






 本文详细解释了CNNs的工作原理,包括LeNet-5的7层结构,卷积和池化在提取图像特征中的作用。同时介绍了TextCNN和DPCNN在文本分类中的应用,展示了深度金字塔结构如何提升文本特征提取和分类性能。
本文详细解释了CNNs的工作原理,包括LeNet-5的7层结构,卷积和池化在提取图像特征中的作用。同时介绍了TextCNN和DPCNN在文本分类中的应用,展示了深度金字塔结构如何提升文本特征提取和分类性能。
不懂CNNs,何以明白卷积与池化?
本文将从CNN工作原理、TextCNN工作原理、DPCNN工作原理三个方面,带您一文搞懂CNNs工作原理。
CNNs工作原理
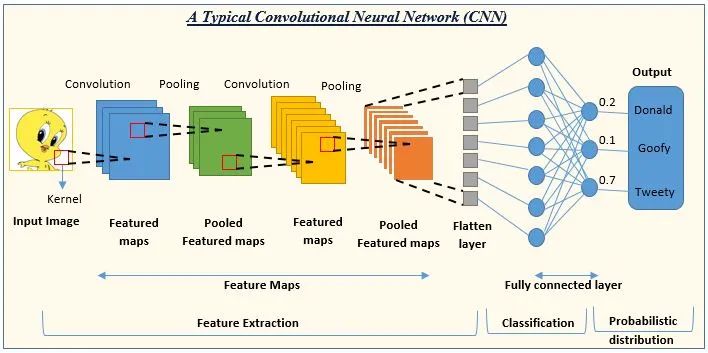
一、CNN工作原理
CNN(Convolutional Neural Network):卷积神经网络通过卷积和池化操作有效地处理高维图像数据,降低计算复杂度,并提取关键特征进行识别和分类。
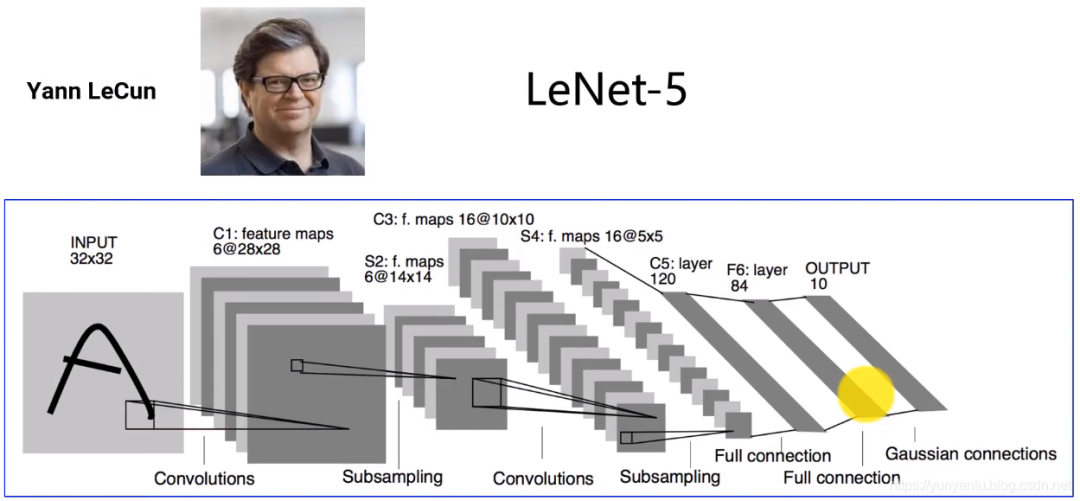
LeNet-5被誉为卷积神经网络的“Hello Word”,是图灵奖获得者Yann LeCun(杨立昆)在1998年提出的CNN算法,用来解决手写识别的问题。
CNN(卷积神经网络)
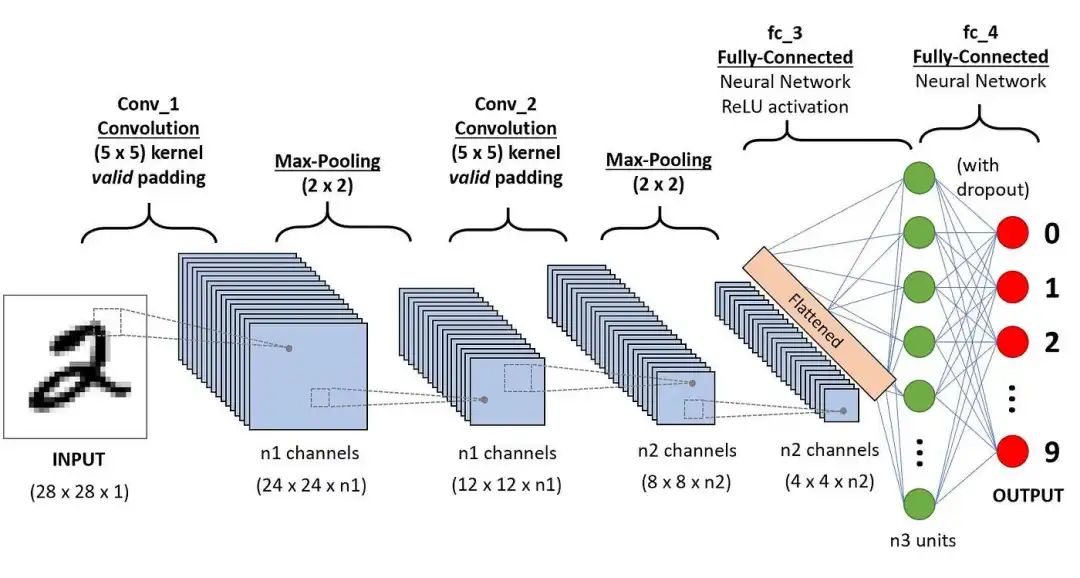
LeNet-5是一个7层的卷积神经网络,包括卷积、池化和全连接层,每层都有可训练参数。卷积层通过多个Feature Map和卷积滤波器提取图像特征,每个Feature Map包含多个神经元处理局部信息。
卷积和池化
-
输入层:INPUT
-
三个卷积层:C1、C3和C5
-
两个池化层:S2和S4
-
一个全连接层:F6
-
输出层:OUTPUT
LeNet-5网络结构
工作原理:LeNet-5通过卷积层提取图像局部特征,池化层降低数据维度,全连接层进一步提取高级特征并进行分类。
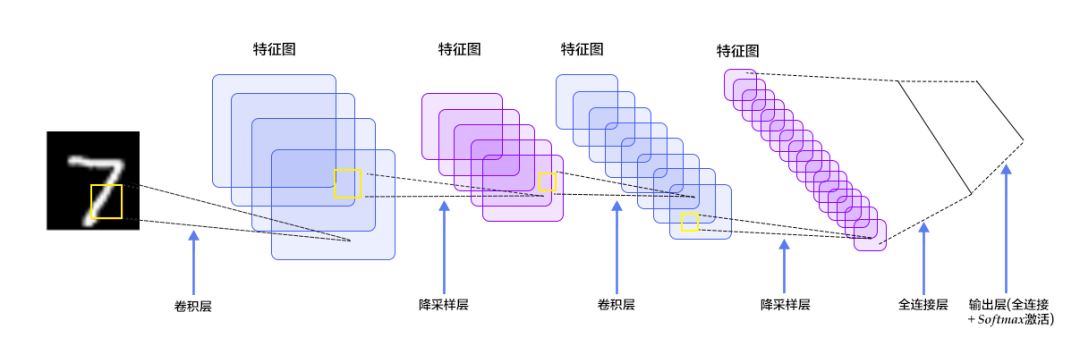
LeNet-5工作原理
-
INPUT层:负责接收32x32像素的输入图像,是数据的入口。
-
C1层:应用6个5x5的卷积核对输入图像进行特征提取,输出28x28的特征图。
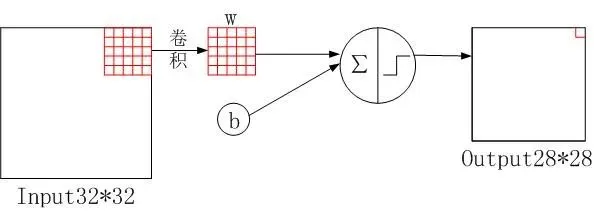
C1层
-
S2层:对C1层的特征图进行2x2的池化操作,降低特征图尺寸并提取关键信息。
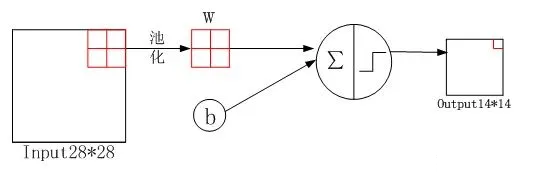
S2层
-
C3层:利用16个5x5的卷积核组合S2层的特征图,生成10x10的特征图,实现特征的高级组合。
C3层
-
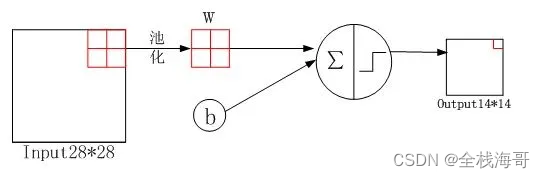
S4层:对C3层的特征图进行进一步的池化操作,进一步降低特征图尺寸。
-
C5层:通过120个5x5的卷积核与S4层全连接,生成全局特征,输出为1x1的特征图。
-
F6层:作为全连接层,将C5层的特征映射到84维空间,通过sigmoid激活函数进行非线性变换。

F6层
-
Output层:通过全连接和径向基函数(RBF)的方式,输出最终的10个分类结果,代表数字0-9。
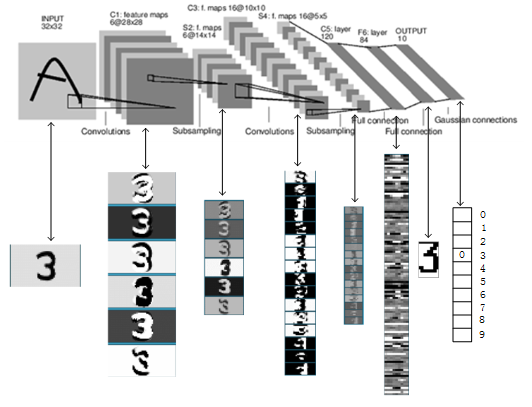
LeNet-5工作原理
二、TextCNN工作原理
TextCNN(Text Convolutional Neural Network):文本卷积神经网络是一种应用于文本分类的卷积神经网络模型。
TextCNN通过多个不同大小的卷积核提取句子中的关键信息,仅包含一层卷积、一层最大池化,最终通过softmax实现多分类。
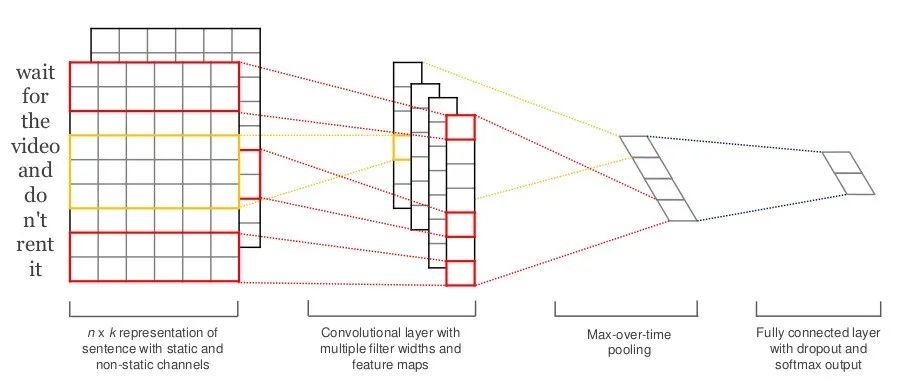
TextCNN
工作原理:TextCNN通过不同大小的卷积核提取文本局部特征,经过最大池化和全连接层后,通过softmax输出分类结果。
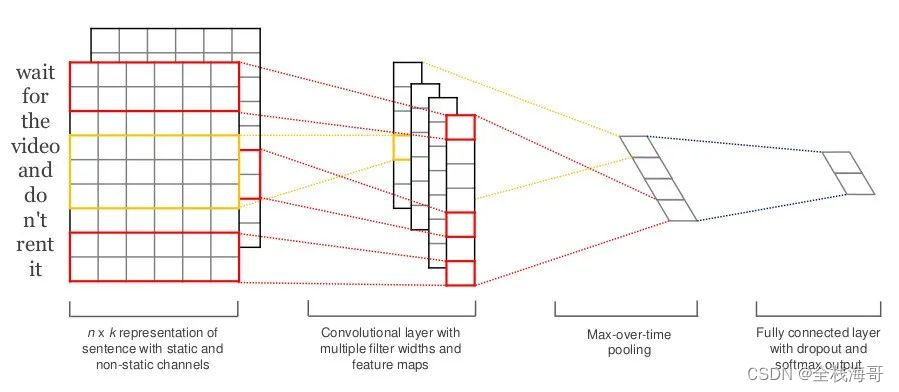
卷积和池化
-
接收输入:TextCNN接收词嵌入向量作为输入,这些向量通常是通过预训练的词嵌入模型(如Word2Vec或GloVe)得到的,它们将文本中的每个单词转换为固定维度的向量。
-
卷积操作:模型使用多个不同大小的卷积核(或称为过滤器)对输入的词嵌入向量进行卷积操作。每个卷积核在输入向量上滑动,进行点积运算,从而提取出局部特征。这些特征可以类比为图像中的边缘或纹理,但在文本中,它们代表了由若干单词组成的滑动窗口内的信息,类似于N-gram。
-
特征图与激活图:卷积操作后,会生成一系列的特征图(feature maps)。每个特征图都包含了输入文本在不同位置上的局部特征信息。然后,通过激活函数(如ReLU)将特征图映射到激活图,进一步增强了模型的非线性表示能力。
-
最大池化:接下来,对每个激活图进行最大池化(max-pooling)操作。最大池化能够提取出每个特征图中的最显著特征,同时使得模型能够处理不同长度的输入文本。经过最大池化后,每个特征图都被转换为一个固定长度的向量。
-
拼接与全连接层:所有经过最大池化后的向量被拼接起来,形成一个单一的向量。这个向量作为全连接层的输入,全连接层进一步对特征进行组合和筛选,最终输出每个类别的概率。
-
分类与输出:在全连接层之后,通常使用softmax激活函数来输出每个类别的概率分布。这样,TextCNN就能够根据输入的文本数据,预测其所属的类别。
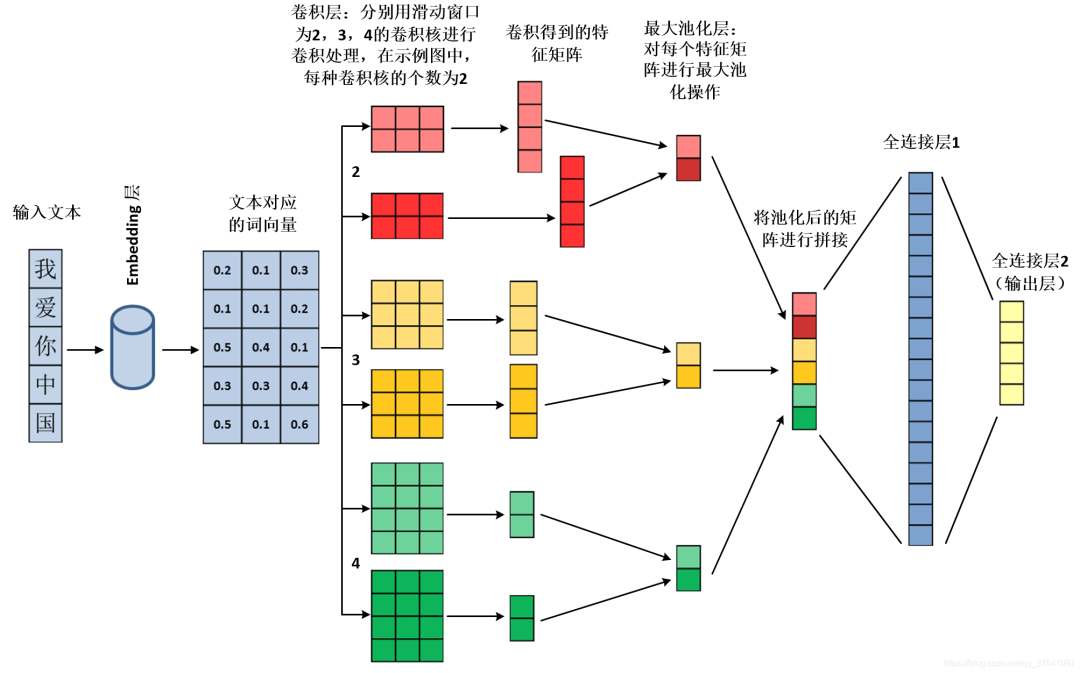
TextCNN工作流程
三、DPCNN工作原理
DPCNN(Deep Pyramid Convolutional Neural Network):深度金字塔卷积神经网络是第一个word level的深层文本分类卷积神经网络,由张潼博士在2017年提出,以其出色的性能在文本分类任务中表现出色。
DPCNN利用深度金字塔结构提升word level CNN的文本分类性能,通过优化网络设计克服了单纯加深网络带来的问题,并充分发挥了CNN的并行计算优势。
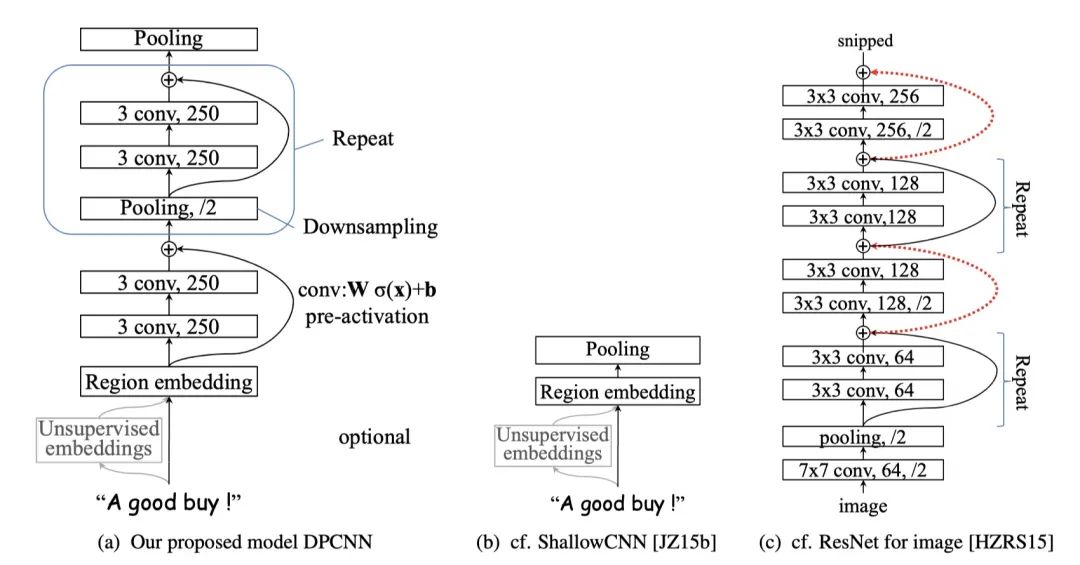
DPCNN(深度金字塔卷积神经网络)
DPCNN通过结合文本区域嵌入、等长卷积块和带有Max-Pooling的Repeat结构,构建了一个高效且强大的深度卷积神经网络,用于文本分类任务。
-
Region Embedding层(文本区域嵌入层):接收word embedding作为输入,通过卷积操作提取文本的局部特征,形成初始表示。
-
Convolution Block(等长卷积块):由两个卷积核大小为3的卷积层构成,执行卷积操作以提取更深层次的文本特征,使用ReLU激活函数,通过pre-activation直接连接,提高信息的流通性。
-
Repeat结构:在等长卷积块的基础上,增加Max-Pooling层进行下采样,捕获更长距离的文本依赖关系。通过重复这种结构,构建深度金字塔网络,提取多尺度特征。
工作原理:文本经Region Embedding后,通过等长卷积块逐层提取特征,经Max-Pooling构建金字塔结构,并利用近路连接确保信息流通,最终输出特征向量用于文本分类。
-
卷积(等长卷积):输入文本经过word embedding后,进入DPCNN的起始层。在等长卷积层中,使用固定大小的卷积核(如size=3)进行卷积操作。卷积操作后,通过ReLU激活函数进行非线性变换。
-
池化(Downsampling and Polling):在每个等长卷积块之后,固定特征图的数量以减少计算量。使用最大池化层进行下采样,池化窗口大小为3,步长为2。池化操作使每个卷积核的维度减半,从而构建一个金字塔形状的网络结构。
-
近路连接(Shortcut Connect):DPCNN借鉴了ResNet中的残差连接思想。在等长卷积块之间使用近路连接,将前一层的输出直接加到后一层的输出上。近路连接中使用的激活函数是线性的,有助于降低计算复杂度。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









