







光线求交加速算法:边界体积层次结构(Bounding Volume Hierarchies)3
尽管使用表面积启发式方法(SAH)构建边界体积层次结构会产生很好的结果,但是该方法确实存在两个缺点:首先,对场景图元进行了多次遍历,才能计算树的所有级别上的SAH成本。其次,自上而下的BVH构造很难很好地并行化:因为构造子树需要其父辈结点都创建完成,所以无法并行的构造子树。
LBVH(Linear Bounding Volume Hierarchies)
线性边界体积层次结构(LBVH)可以用来来解决这些问题。使用LBVH,可以通过在图元上进行少量轻量级传递来构建树。树的构建时间与基元数量成线性关系。此外,该算法将图元快速划分为可以独立处理的簇。此处理可以相当容易地并行化,非常适合GPU实现。LBVH背后的关键思想是将BVH的构造变成一个分类问题。由于不存在用于对多维数据进行排序的单一排序功能,因此LBVH基于Morton编码,该编码将n维中的附近点映射到沿一维线的附近点,这样可以非常简单的进行排序。在对图元进行排序之后,图元在空间上附近的簇位于已排序数组的连续段中。
Morton编码基于简单的变换:给定n维整数坐标值,通过对二进制中的坐标位进行交织来找到它们的Morton编码表示形式。例如,考虑2D坐标(x,y),其中x和y的第i位二进制由和
表示。相应的Morton编码值是:
![]()
下图以Morton顺序显示了2D点:
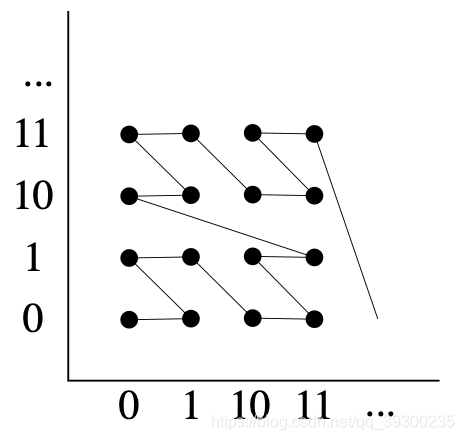
沿x和y轴的坐标值以二进制显示。如果我们按照整数坐标点的Morton索引的顺序连接它们,则会看到Morton曲线沿着“ z”形分层路径访问这些点,因此Morton路径有时称为“ z阶”。
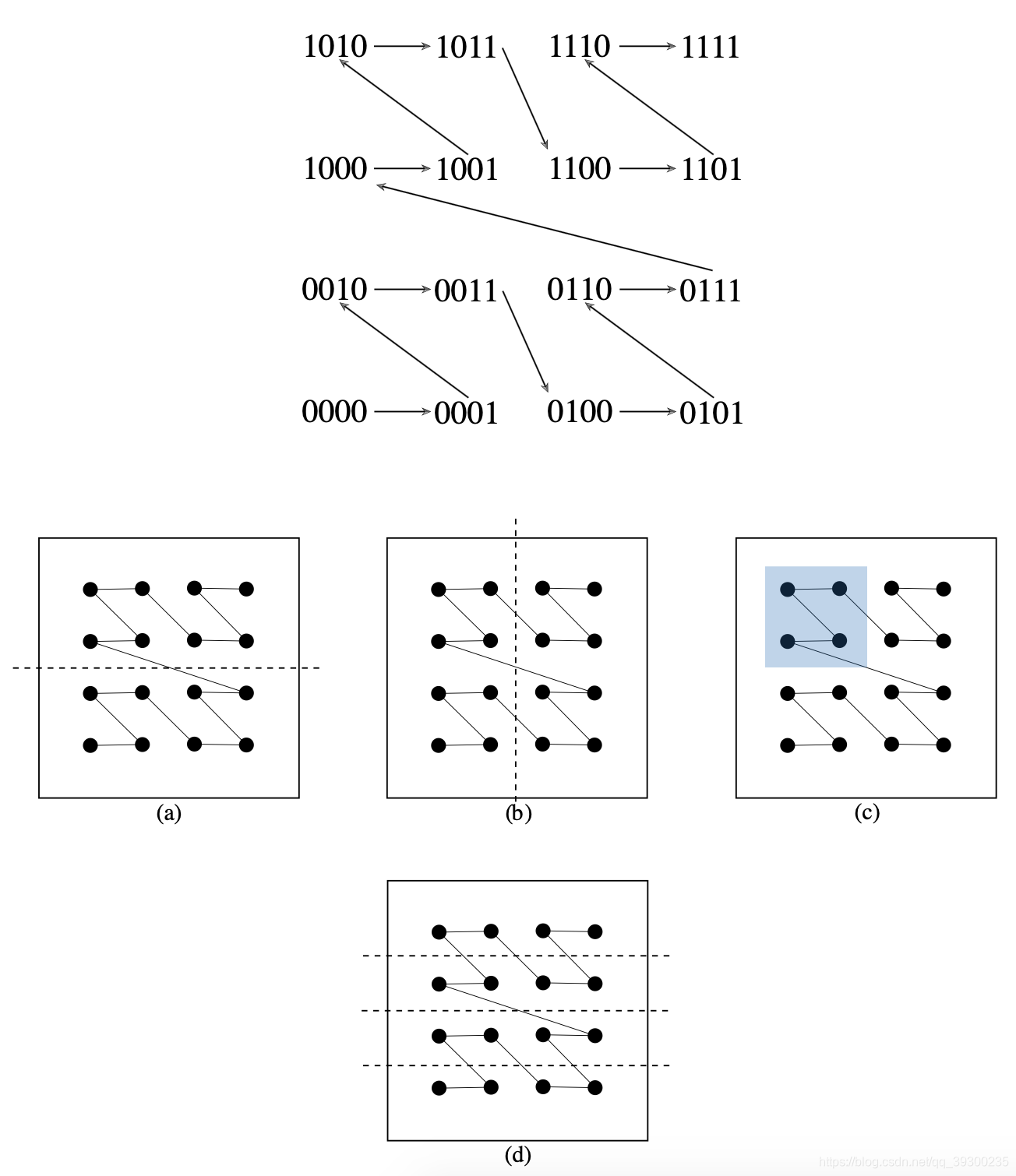
Morton编码有一些非常重要的特点。比如我们在2D坐标中x和y的坐标是[0,15]中的整数,转换为Morton码有八位:,其中
和
为x,y的二进制第i位的值。我们会发现以下特点:
对于置高位的Morton编码值为1,我们知道设置了其基础y坐标的高位,因此y>=8(下图(a)),既坐标分布在整个空间的上半 区。下一个值
等分了x轴(下图(b))。例如,如果置
为1且
为0,则对应点必须位于下图(c)的阴影区域中。
的值将y轴区域四等分(下图4.8(d))。因此每个固定的Morton码都能指定一个唯一的空间位置,且位置和二次幂对齐。
LBVH是通过使用位于每个空间区域的中点的分割平面对基元进行分区而构建的BVH(即相当于先前定义的SplitMethod :: Middle方法)。因为它基于上述Morton编码的属性,所以分区非常有效。
在此处的实现中,我们将构建一个分层的线性边界体积层次(HLBVH)。通过这种方法,基于Morton的聚类首先用于为层次结构的较低级别构建树,然后使用表面积启发式方法(SAH)创建树的顶层。 HLBVHBuild()方法实现此方法,并返回结果树的根节点。代码如下:
BVHBuildNode *BVHAccel::HLBVHBuild(
MemoryArena &arena, const std::vector<BVHPrimitiveInfo> &primitiveInfo,
int *totalNodes,
std::vector<std::shared_ptr<Primitive>> &orderedPrims) const {
// +联合所有图元质心的边界框。(+)表示代码展开
// +计算图元的morton编码
// +基排序图元Morton编码
// +在BVH底部创建LBVH子树
// +从LBVH树中创建并返回SAH的BVH
}BVH是仅使用图元边界框的质心对它们进行排序而构建的,它不考虑每个图元的实际空间范围。 这种简化对于HLBVH提供的性能至关重要,但是这也意味着对于具有跨越多种大小的图元的场景,构建的树不会像基于SAH的树那样考虑这种变化。
由于Morton编码在整数坐标上进行操作,因此我们首先需要对所有图元的质心进行联合,以便可以相对于整个边界对质心位置进行插值量化:
// =计算所有图元质心的边界框
Bounds3f bounds;
for (const BVHPrimitiveInfo &pi : primitiveInfo)
bounds = Union(bounds, pi.centroid);给定总体质心的边界,我们现在可以为每个图元计算Morton编码。 这是一个相当轻量级的计算,但是考虑到可能有数百万个图元,因此值得并行化。 请注意,循环块大小为512传递给下面的ParallelFor(), 这会导致为工作线程分配512个图元组进行处理,而不是一次处理一组,否则将是默认值(ParallelFor函数利用CPU执行并行计算,之后会写一篇介绍PBRT的并行计算)。 因为每个图元执行的用于计算Morton代码的工作量相对较小,所以这种粒度可以更好地分摊将任务分配给工作线程的开销:
// =计算Morton编码
std::vector<MortonPrimitive> mortonPrims(primitiveInfo.size());
ParallelFor([&](int i) {
// +对第i个图元计算Morton编码
}, primitiveInfo.size(), 512);为每个图元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3027
3027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









