5 总结
- 视频分析 = 视频处理 + 计算机视觉 + AI(推断)
- OpenVINO拥有构建视频分析管道以及人工智能应用的所有所需的所有软件组件
- 视频管道分析的绝大多数复杂操作,都是在每帧进行的。
Lesson 6 显示, OpenVINO 实验
可视化搭建组件,构建模型完成实验
- 交互式人脸检测演示
- 多通道人脸检测演示
- 行人跟踪演示
- 道路分割演示
Lesson 7-8 完整的流程,从数据到使用Intel工具的产品
OpenVINO拥有构建AI的所有组件,可构建模型和AI,支持各种常见硬件运行,也会支持异构系统。
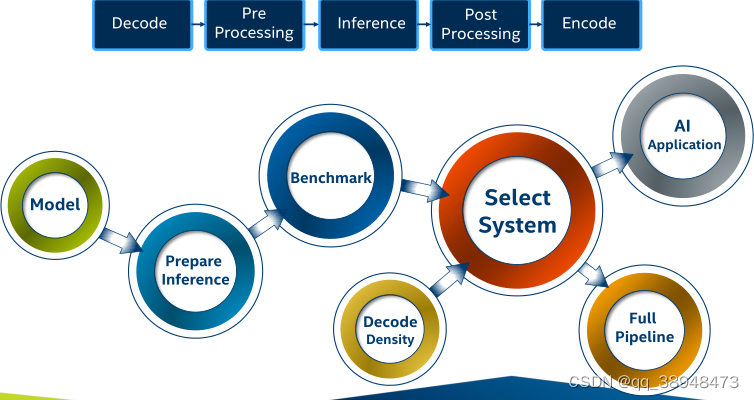
完整的构建应用流程
- 获取DL模型
- 准备用于推断的模型
- 对性能进行基准测试
- 检查解码和编码密度
- 模拟整个流水线
- 构建一个AI应用程序















 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









