







 超级会员免费看
超级会员免费看
 本文是关于深度聚类的综合调查,详细介绍了深度聚类的代表方法,包括表征学习和聚类模块的设计,如自编码器、生成式模型、互信息最大化和对比学习等。文章还提出了深度聚类的分类,包括多阶段、迭代、生成式和同时深度聚类。此外,讨论了评估指标、应用领域和未来研究方向,如社区检测、异常检测和医疗应用,强调了深度聚类在处理高维数据和复杂关系方面的挑战。
本文是关于深度聚类的综合调查,详细介绍了深度聚类的代表方法,包括表征学习和聚类模块的设计,如自编码器、生成式模型、互信息最大化和对比学习等。文章还提出了深度聚类的分类,包括多阶段、迭代、生成式和同时深度聚类。此外,讨论了评估指标、应用领域和未来研究方向,如社区检测、异常检测和医疗应用,强调了深度聚类在处理高维数据和复杂关系方面的挑战。

文章目录
一:介绍
这一篇2022年发表在arxiv上的综述性论文,对深度聚类提出了一种新的分类方法,同时在github上也总结了部分被引用文献和其程序程序。之前的综述性论文具有代表性的主要是以下三篇
- Elie Aljalbout, Vladimir Golkov, Yawar Siddiqui, Maximilian Strobel, and Daniel Cremers. 2018. Clustering with deep learning: Taxonomy and new methods. arXiv preprint arXiv:1801.07648 (2018)
- Erxue Min, Xifeng Guo, Qiang Liu, Gen Zhang, Jianjing Cui, and Jun Long. 2018. A survey of clustering with deep learning: From
- Gopi Chand Nutakki, Behnoush Abdollahi, Wenlong Sun, and Olfa Nasraoui. 2019. An introduction to deep clustering. In Clustering Methods for Big Data Analytics. Springer, 73–89
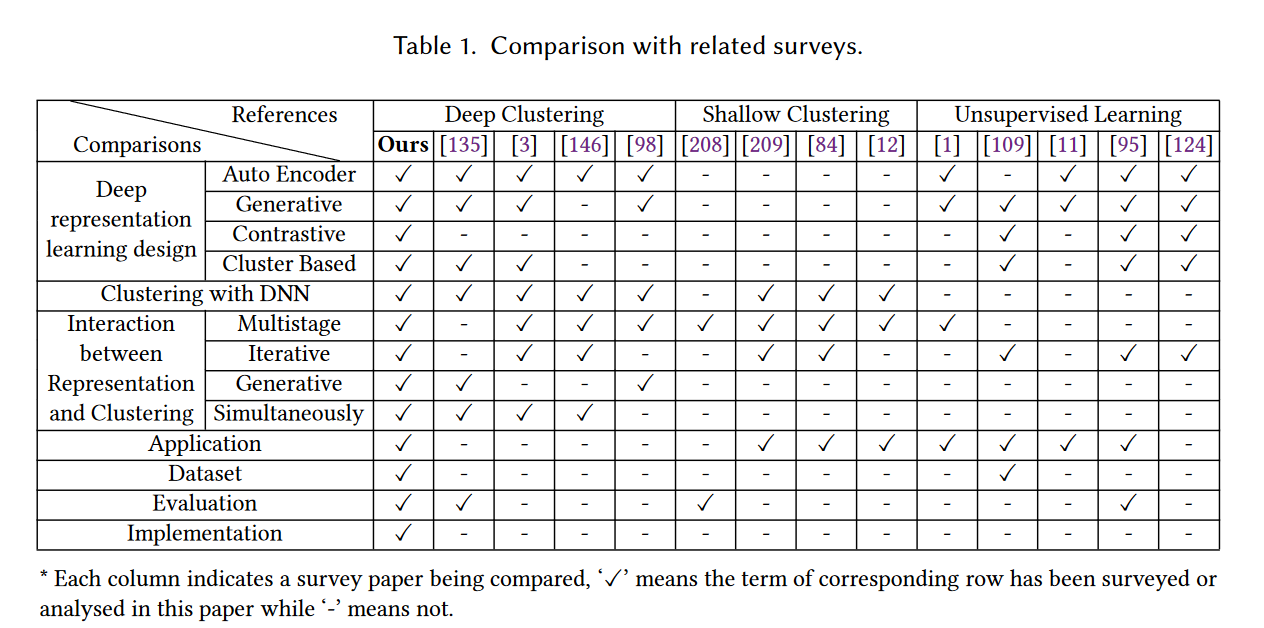
本文相对于这些论文来说介绍的比较全面,如下表,尤其是在应用、数据集和实现方面做了介绍
本文组织方式如下
- section1:介绍
- section2:本文相关的基本定义、符号、概念
- section3 :总结了表征模型的代表性设计、以及不同的数据类型
- 基于自编码器(Auto-Encoder)
- 深度生成式表征学习(Deep Generative Representation Learning)
- 互信息最大化表示学习(Mutual Information Maximization Representation Learning)
- 对比表征学习(Contrastive Representation Learning)
- 聚类友好表征学习(Clustering Friendly Representation Learning)
- 子空间表征学习(Subspace Representation Learning)
- 数据类型特异性表征学习(Data type specific representation learning)
- section4:总结了具有代表性的聚类模块设计,主要集中在深度聚类方法中定义的基本模块
- section5:总结了两个模块之间具有代表性的交互方式,涵盖了大部分现有文献
- section6:介绍了广泛使用的基准数据集和评价指标
- section7:讨论了深度聚类的应用
- section8:讨论了研究的局限性和挑战,并提出了未来值得进一步探索的研究方向
二:解析
ABSTRACT
经典聚类方法缺陷:使用各种表征学习技术将数据以矢量化的形式表示为各种特征,这会导致数据变得十分复杂,所以这些方法难以或无法处理高维数据
深度学习结合聚类的最直接想法:由于近几年来深度学习的巨大成功,特别时在深度无监督学习方面,因此人们始终想要把它应用在聚类上。一个最直接的想法就是:在把数据送入这些传统聚类算法之前,首先进行深度表征,但是这样做有很大问题
- 深度表征并没有直接应用于聚类,这会限制聚类性能
- 聚类依赖于数据之间的关系,是复杂的,并非简单的线性关系
- 聚类和表征学习是独立的,应该相互增强
深度聚类(Deep Clustering):因此为了解决这些问题,深度聚类的概念被提出,它的方法是联合优化表征学习和聚类
INTRODUCTION
深度聚类:近几年来,深度学习技术取得很大成功,但是在聚类技术中应用却不怎么理想,这是因为实例间关系很复杂,模型不好捕获,所以导致聚类的结果不理想。因此,深度聚类其目标是对深度表征学习和聚类的联合优化,它主要回答以下三个问题
- 如何学习能够产生更好聚类效果的判别性表示
- 如何在统一的框架下高效地进行聚类和表征学习
- 如何打破聚类和表征学习之间的壁垒,使他们以交互迭代的方式相互促进
PRELIMINARY
三个基本概念
深度聚类和浅层聚类:
- 浅层聚类:将特征表示作为输入,然后输出每个实例的聚类分配
- 深度聚类:使用深度神经网络处理非结构化数据和高维数据
特别注意:不能将深度聚类狭义的理解为将深度学习技术应用于表征学习,而是指聚类本身就可以通过深度神经网络进行,同时从与深度表征学习的交互中受益
硬聚类与软聚类:
- 硬聚类:硬聚类输出是每个实例 x i x_{i} xi离散的one-hot编码 y ︿ \mathop{y}\limits^{︿} y︿
- 软聚类:软聚类输出时连续的簇分配的概率向量 z i ∈ R K z_{i}\in R^{K} zi∈RK
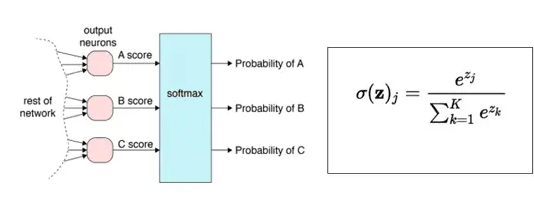
由于实例间的离散分配通常难以优化(特别对具有反向传播的DNN),因此,大多数现存的深度聚类方法属于软聚类范畴,其中,聚类结果由输出为softmax激活的K维深度神经网络 f f f产生
专门用于处理多分类问题,在神经网络的输出层之后,在添加一个softmax层,示意如下
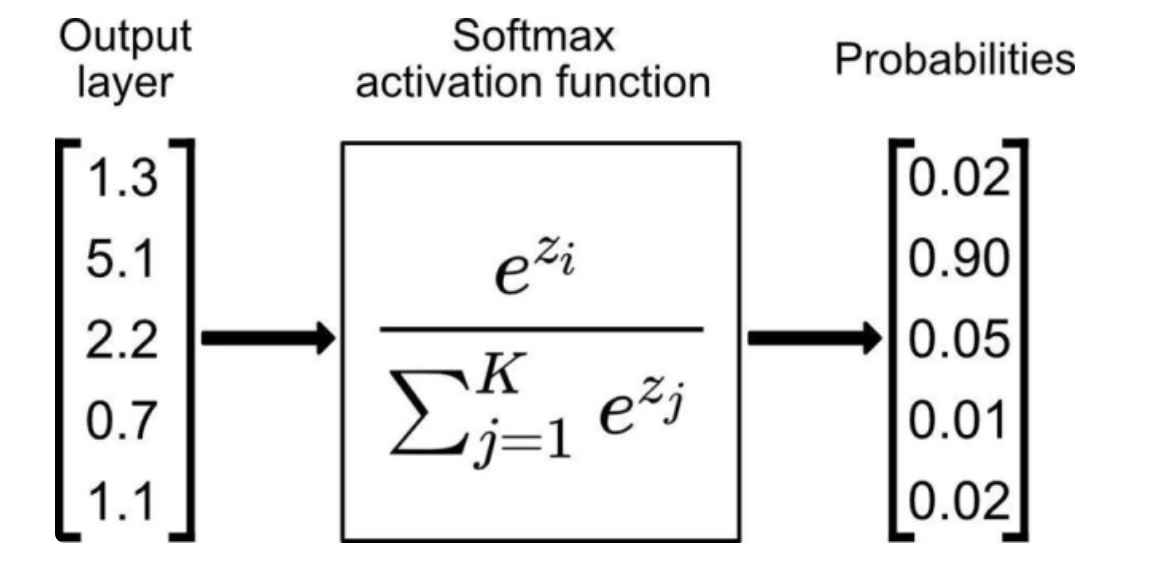
通过softmax函数,将神经元的输出值转换为概率,示意如下
划分聚类和重叠聚类:
- 划分聚类:一个数据实例只能从属于一个簇(硬聚类)
- 重叠聚类:一个数据实例可能会属于多个簇(软聚类)
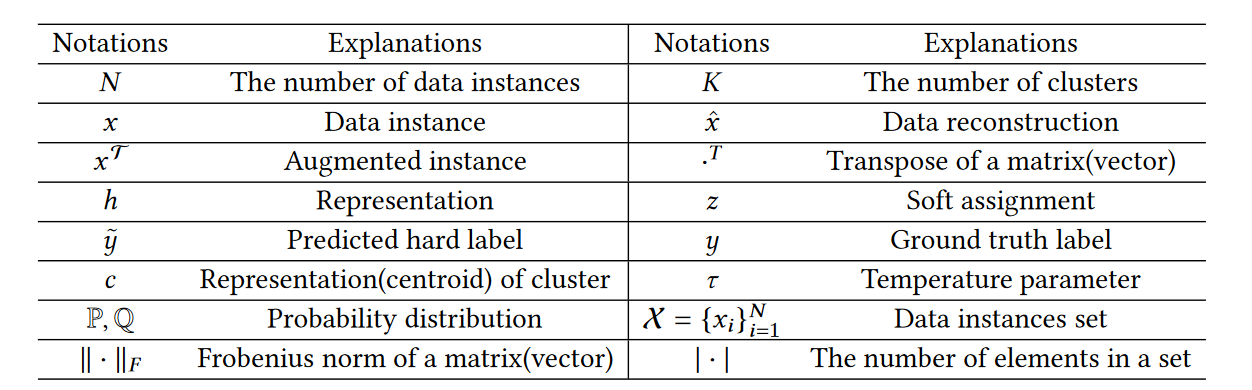
涉及的一些符号
REPRESENTATION LEARNING MODULE
直观上来讲,所有无监督的表征学习方法都可以作为一个输入生成器,直接纳入深度聚类的框架之下,然后现有的大多数方法并不是直接为聚类任务而设计的,所以无法整合潜在的聚类信息来学习更好的表示。这一部分介绍了一些深度聚类中的表征学习模块,它将原始数据作为输入,然后输出低维表示
Auto-Encoder based Representation Learning
自编码器(Auto-Encoder):自编码器是编码器(encoder)和解码器(decoder)两个深度神经网络的线性堆叠
- 编码器 f e f_{e} fe将输入数据 x x x编码为低维表示 h = f e ( x ) h=f_{e}(x) h=fe(x)
- 解码器 f d f_{d} fd将低维表示 h h h解码到输入数据空间 x ︿ = f d ( h ) \mathop{x}\limits^{︿}=f_{d}(h) x︿=fd(h)
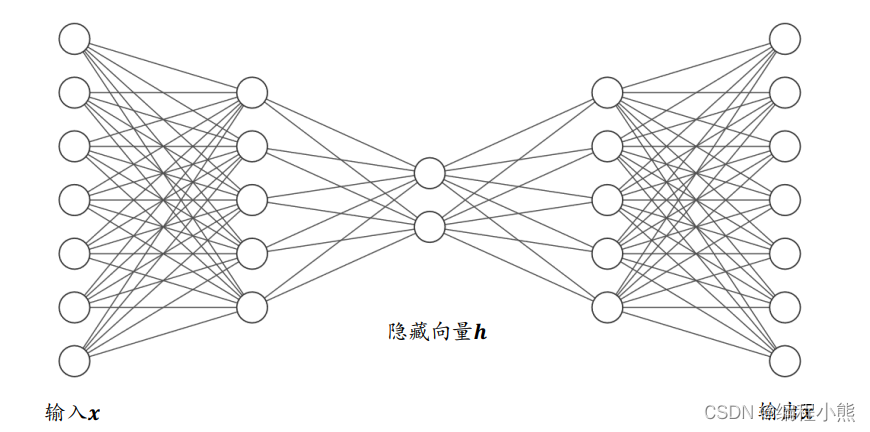
解码器的输出能够完美或近似恢复到原来的输入,所以自编码器优化函数如下图
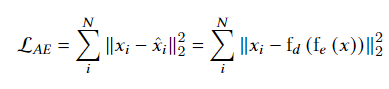
自编码器优缺点:
- 优点:
- 易于实现
- 训练效率高
- 早期深度聚类任务中应用广泛(2012年、2013年)
- 缺点:
- 忽略了不同实例间的关系,所以不能很好的相互区分,导致聚类效果很差
Deep Generative Representation Learning
深度生成式表征学习:生成式方法假设数据 x x x是潜在的表示 h h h生成的,然后从数据逆向推导出表示的后验概率 p ( h ∣ x ) p(h|x) p(h∣x)

变分自编码器(VAE):最典型的深度生成式表征学习方法是变分自编码器(VAE),
深度生成式表征学习优点:深度生成模型具有灵活性、可解释性和能够重新创造数据等优点。所以有希望对深度聚类任务的生成式表示模型进行改造,使聚类模型能够继承这些优点
Mutual Information Maximization Representation Learning
互信息(MI):是度量随机变量
X
X
X和
Y
Y
Y之间相依性的基本量,准确定义是一个随机变量由于已知另一个随机变量而减少的不确定性。举个例子,你问我是哪一年出生的,这时你只能从我的样貌做出大概判断,但是很容易猜错,所以这个答案的不确定性非常大,紧接着我告诉你,我出生在2000年之前,那么这个答案的不确定性就一下降低了,因此这个不确定性减少的量就是互信息大小
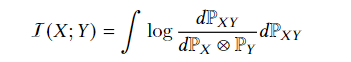
传统的互信息估计仅适用于离散变量或者已知概率分布的情况最近,MINE方法提出,它使用深度神经网络估计互信息。广泛使用的互信息估计是JSD散度
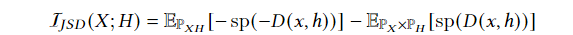
互信息作用:得益于神经网络估计,互信息在无监督学习中得到了广泛应用。具体来说,通过最大化不同层或数据实例的不同部分之间的互信息来进行学习,从而保证了表征的一致性
这可以看作是自监督学习的早期尝试
- 监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。 监督学习需要给数据打标签;而无监督学习不需要给数据打标签。 监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何
- 自监督学习(Self-supervised Learning):是指直接从大规模的无监督数据中挖掘自身监督信息来进行监督学习和训练的一种机器学习方法(可以看成是无监督学习的一种特殊情况),自监督学习需要标签,不过这个标签不来自于人工标注,而是来自于数据本身。自监督学习方法:基于上下文、基于时序、基于对比等
互信息最大化表征学习优缺点:
- 优点: 主要优点在于互信息度量的变量不局限于相同的维度和语义空间
- 缺点: 与自编码器相同,可能也会难以捕获实例之间的关系。但是互信息估计中的边缘分布依赖于所有的观测样本,也即实例之间的关系可以以隐式的方式捕获,这无疑提升了聚类性能
Contrastive Representation Learning
对比学习:其核心思想是把正样本距离拉近,把负样本距离拉远

对比学习在进行训练时会经历如下步骤,以图像数据为例
①:对每个batch中的每张图像进行增广(例如裁剪、调整大小等等),以创建包含两张图像的正对应(postive pair)
②:将他们编码后输入到CNN中学习高阶特征。通过最小化对比损失函数来最大化两个向量之间的相似性
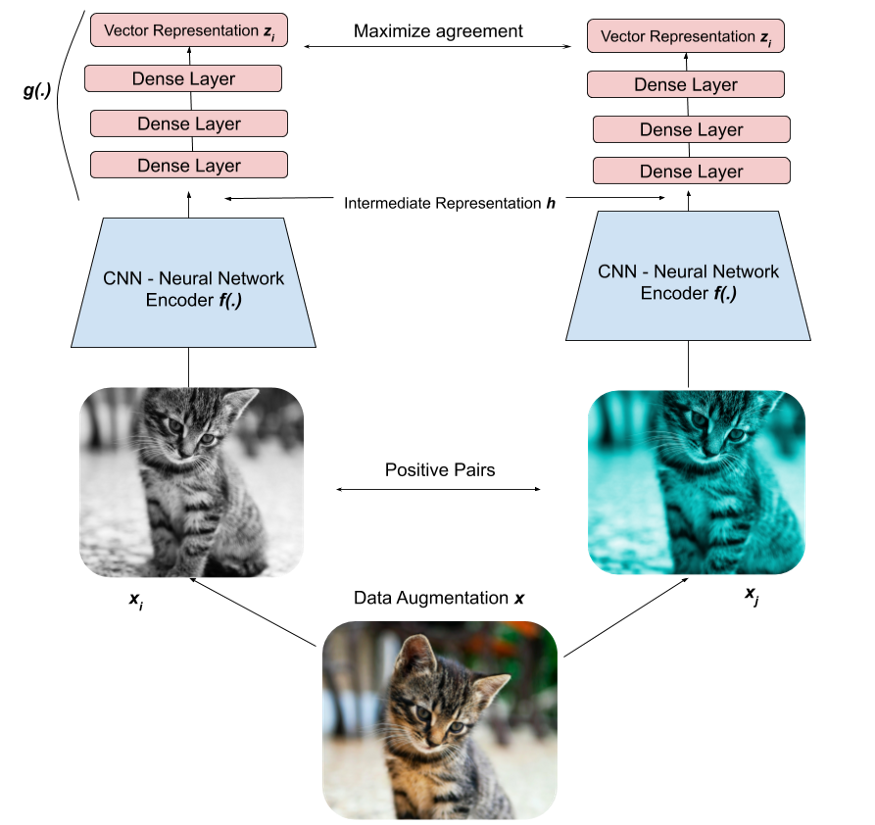
infoNCE损失函数: f ( ) f() f()为相似度度量函数,分子部分表示正例之间的相似度,分母部分表示正例与负例之间的之间的相似度,因此相同类别相似度大,不同类别之间相似度小,损失就会越小
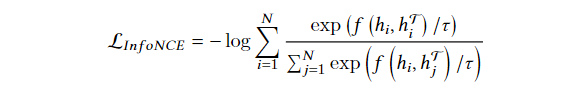
其中 τ \tau τ为温度系数,用于控制模型对负样本的区分度。 τ \tau τ越大会使模型学习没有轻重, τ \tau τ越小会使模型很难收敛或泛化能力差
对比学习优点:大量证据表明,通过对比学习到的特征能够对聚类任务带来好处
- 对比学习的对齐属性促使具有相似特征或语义类别的样本在低纬空间中接近,这对聚类任务很重要
- 已经证明最小化InfoNCE损失等价于最大化互信息下界,同时互信息最大化中不需要考虑数据增广。数据增广在连接同一类别中的实例时起到了阶梯作用,所以来自同一簇的实例很可能会被拉近
Clustering Friendly Representation Learning
聚类友好表征学习:前面所介绍的模型虽然在某些方面能够提升聚类性能,但它们并不是专门为聚类任务而设计的。论文介绍了K-Means和谱聚类友好表征
- 优点: 它得益于对聚类的直接优化,可以显著提高相应聚类性能
- 缺点: 这种建议性限制了其对其他聚类方法的推广
目前,我们更多将精力放在聚类方法启发上,并以深度学习视角进行表达,而不是针对每种聚类方法学习特定的表征
Subspace Representation Learning
子空间表征学习:子空间表示学习是子空间聚类的早期阶段,其目的是将数据实例映射到一个低维子空间中,在这个子空间中实例可以被分离
它有很强大的理论保证,提供了数据实例之间关系的建模。但其主要问题还是在计算困难
Data type specific representation learning
数据类型特异性表征学习: 前面总结了表征学习的一些通用结构,在实际场景中,针对不同的数据类型就需要对这些结构进行设计(变体)。主要有以下数据类型
- 图像表征学习:
- 以CNN和ResNet为骨干的图像表征学习在过去十几年来取得了巨大的成功
- 在图像深度聚类中它们仍然作为特征提取器或表征学习模块的骨干发挥着重要的作用
- 现在最近的趋势是将vision transformer引入深度聚类
- 文本表征学习:
- 早期尝试是基于统计的学习方法
- 之后工作集中在主题模型和语义距离以及更多的无监督场景
- 现在,预训练语言模型例如BERT和GPT-3在文本表征学习中占据主导地位
- GPT是”GenerativePre-trainedTransformer“生成型预训练变换模型的缩写,目的是为了使用深度学习生成人类可以理解的自然语言
- 例如如今大火的chatGPT
- 视频表征学习:
- 视频表征学习很具有挑战性,它将时空学习、多模型学习和NLP结合在一起
- 最近的方法主要集中在时空建模,特别是结合对比学习进行自我监督
- 图表征学习:
- 经典的图表征学习目的是为节点学习到低维表示,使得节点之间的邻近性能够在嵌入空间中得到保留
- 图神经网络(GNN)的广泛应用为结合节点特征和图拓扑结构的图节点表征学习带来了无限可能
CLUSTERING MODULE
- 这一部分介绍了深度聚类中具有代表性的聚类模块,将矢量化后的特征通过送入深度神经网络,将维度降至聚类数k,然后在最后一层应用softmax函数,从而建立赋值分布
- 核心要做到
- 能够在统一的框架下用深度表征学习进行训练
- 聚类过程与表征学习模块要进行交互,相互增强
- 尽管K维表示是以概率分布的形式表示的,但是它们可能无法表示没有显示约束的簇分布,所以会导致所有实例被分配到同一个簇的退化问题
- 图3
Relation Matching Deep Clustering
关系匹配深度聚类:在深度聚类中,每个数据实例可以表示在两个空间中,即 d d d维嵌入空间和 K K K维标签空间。我们期望在降维过程中,数据实例之间的关系能够保持一致,这能弥合表征学习和聚类过程中的鸿沟
**借鉴领域自适应思想(domain adaptation),关系匹配可以通过双向的方式实现
- l l l是关系匹配的度量方式,例如可以用余弦相似度或欧氏距离等
- R s R^{s} Rs和 R t R^{t} Rt指的是源空间和目标空间,它们既可以是嵌入空间也可以是标签空间
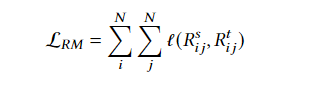
领域自适应:领域自适应是一种机器学习技术,通过利用源领域的知识并对目标领域进行微调,将在一个领域(源领域)上训练的模型适应到另一个相关但不同的领域(目标领域)。领域自适应的目标是通过从标记数据丰富的源领域迁移知识,提高模型在标记数据稀缺或不可用的目标领域上的性能。这对应迁移学习
在深度聚类中,域适应的思想可以通过以下步骤应用在迁移学习中:预训练:首先使用大量有标签数据在源域上预训练模型。预训练阶段学习数据的高层表示
特征提取:使用预训练模型从目标域数据中提取特征,然后在目标域上对预训练模型进行微调
聚类分配:然后使用提取的特征使用无监督聚类算法如k - means或高斯混合模型将数据点分配到不同的簇
微调:最后,基于簇分配更新模型参数,在目标域上对模型进行微调。该阶段对模型进行微调,以更好地拟合目标域数据
优缺点:
优点:
- 关系匹配深度聚类明确地将表征学习和聚类联系在一起,简单易实现
- 通过将源域的知识与目标域的信息相结合,域适应可以提高目标域上深度聚类的性能。当标记数据在目标域中稀缺且可以从相关的源域中利用时,这一点尤其有用
缺点:
- 计算低效, 需要计算
N
2
N^{2}
N2对实例之间的关系
- 为了应对这一挑战,一些方法只保留每个实例的k近邻关系或者高置信度的关系
- 额外的超参数很难以无监督方式设置
- 存在噪声干扰,特别在训练早期阶段,会限制性能
Preudo Labeling Deep Clustering
半监督学习(semi-supervised learning): 第七章第一节:半监督聚类算法概述
伪标记(Preudo labeling):伪标记是深度学习中的一种半监督学习技术,其中模型在标记数据集上进行训练,然后该模型用于预测未标记数据集的标签。然后将来自未标记数据集的预测标签用作伪标签,并添加到原始标记数据集中以进一步训练模型
伪标记深度聚类:标签可以看做是另一种类型关系匹配,其关系是离散的。伪标签深度聚类结合了这两种技术,通过使用从深度聚类模型生成的伪标签来提高深度学习模型的性能。深度聚类模型用于提取特征和识别数据的结构,预测的聚类分配用作伪标签来训练深度学习模型
根据使用伪标记方式的不同,分为两类
-
基于实例的伪标记:过滤掉高置信度的实例子集,以交叉熵损失的监督方式训练网络
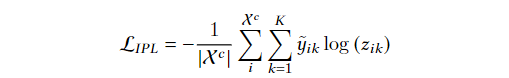
-
基于关系的伪标记:在嵌入空间中强制具有相同伪标签的实例相互靠近,而具有不同伪标签的实例相互远离,会构建必连约束集和勿连约束集进行学习
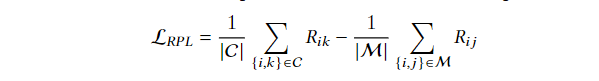
优缺点:
优点:
- 将半监督学习的优势带入了无监督学习任务中
缺点:
- 性能高度依赖于过滤伪标签的质量,而它有容易受到模型能力和超参数调整的影响
目前的方法已经将预训练作为伪标记前的早期阶段
Self-training Deep Clustering
自训练深度聚类:自训练深度聚类 (STDC) 是一种结合无监督聚类和自训练以提高聚类性能的深度学习方法。该方法首先使用无监督聚类技术初始化数据的聚类,然后使用深度神经网络学习从输入数据到聚类分配的映射。然后使用网络的预测来更新聚类分配,这些分配又用于进一步微调网络。重复这个过程直到收敛,产生一个深度聚类模型,可以有效地将输入数据聚类成有意义的组
具体来讲,通过最小化带有辅助分配的KL散度来优化簇分配分布
- Q Q Q是聚类分配分布; P P P是辅助分配
- q i k q_{ik} qik和 p i k p_{ik} pik是 x i x_{i} xi属于 k k k的概率
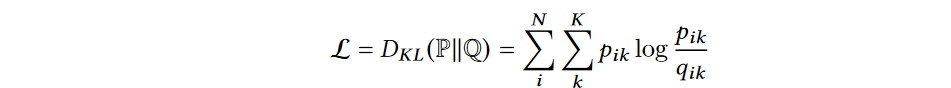
分布 Q Q Q遵循K-Means假设,由实例和聚类中心的嵌入距离产生
- h i h_{i} hi是数据实例 h i h_{i} hi的表示
- c k c_{k} ck是是簇 k k k的表示
- α \alpha α是 t t t-分布的自由度
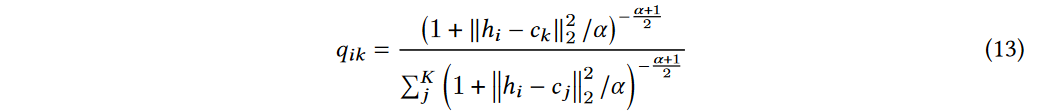
辅助分布 P P P分布 Q Q Q的变体,其中 f k = ∑ i N q i k f_{k}=\sum_{i}^{N}q_{ik} fk=∑iNqik是软聚类频率,可以看做是实例属于第 k k k个类的概率之和
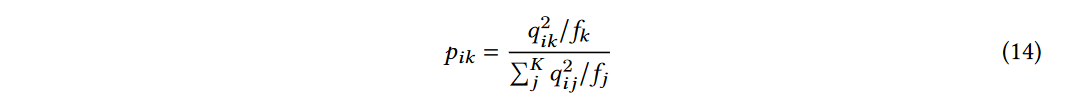
优点:自训练深度聚类应用很广泛,许多深度聚类方法都可以看做是它的变体,其成功主要归结于以下两点
- 具有簇归一化的簇分配概率的平方可以将更多的梯度放在置信度较高的实例上,进而降低置信度较低的实例的影响——聚类分配向量会趋向于one-hot
- f k f_{k} fk可以看做是实例属于第 k k k个类的概率之和,可以避免所有实例属于同一簇这种退化现象的产生
Mutual Information Maximization based Clustering
互信息最大化聚类:得益于互信息最大化表征学习的优点,因此被引入到聚类模块中用于度量实例与聚类分配之间的依赖关系
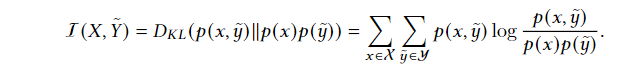
优点:
- 其主要优点是克服了表示学习和聚类之间的鸿沟。因此,深度表示学习技术的快速发展可以自然地引入到聚类任务中,并在统一的框架下进行优化
- 可以应用在各种数据类型中
- 特别适合高纬数据
Contrastive Deep Clustering
对比深度聚类:与对比表征学习的思想一致,即把正样本距离拉近,把负样本距离拉远。根据对正对和负对定义的不同,可以进一步划为三组
①:instance-instance contrast:将每个实例的聚类分配作为表示,直接重用对比表示学习损失
- z i z_{i} zi为由模型预测的实例 x i x_{i} xi的簇分配
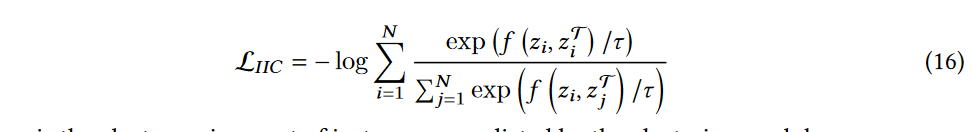
②:cluster-cluster contrast:将每个簇视为嵌入空间中的实例,目标是将簇及其增广版本拉近,同时将不同簇推远,可表示为
- c k c_{k} ck是簇 k k k
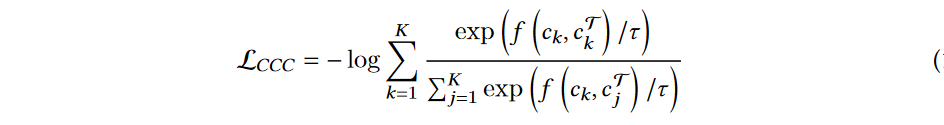
③:instance-cluster contrast:它类似于K-Means,使用聚类中心作为指导。给定每个实例和聚类中心在同一低维空间中的表示,每个实例期望靠近对应的聚类中心而远离其他聚类中心
- c i ‘ c_{i}^{`} ci‘是 x i x_{i} xi对应的聚类中心
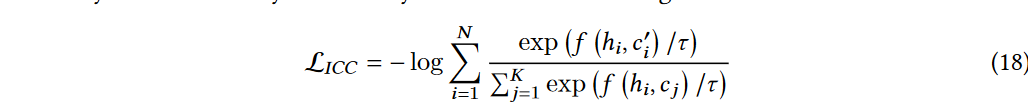
优点: 除了从互信息最大化聚类中继承的优点外,对比深度聚类的主要优点是数据增广有助于提高聚类的鲁棒性,这被大多数现有方法所忽略
TAXONOMY OF DEEP CLUSTERING
Multi-stage deep clustering
多阶段深度聚类(Multi-stage deep clustering):是指两个模块分别优化并依次连接的方法。一个很直接的方法就是首先利用深度学习对个数据实例进行表征,然后将其输入到经典的聚类模型中。这种数据处理与聚类分离便于进行聚类分析
- 早期阶段:通过训练一个深度自编码器来学习表示,然后将其直接打包作为K-Means输入来进行聚类
- 之后:深度子空间聚类被提出,他们学习一个亲和度矩阵(affinity martix)和实例表示,然后对该矩阵进行谱聚类或对实例表示进行K-Means聚类
- 最近:明确将聚类先验(clustering prior)融入到表征学习中,然后对目标友好表示进行聚类
优缺点:
优点:
- 可以快速部署
- 编程方便
- 理解直观
缺点:
- 聚类反映了数据实例之间的全局模式,但现有表示方法很大程度上只关注个体模式
- 聚类结果不能进一步用于指导表征学习,因为聚类结构隐含了数据实例之间的内在关系,所以反过来可以作为表征学习的关键指导
总之: 这种直接的连接切断了表征学习和聚类之间的信息流和交互,因此会对聚类性能产生很大影响
Iterative Deep Clustering
迭代深度聚类(Iterative deep clustering):核心思想就是好的表示可以帮助聚类,同时聚类结果反过来又可以为表征学习提供指导。现存迭代深度聚类方法会进行如下两步迭代
- step1:计算在当前给定表示下的聚类结果
- step2:更新在当前给定聚类结构下的表示
由于表征模块只向聚类模块提供输入,所以根据聚类模块提供的信息对方法分类
- 具有个体监督的迭代深度聚类。(Iterative deep clustering with individual supervision):依赖于聚类模块生成的伪标签,,所以可以利用伪标签以监督方式训练表征学习模块
- 早期阶段:以K - means方式更新聚类中心和划分
- 之后:倾向于使用神经网络进行表征学习和聚类,将这两部分结合在一起作为一个神经网络。聚类模块通常是产生软聚类分配的多层感知器( MLP )。这样,硬伪标签就可以通过适当约束的梯度反向传播来指导聚类和表示学习
- 最近:使用带微调的预训练框架,通过自标记对聚类结果进行微调,通过调节软聚类分配概率选择高置信度实例,然后最小化所选实例上的交叉熵损失来更新网络
- 具有关系监督的迭代深度聚类(Iterative deep clustering with relational supervision): 这种关系通常通过实例是否具有相同的离散的伪标签来建模,并将模型训练为一个二分类任务
优缺点:
优点:
- 能够很好地让表征学习和聚类相互促进
缺点:
- 容易受到迭代过程中误差传播的影响,不准确的聚类结果将会导致表示也混乱
- 反过来会影响聚类结果,尤其是在训练早期阶段,现有的迭代聚类方法严重依赖表征模块的预训练
Generative Deep Clustering
生成式深度聚类(Generative Deep Clustering):生成模型能够捕获、表示和重建数据点,所以这几年来研究十分火热。它对潜在的聚类结果作出假设,然后通过估计数据密度来推断聚类分配。最具代表性的是高斯混合模型(GMM)。假设有K个簇,由以下过程生成一个观测样本(上图)。通过期望最大化算法来学习最优参数和聚类分配
但是高斯混合模型不易于捕获复杂数据的结构,为了这个问题。深度生成模型便结合了生成模型和神经网络。分为如下两类
- 基于变分自编码器(VAE):一个想法就是直接将GMM与深度神经网络进行堆叠,GMM产生一个潜在向量,深度神经网络进一步将潜在向量转换为复杂的数据实例。通过这样的方式,堆叠模型可以发挥潜在簇结构的优点,同时具有对复杂数据建模的能力
- 基于生成对抗网络(GAN):生成器可以生成与数据分布相似的样本,因此将GAN集成到生成聚类模型是很有前途的
- 关于GAN
优缺点:
优点:
- 可以在完成聚类的同时生成样本
缺点:
- 训练一个生成模型通常包括蒙特卡罗采样,可能会导致训练不稳定或高计算复杂度
- 继承了VAE和GAN的缺点
- 基于VAE的需要对数据分布进行预先假设,这在实际案例中可能不太行
- 基于GAN的虽然灵活,但存在训练容易崩溃和收敛速度慢的问题,尤其是当簇数目多时
Simultaneous Deep
同时深度聚类(Simultaneous Deep Clustering):这个方向现在比较活跃,其中表征学习模块和聚类模块以端到端方式同时优化,而iterative deelp clustering中两个模块是以显式的方式进行优化,不能同时更新
- 具有自训练的自编码器(Auto-encoder with self-training):
- 代表性论文:“Unsupervised deep embedding for clustering analysis.”(DEC)
- 该方法将自动编码器与自训练策略相结合。这种简单而有效的策略对后续工作产生了深远的影响。自动编码器是预先训练的,只有编码器被用作表示学习模块的初始化
- 基于互信息最大化聚类(Mutual Information Maximization basedClustering):
- 代表性论文:“Deep comprehensive correlation mining for image clustering” (DCCM)
- 对于每一个数据实例,最大限度地利用了深、浅层表示之间的互信息,从而保证了表示的一致性。 通过鼓励具有相同伪标签的实例共享相似的表示,这种一致性进一步扩展到聚类分配空间
- 对比深度聚类(Contrastive Deep Clustering):
- 代表性论文:“Contrastive clustering”(CC)
- 其基本思想是将每个聚类看作是低维空间中的数据实例。 通过区分不同的聚类,将对比表征学习中的实例判别任务迁移到聚类任务中,这是聚类的基本要求
- 混合深度聚类(Hybridsimultaneous deep clustering): 对于上述进行混合,比如把对比表征学习和自训练混合、关系匹配伪标签混合等等
优缺点:
优点:
- 它是面向聚类的,聚类是在判别空间上进行的
缺点:
- 表征学习模块和聚类模块之间可能存在优化重点的偏差,目前只能通过手动设置平衡参数来缓解这种偏差
- 该模型很容易陷入退化的解决方案,其中所有实例都被分配到单个集群中
总结
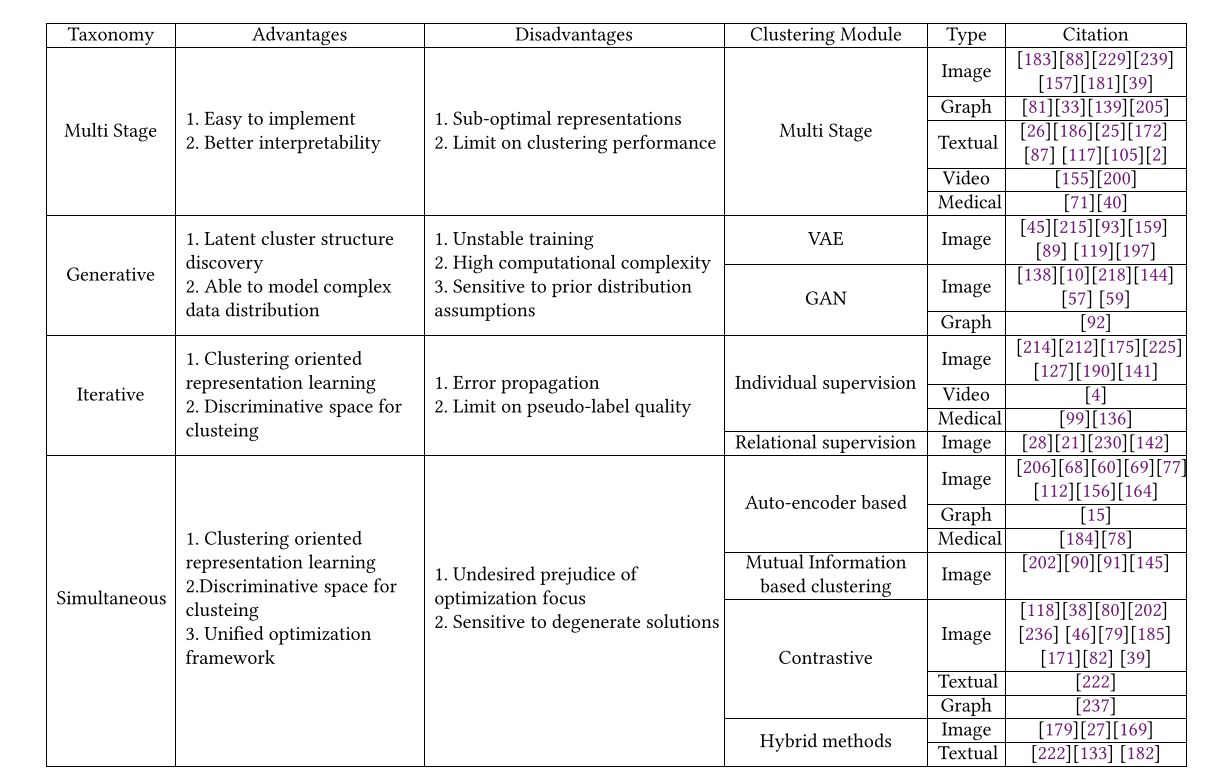
DATASETS AND EVALUATION METRICS
Datasets
- Image Datasets:
- 早期工作主要在以下数据集上尝试
- COIL-20:COIL-20数据集是一个用于对象识别的图像数据集,全称为Columbia Object Image Library 20。它由20种不同物品的72个不同视图组成,每个视图包含128x128像素的彩色图像。数据集的目的是帮助研究者评估对象识别算法的性能,特别是针对受限的视角、尺寸和旋转变换的识别任务COIL-20数据集非常适合用于计算机视觉研究和机器学习,尤其是对象识别和图像分类任务。由于数据集的小规模和简单的物体,它通常用作机器学习模型的基础数据集,以帮助研究者评估新的算法和技术
- CMUPIE:CMU-PIE(Carnegie Mellon University Pose, Illumination, and Expression)是由卡内基梅隆大学开发的一个人脸数据集。该数据集包含了多种姿势、照明和表情的人脸图像,共有41个类别,每个类别有71个样本。CMU-PIE数据集是用于人脸识别、人脸对齐和人脸表情识别等方面的研究。它提供了一个丰富且多样化的人脸图像数据集,对于研究人脸识别算法和人脸表情识别算法具有很大的价值
- Yale-B:Yale Face Database B(也称为耶鲁人脸数据库)是一组广泛用于计算机视觉和模式识别研究的人脸图像。它是在耶鲁大学收集的,由 15 个人的 165 张灰度图像组成,每个人有 11 种不同的面部表情或配置。Yale Face Database B 中的图像分辨率为 192 x 168 像素,并且它们是在受控照明条件下拍摄的,以减少照明对人脸识别性能的影响。人脸配置包括不同的姿势、表情和光照条件,使其成为测试人脸识别算法鲁棒性的具有挑战性的数据集。Yale Face Database B 已被广泛用于对各种人脸识别算法的性能进行基准测试,并且它仍然是该领域研究人员的热门数据集
- MNIST:MNIST(Modified National Institute of Standards and Technology)是一个手写数字识别数据集,是机器学习和深度学习领域中常用的训练和测试数据。它包含了 60,000 张训练图像和 10,000 张测试图像,每个图像都是 28x28 像素的黑白图像,包含 0 到 9 之间的一个数字。MNIST 数据集是用来评估机器学习算法的基准数据集,是许多研究人员的首选数据集,因为它是一个简单且相对较小的数据集,适合用来快速评估算法的性能。同时,由于它的简单性,它也是一个很好的入门数据集,用于教学机器学习和深度学习技术
- CIFAR:CIFAR (Canadian Institute For Advanced Research) 数据集是一组用于计算机视觉任务的常用数据集。它包含了三个不同的数据集:CIFAR-10、CIFAR-100和CIFAR-100( fine-grained)。CIFAR-10数据集包含了10个不同的类别,每个类别中都有6,000张32x32彩色图像。这些图像可以用来训练机器学习模型,并且在图像识别任务中被广泛使用。CIFAR-100数据集类似于CIFAR-10,但包含了100个不同的类别,每个类别中都有600张32x32彩色图像。它比CIFAR-10更具挑战性,因为它涵盖了更多的类别和更多的图像
- STL-10:STL-10数据集(Standford Tiny Images)是一个图像分类数据集,其中包含了10个类别,每个类别有5,000张图像,总共有50,000张图像。它是由Standford大学的 Fei-Fei Li 等人创建的,旨在评估小型图像分类模型的性能。图像类别包括:飞机,自行车,鸟,猫,鹿,狗,马,船,卡车和车。数据集由很多高质量的小图像组成,每个图像大小为96x96像素。因此,STL-10数据集可以用作小型图像分类模型的评估基线
- 现在工作主要在像ImageNet这样的大型数据集上进行
- ImageNet是一个大型的图像数据库,用于计算机视觉方面的研究和评估。它由1400万张图像组成,图像被标记为1000个不同的类别,包括动物,物品,自然环境等。这个数据集的重要性在于,它是当前最流行的图像分类任务的标准数据集,并且被广泛用于许多计算机视觉和深度学习方面的研究。ImageNet数据集自2010年开始每年举办一次图像识别比赛,称为ImageNet大规模计算机视觉挑战赛(ILSVRC),主要目的是评估不同的计算机视觉技术和算法的性能
- 早期工作主要在以下数据集上尝试
Evalutaion Metrics
Accuracy(精确度):是指聚类样本的平均正确分类率
- 真实标签: Y = { y i ∣ 1 ≤ i ≤ N } Y=\{y_{i}|1\leq i\leq N\} Y={yi∣1≤i≤N}
- 预测的硬标签: Y ︿ = { y i ︿ ∣ 1 ≤ i ≤ N } \mathop{Y}\limits^{︿}=\{\mathop{y_{i}}\limits^{︿}|1\leq i\leq N\} Y︿={yi︿∣1≤i≤N}
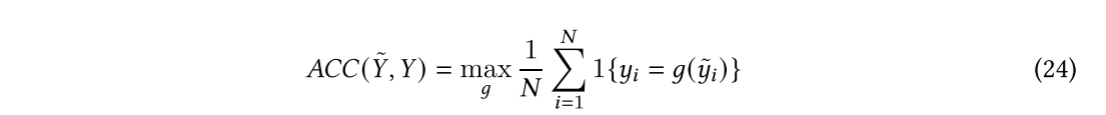
Normalized Mutual Information(归一化互信息):将预测标签和真实标签之间的互信息化到[0,1]
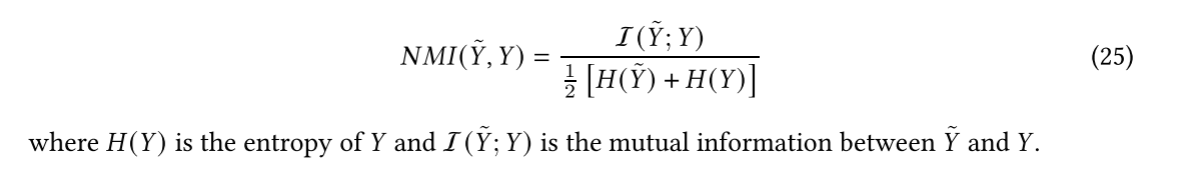
Adjusted Rand Index(调整的兰德指数):
兰德指数:其取值范围为[-,1],1表示聚类效果与真实分类结果完全相同,0表示聚类效果与随机分类效果相同,-1表示聚类效果与真实分类结果完全相反。具体来讲,它通过比较聚类算法得到的聚类结果与真实分类之间的共同点和差异点来计算,其中
- 共同点包括同类别的数据点被分到同一簇的个数和不同类别数据点被分到不同簇的个数
- 差异点包括同类别的数据点被分到不同簇的个数和不同类别数据点被分到同一簇的个数
如下
- a表示同类别的数据点被分到同一簇的个数,b表示不同类别的数据点被分到不同簇的
- c表示同类别的数据点被分到不同簇的个数,d表示不同类别的数据点被分到同一簇的
R I = a + b a + b + c + d RI=\frac{a+b}{a+b+c+d} RI=a+b+c+da+b
调整的兰德指数:是兰德指数的一个修正版本。与RI相比,ARI对于聚类数量和随机分配簇标签的不敏感问题进行了修正,同时考虑了数据集本身的类别分布情况。具体来说,ARI引入了一个调整因子,惩罚随机分配簇标签所带来的影响,同时考虑了真实分类中不同类别的数据点数量和聚类结果中不同簇的数据点数量
- E ( R I ) E(RI) E(RI):随机分配标签时所期望的PU
-
m
a
x
(
P
I
)
max(PI)
max(PI):是RI的最大值
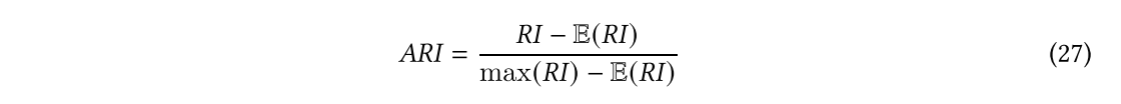
APPLICATIONS
- Community Detection(社区检测):根据连接密度将图网络划分为几个子图,可视为节点级图的聚类任务(GNN)
- Anomaly Detection(异常检测):是一种识别数据中异常实例或模式的技术
- Segmentation and Object Detection(分割与目标检测):其目的是将像素分割成不相连的区域,图像分割就是对像素进行有监督的分类,对像素进行无监督的聚类
- Medical Applications(医疗应用):卷积神经网络以一种监督的方式成功地推动了医学图像处理的发展。然而,人工数据集标注过程往往是劳动密集型的,需要专家医学知识,在现实场景中很难实现,深度聚类被引入到大规模医学图像的自动分类中
FUTURE DIRECTIONS
- Initialization of Deep Clustering Module(深度聚类模块初始化) :深度神经网络的初始化通常对训练效率和稳定性起着重要作用。这在表示学习模块和聚类模块都由深度神经网络建模的深度聚类中更为关键
- Overlapping Deep Clustering(重叠深度聚类):本文讨论的深度聚类方法主要集中在划分聚类上,每个实例只属于一个聚类。同时,在真实世界场景中,每个实例可以属于多个集群,例如社交网络中的用户可以属于多个社区,并且社交媒体中的视频/音频可以具有多个标签
- Degenerate Solution VS Unbalanced Data(退化解VS不平衡数据):是指在深度聚类中,所有实例都可以分配到一个集群中。许多深度聚类方法都加入了额外的约束条件来克服这个问题,其中聚类大小分布的熵是应用最广泛的一种。通过最大化熵,期望实例被均匀地分配到每个簇,避免退化到单个簇
- Boosting Representation with Deep Clustering(深度聚类增强表示) :虽然已有文献对聚类友好表示学习进行了研究,但它们都是针对特定的浅聚类方法而设计的
- Deep Clustering Explanation(深度聚类解释) :作为一个人监督的任务,聚类过程通常缺乏人类先验知识,如标签语义、聚类数量,这使得聚类结果难以解释或理解
- Transfer Learning with Deep Clustering(深度聚类迁移学习) :迁移学习的目的是通过分布偏移来弥补训练数据集和测试数据集之间差距。其基本思想是将已知数据的知识转化为未知测试数据的知识
- Clustering with Anomalies(异常聚类) :如何提高深度聚类对异常实例的鲁棒性,并通过减少检测到的异常实例来逐步提高聚类性能仍是一个有待解决的研究问题
- Efficient Training VS Global Modeling(高效训练VS全局建模):为了提高训练效率和可扩展性,现有的深度聚类方法大多采用小批量训练策略,将实例划分为多个批次,每批更新一次模型。这适用于实例彼此独立的任务,如分类和回归。然而,由于深度聚类严重依赖于实例之间的复杂关系,这种小批量训练可能失去全局建模能力
三:总结
文章总结:
- 本文对深度聚类进行了全面的综述,包括不同先进方法的新分类。
- 总结了深度聚类的基本组成部分,并根据现有方法设计深度表示学习和聚类之间的交互的方式对现有方法进行了分类。
- 本文还讨论了深度聚类的实际应用,并提出了未来值得进一步研究的挑战性课题


















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











