









K-Lane Lidar Lane Dataset and Benchmark for Urban Roads and Highways
摘要
车道线检测是自动驾驶的一个关键功能。随着近年来深度学习的发展及相机车道线数据集和基准的发布,相机车道线检测网络(CLDNs)得到了显著的发展。不幸的是,CLDNs所依赖的相机图像往往在消失线附近有畸变,并且倾向于在低光照条件下工作。这与激光雷达车道检测网络(Lidar lane detection networks, LLDNs)相比,后者可以直接从鸟瞰视图(BEV)上提取车道线进行运动规划,并在各种光照条件下稳健运行。然而,LLDNs尚未得到积极的研究,由于缺乏大型公共激光雷达车道线数据集。在本文中,我们介绍了KAIST-Lane(K-Lane),世界上第一个也是最大的公开激光雷达的城市道路和高速路车道线数据集。K-Lane有超过15K帧,包含多达6个车道的各种道路和交通条件下的标注,如多种遮挡级别的遮挡道路、白天和夜间的道路、合并(汇入和分流)和弯曲车道。我们还提供基准网络,我们称之为激光雷达车道检测网络,利用全局特征关联器(LLDN-GFC)。LLDN-GFC利用点云车道线的空间特征,车道线稀疏、细,并沿着点云的整个地平面延伸。从实验结果来看,LLDN-GFC在K-Lane上获得了SOTA的性能,F1得分为82.1%。此外,与CLDNs不同,LLDN-GFC在各种光照条件下都表现出了强大的性能,甚至在严重遮挡的情况下也具有鲁棒性,这与使用传统CNN的LLDNs不同。K-Lane、LLDN-GFC训练代码、预训练模型和完整的开发工具包(包括评估、可视化和注释工具)可在https://github.com/kaist-avelab/k-lane上获得。
1. 介绍
自动驾驶依赖于许多关键功能,这些功能都是通过最先进的(SOTA)技术实现的。其中,车道检测函数是检测自我车道和相邻车道的准确位置和曲率,为路径规划函数提供必要的输入。因此,车道检测函数应该对各种条件(如夜间、白天)和具有挑战性的情况(如车道线闭塞)具有鲁棒性。然而,传统的基于图像处理的车道检测技术由于依赖启发式方法,如去噪、边缘检测、与检测到的边缘拟合等,容易出现车道线部分缺失或遮挡的情况[2,3,20]。
最近,车道检测[13,16,23]由于深度学习得到了很大的改进。当一个带有精确标签的大型数据集可以用于训练时,深度学习网络可以产生高质量的预测,几乎与地面事实没有区别。摄像机车道检测网络(CLDNs)就是如此[13,23],当从公共数据集(如CULane[16]和TuSimple[25])中获得丰富的训练样本时,它比传统的(即启发式)车道检测技术表现出更优越的性能。
然而,cldn仍然有一些固有的问题。首先,相机的照明条件很差,比如光线很弱或很刺眼。其次,通常需要将前置摄像头图像投影到二维鸟瞰图(BEV)进行运动规划,这往往会导致车道线失真[1]。例如,在前置摄像头图像[27]的消失线附近检测到的车道的bev投影可能会导致车道线不准确和扭曲,因此应该将运动规划限制在较短的距离。
另一方面,激光雷达在车道检测方面比摄像机有很多优势;由激光雷达点云进行车道检测不受bev投影畸变的影响,也不受光照条件的影响。然而,文献中介绍的研究较少,主要是由于激光雷达车道检测网络(LLDN)没有足够的公共数据集和基准。

图1。K-Lane的不同条件下的框架示例,其中每一列显示一个条件:每一列总共由三行组成。每一行分别显示左上角的真实BEV标签投影到前视图图像的上部图和位于BEV点云顶部的车道标签的下部图
本文介绍了世界上第一个、也是最大的用于城市道路和高速公路激光雷达车道线检测的开放式激光雷达车道线数据集KAIST-Lane (K-Lane)。我们还为训练、评估、数据集开发和可视化提供易于使用的开发套件。K-Lane有超过15K个标注框,包含最多6个不同道路和交通条件下的车道,如夜间和白天的道路、合并(会聚和分流)和弯曲车道,如图1所示。每个标注包括车道线分割标签、行驶状况、车道形状和遮挡水平。因此,开发的lldn在不同具有挑战性的条件下的性能可以很容易地进行评估,例如,在夜间驾驶时,或由于高遮挡造成的重大测量损失时。分割标签在BEV图像上精确地标注了一个像素宽度,这就转化为现实世界中4cm × 4cm的面积。标签由一个类id组成,它表示车道线相对于自我车道的相对位置。这使得通过训练LLDNs可以直接推断出自我车道的位置,这对运动规划至关重要。此外,如图1所示,利用激光雷达点云对前置摄像头图像进行了精心的校准,实现了直观的可视化,为进一步使用多模态传感器(如传感器融合)进行车道检测研究铺平了道路。
为了证明利用K-Lane开发LLDNs的可行性,我们提出了一个基线模型,即利用全局特征相关器(LLDN-GFC)的激光雷达车道检测网络,该网络充分利用了点云中车道线的空间特征。这与文献[1,14]中介绍的大多数基于cnn的lldn形成了对比,后者大多是针对相机图像开发的基于cnn的cldn的改进。我们观察到,基于cnn的LLDNs不适合在激光雷达点云中检测车道线。例如,前视图图像上的车道线厚度随着与自用车辆的距离而减小,并走向相同的消失点(在直线道路上),而纯电动汽车图像中的车道线厚度不变,并在整个纯电动汽车图像上平行延伸。与我们提出的LLDN-GFC相比,基于cnn的车道检测网络并没有很好地利用激光雷达点云中车道线的这些空间特征。提出的LLDN-GFC可以通过Transformer[4]和Mixer[24]块实现,对车道线进行有效的全局特征关联。实验结果表明,本文提出的基线性能优于使用传统CNN的LLDNs。本文的贡献可以概括为:
- K-Lane:我们引入了世界上第一个和最大的(15382帧)公共激光雷达车道数据集,用于各种条件和场景下的城市道路和高速公路。
- 我们还为训练、评估、注释和可视化提供了一个完整的开发套件。
- 我们展示了Lidar点云中的车道线具有传统RGB图像中没有的特殊特征,并提供了合适的基线网络,我们称之为LLDN-GFC,它在f1评分上明显优于使用传统CNN的lldn。
本文的组织结构如下。第2节介绍了与本文和本文主题相关的先前研究,第3节介绍了K-Lane数据集,以及拟议的基线LLDN-GFC。第4节展示了实验设置和结果。我们在第5节中得出结论,并介绍了数据集和基线的更多信息,如附录中LLDN-GFC的详细网络结构。
2. 相关的工作
车道线检测数据集和基准。近年来,基于深度学习等数据驱动方法的 车道线检测取得了巨大进展。实现这些进步的一个关键因素是大型公共车道数据集的可用性,如表1所示。TuSimple [30]是最早公开可用的基于相机的车道线数据集之一。它白天在高速公路上收集了6408个帧。数据集被进一步划分为3626帧用于训练,358帧用于验证,2,782帧用于测试。CULane[19]介绍了一个更多样化和更具挑战性的基于相机的车道线数据集,其中133,235帧分为88880帧用于训练,9675帧用于验证,34680帧用于测试。CULane提供了不同的驾驶条件,无论是在城市环境还是高速公路环境,在白天和晚上,以及不同的道路结构。与基于相机的车道线检测领域相比,Lidar车道线检测数据集还没有得到充分的探索。最早的激光雷达车道数据集之一是DeepLane [1],其中包含在城市和高速公路环境中收集的55168帧激光雷达和相机数据。另一个数据集RoadNet [17]由仅在高速公路环境中收集的5200帧激光雷达数据组成。不幸的是,这两个数据集都不是公开的,因此没有太多关于激光雷达车道线检测的衍生工作。所提出的数据集K-Lane包含15382帧的激光雷达和相机数据,在城市和高速公路环境中收集。随着K-Lane的公开,我们为使用激光雷达的车道检测方法的一个新的研究方向铺平了道路。
视觉车道线检测网络。 随着标注的相机数据集 [19]用于各种道路成为可用的,CLDNs已经取得了重大进展。与早期的基于规则的技术 [3, 4] 相比,CLDNs对各种道路环境的适应性更强。在这些技术中,车道线预测是基于CNN [8]提取的局部特征,车道线检测头利用车道线特征来提高性能。例如,Qin et al. [22]提出了一种基于行检测的网络,将整个图像划分为网格,并从每行网格中识别车道。Liu等人 [16]提出了一种两阶段的车道线检测网络,将条件卷积 [35]与检测头中的行检测相结合,并在几个数据集上实现了SOTA性能。然而,CLDNs存在一些固有的问题。在CULane基准测试中,大多数CLDNs在夜间和耀眼的光线条件下表现出与白天性能相比显著的性能下降(约20%) [16,22]。
激光雷达早期车道线检测技术。 在早期的研究中,车道点是通过对测量的强度(或反射率)进行阈值化来检测的。Lindner等人 [15]使用固定的极网格地图来存储点强度,并沿着方位角用阈值过滤候选车道线。Hernandez等人 [9]介绍了一种聚类方法,其中过滤后的车道点使用DBSCAN进行聚类 [6]。然而,这些启发式技术依赖于预先定义的阈值参数,因此对不同环境的适应性不强。
激光雷达车道线检测网络。由于缺乏大型开放数据集,基于深度学习的激光雷达车道线检测研究尚未积极开展,文献中仅介绍了一些具有私有数据集的研究。Bai等人 [1]提出了一种LLDN,将激光雷达点云和前端相机图像开发的2D BEV图像相结合,用于车道检测。Martinek等人 [17]提出了一种基于cnn的LLDN,使用点云的BEV图像来检测自我车道,并在不拥挤的高速公路上测试网络。
视觉中的自注意力。 自注意力(Self-attention)是一种引导神经网络更加关注输入图像中相关分数高的图像块的方案。卷积块注意力模块(CBAM) [33]通过在传统的基于cnn的特征提取器上分别添加MLP(多层感知机)和卷积操作,引入了每通道和每空间的自注意力机制。由于Transformer [31]通过对查询、键和值(即Transformer块)应用三个独立的mlp,在自注意力机制方面表现出了显著的改进,因此已被积极用于图像和点云。例如,ViT(视觉Transformer) [5]使用Transformer大大提高了图像分类性能,其中ViT将输入图像划分为单元块,并将Transformer编码器应用于每个块以进行图像分类。然而,ViT为每种注意力机制使用了3个独立的mlp,这不可避免地会带来高计算成本和大模型规模。另一方面,MLP-Mixer [29]用一个简单的MLP方案(即Mixer块)实现了注意力机制,从而以
较小的模型尺寸实现了快速推理,并实现了与ViT相当的性能。
3.K-Lane和LLDN-GFC
在本节中,我们介绍K-Lane数据集、基准和提出的基线LLDN-GFC。
3.1. K-Lane
K-Lane是第一个大型开放的LiDAR车道数据集,由各种条件和场景下的城市道路和高速公路的LiDAR点云及其对应的RGB图像组成,如图1所示。
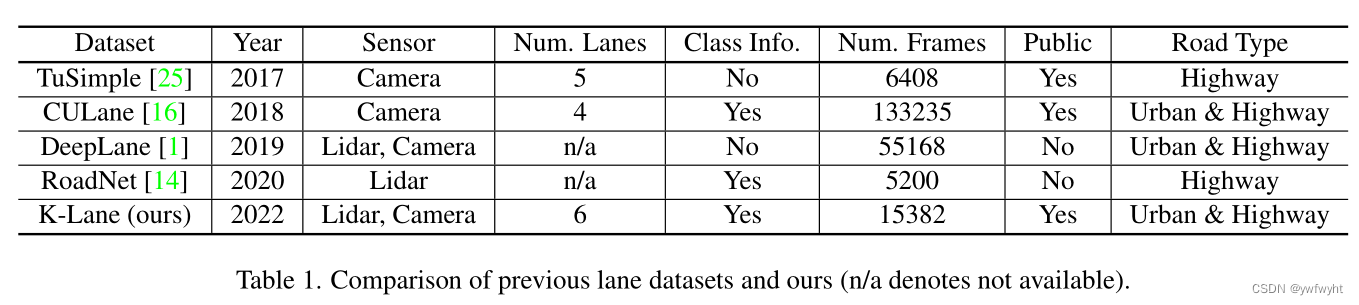
数据分布。 如图2所示,总共有15382个数据帧,分为7687帧用于训练,7695帧用于测试。每个集合包含各种道路条件和具有挑战性的场景,包括(a)不同的照明条件,例如昼夜时间,(b)交通拥挤,车道被其他车辆阻塞;以及©合并(收敛、发散)和弯曲车道,并将其分为平缓曲线和尖锐曲线。注意,车道线有最多6个车道,遮挡分为6个级别,分别代表0、1、2、3和4 ∼ 6个遮挡车道。基准工具包提供了用于计算每个条件的指标的评估工具,并在每个帧的给定条件下以明确的标准进行注释,如附录a所述。
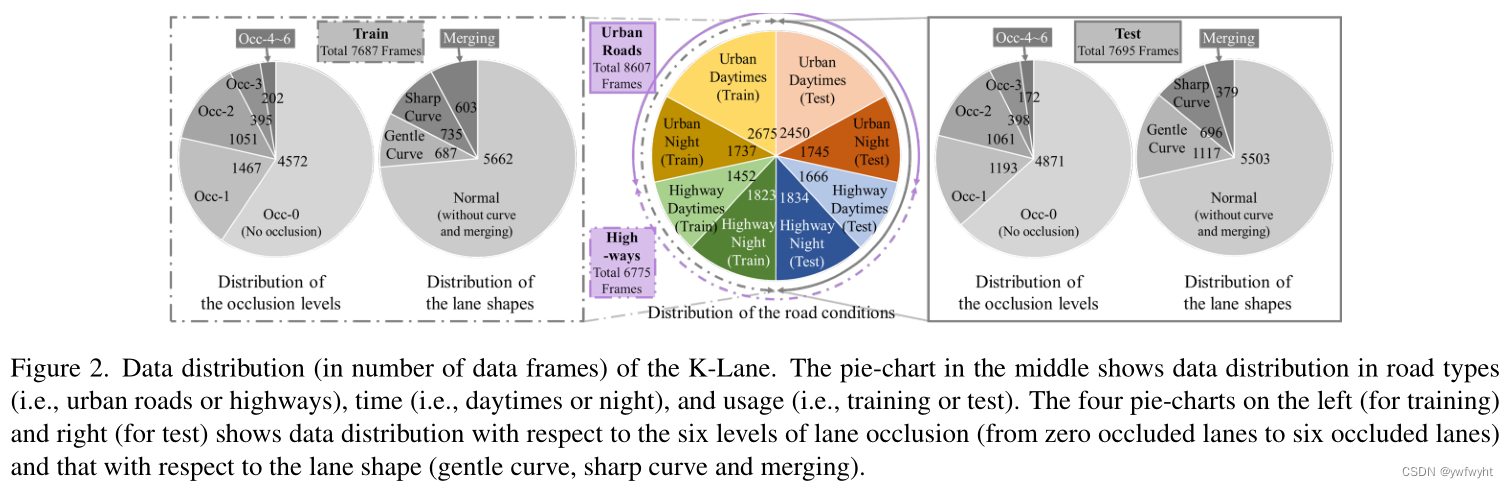
传感器套件。 车道线采用Ouster OS2-64激光雷达传K-Lane是第一个大型开放的激光雷达lane数据集由激光雷达点云及其对应的RGB组成适用于各种条件下的城市道路和高速公路如图1所示。数据分布。如图2所示,共有其中15382个数据帧,分为7687帧进行训练和7695帧进行测试。每一组包含各种道路条件和具有挑战性的场景包括(a)不同的光照条件如昼夜时间,(b)拥挤车道被其他车辆阻塞的交通,以及©合并Ing(收敛,发散)和弯曲的车道,这是皮毛分为平缓曲线和尖锐曲线。请注意,车道线最多有6个车道,遮挡被划分分为0,1,2,3,和4 ~ 6 6层闭塞车道。基准套件提供了cal-的评估工具计算每个条件下的指标,并给出条件在一个明确的标准下,每一帧都有注释,附录A中有描述。传感器套件。K-Lane使用Ouster OS2-收集64激光雷达传感器 [18]进行采集,该传感器有64个通道,最大范围240m,放置在车顶,前置摄像头为1920 × 1200分辨率,如图3 -a所示。前摄像头图像已经用激光雷达点云仔细校准,这使其易于可视化,并可能使使用多模态传感器进行进一步的车道检测研究。
数据集开发。 地面真值标签是通过将Lidar点云投影到BEV,对强度测量值进行阈值化以提取关键点(即车道线的候选),并为每个车道绘制一个像素宽的线来产生的,如图3 -b所示。因此,产生了高分辨率和准确的标签,这对基于深度学习的方法至关重要。 指标。 为了标准化正在开发的网络的评估,我们选择在置信度和分类中使用F1-score指标,分别评估每像素车道的存在和每像素车道的正确分类。F1指标表示精度和召回率之间的调和平均值,可以表示为
F1 =
2
1
Precision
+
1
Recall
TP
TP + 0.5(FP + FN) ,
(1)
其中TP、FP和FN分别是检测头输出的真阳性、假阳性和假阴性的数量。由于标签中的车道线宽度只有一个像素宽,因此我们允许预测和标签之间最多有一个像素的偏差。这与CULane [19]数据集中使用的评估指标相当,其中车道线标签为30像素宽,当预测和真实值的IoU至少为0.5时,将统计真值。
为了形式化地描述评估指标,让x conf ∈ R M×N 是置信图标签,行数为M,列数为N,列数为x confm,n∈{0,1}。此外,设ˆ x conf ∈ R M×N 为置信图预测,行数为M,列数为N,列数为x conf
m,n∈ [0,1]。此外,我们将以网格x m,n 为中心的网格邻域定义为一组网格{x i,j |i = {m − 1,m,m + 1},j = {n − 1,n,n + 1}}。假设将阈值操作应用于置信图预测,以便
x conf,thrm,n
?
1 ˆ x conf
m,n
σ conf
0 otherwise
, (2)
其中σ conf 是预测的置信度阈值,将其视为车道点。在我们的评估指标中,如果在ˆ x conf,thr
m,n上对一个阳性预测(像素值等于1),在以x confm,n 为中心的网格邻域上存在至少一个阳性标签,则发生真阳性。相反,如果在网格邻域没有正例标签,则预测被视为假阳性。如
果x confm,n 上的阳性标签在以ˆ x conf,thr m,n为中心的网格邻域没有阳性预测,则会发生假阴性。
对于分类预测,将分类图标签转换为one-hot编码标签。此外,我们还将分类预测图转换为one-hot-encoding预测,其中具有最大概率的类被赋值为1,其余为0。分类预测的真阳性、假阳性和假阴性可以用前面提到的过程计算,并对每个可能的类别进行累加。
分类上的F1-score是基于车道线定位和车道类别预测的网络评估。因此,分类上的f1分数是一个严格的评估指标,因此,与置信度预测相比,可以发现所有模型的性能下降,如表2所示。
完整的开发工具包。 提供了一个全面的K-Lane开发工具包,包括训练、评估、数据集开发和可视化。特别是,数据开发工具,如标记和注释工具,通过图形用户界面(GUI)提供易于使用。这使得研究界可以随时增加数据集,而不管Lidar传感器模型如何,从而用不同的数据集和基准以及CLDN激活LLDN的区域。附录A给出了所有细节的完整描述。
总结。 综上所述,与传统的车道线检测数据集相比,K-Lane具有多方面的优势; (1) K-Lane收集了上述各种条件和场景下的城市道路和高速公路,而TuSimple [30]和RoadNet [17]仅包含高速公路,(2)K-Lane通过精确的车道位置(像素级)来区分车道类别和车道标签,而TuSimple [30]和DeepLane [1]则没有区分车道类别的标签(3) K-Lane标记的车道数较多(如最多6条车道),而TuSimple [30]和CULane [19]分别最多只有5条和4条车道,和(4)综上所示,在Lidar车道线数据集中,K-Lane是唯一一个公开可用的数据集,这为进一步研究基于Lidar的车道线检测提供了可能。此外,经过良好标定的摄像机图像还可用于多模态车道线检测。
3.2. LLDN-GFC
在本节中,我们将重点放在LLDNs基线的总体结构和必要性上,而细节,如准确的神经网络结构、函数(即图4中的(1)~(5))和损耗的数学表达式,将在附录b中描述。如图4所示,提出的基线由BEV编码器、作为骨干的GFC和车道检测头组成,这些将在接下来的小节中介绍。

图4. LLDN-GFC的总体结构。有5个函数:(1)、(2)、(3)、(4)、(5)分别表示BEV编码器、reshape & per-patch线性变换、Transformer或混合器块、reshape & shared MLP、检测头。Hbev、Wbev、Cbev、Cout、Np2和Cp分别为伪bev图像的高度、宽度、通道数、输出伪bev图像的通道数、总patch数和全局关联中每个patch的通道数.

图5。CNN和本文提出的GFC之间的全局特征相关性比较,其中N0, N1, N2和C0, C1, C2表示三层特征图的大小和通道数,按深度排序。(a)计算全局相关性的两个分离网格的例子,(b)由CNN开发的特征地图中包含的两个网格,以及©由GFC开发的特征地图中两个网格的相关性。
BEV编码器。BEV编码器将一个三维点云投影到一个二维伪图像中,并对其进行进一步处理,产生一个二维BEV特征图。我们为LLDN-GFC提供两种不同的BEV编码器,即点投影编码器和柱式编码器。
主要的BEV编码器是点投影器,它将点云投影到x-y水平面和使用CNN生成BEV特征图。为了同时保持高分辨率的车道信息和实时速度,我们设计了一个基于ResNet的CNN来输出一个特征图,它是伪图像输入的1/82。
另一种低计算量的2D BEV编码器是基于Point Pillars的柱式编码器,它的网络尺寸相对较小,[13]。柱式编码器的性能略低,但推理速度比基于cnn的点投影仪快。因此,在本文中,柱式编码器被提出作为一种实时应用的替代方案。详情见附录B。
GFC主干网。如图5-a所示,道路上的车道线很细,沿着整个点云延伸,只占用少量像素(即稀疏)。由于这种稀薄性和稀疏性,需要进行高分辨率的特征提取。此外,特征提取器还应考虑BEV特征图中网格之间距离的相关性。因此,我们设计了我们提出的GFC,通过利用patch-wise自我注意网络来高分辨率地计算特征的全局相关性。我们提出了GFC的两种变体:GFC- T(基于Transformer块[5]的主要方案)和GFC- M(基于混合器块[29]的低计算量替代方案)
使用patch-wise自我注意网络的一个主要优势是,它们能够发现距离较远的网格(或patches)之间的相关性,从骨干的早期阶段开始,如图5-c所示。因此,可以保留高分辨率信息(即N0 = N1)。这与基于cnn的特征提取器不同,后者在经过几层卷积和下采样后,可能会发现距离较远的网格之间的相关性,从而降低信息的分辨率。(即。N0≫N2),如图5-b所示。
在定量上,我们观察到,与基于CNN的[17]相比,基于patch的自注意力网络具有更高的性能。另外,我们将中间特征图和注意得分的定性结果分别在图6和图7中可视化。定量和定性结果进一步表明,即使在相对较少的数据(即7687训练帧)上,使用patch-wise自我注意网络进行激光雷达车道检测的适用性。
检测头和损失函数。为了设计检测头,我们将车道线检测问题定义为一个多类分割问题,其中每个像素被分配一个类和一个置信度得分。多类别车道线分割方法使检测头能够预测车道线类别和各种车道线形状,这对于自车需要规划车道间运动或识别车道合并和分离的运动规划具有重要意义。LLDN-GFC检测头由两个分割头组成,每个分割头由两层共享MLP序列组成,其中间由非线性激活函数连接。
由于每帧车道线样本的数量明显小于背景样本的数量,我们加入了soft-dice损失[22],以处理固有的不平衡问题的置信度损失。对于分类头,我们选择了广泛用于多类分类问题的网格交叉熵损失[19],引导网络在训练过程中学习最大化正确车道线类别的概率。总损失函数是soft-dice损失和交叉熵损失的总和,附录B所示。
4. 实验和对比
在本节中,我们将详细比较LLDN-GFC和传统的基于CNN的LLDNs的性能。此外,我们还论述了最近的CLDNs,以便与LLDN-GFC性能进行总体比较。
实现细节。我们评估了LLDN-GFC的两种变体,Proj28-GFC-T3和Pillars-GFC-M5,我们在实验中观测到(即附录C中的消融实验),分别具有最佳的精度和速度-精度权衡。Proj28-GFC-T3代表LLDN-GFC是28层的点投影编码器和带有三个Transformer块的GFC。Pillars-GFC-M5代表LLDN-GFC是柱编码器和带五个混合器块的GFC。
我们使用RTX3090 GPUs在K-Lane上训练60个epoch,使用批量大小为4和学习率为0.0002的Adam优化器[11]。所有训练和评估都在带有PyTorch 1.7.1[20]的Ubuntu 18.04机器上实现。

表2。提出的LLDN-GFC和各种基于CNN的LLDNs的F1置信度/分类得分。Enc、Shp、Occ分别代表BEV Encoder、sharp curve和occlusion case。我们展示了没有遮挡和严重遮挡(4 ~ 6条车道线被遮挡)的情况,而其他遮挡水平在附录c中给出。FPS代表每秒帧数,它代表了网络推理过程的 总体计算成本(FLOPs,数据效率等),类似于[29]中的吞吐量。注意,我们只显示探索技术的F1置信度得分。
4.1. LLDN-GFC与基于CNN的LLDN
我们考虑三种基于CNN的骨干网与本文提出的GFC进行比较,分别是RNF-S13、RNF-D23和RNF-C13,其中(1)RNF表示ResNet [8] 特征金字塔网络 (FPN) [14], (2) S13、D23和C13分别表示13层和23层的跨步卷积、空洞卷积和卷积注意力模块(CBAM:Convolutional Block Attention Module)[33]实现的残差块。通过实验(即附录C中的消融实验)也确定了对应的模型容量。采用FPN综合考虑不同层次的特征图映射,空洞卷积在不损失分辨率的情况下增加了感受野,这在现有的LLDN[17]中得到了应用。CBAM执行自我注意力机制类似于LLDN-GFC,但它采用了每通道卷积操作,这意味着它不像LLDN-GFC那样对所有patch执行全局相关性。因此,采用RNF-C的LLDN的性能低于提出的LLDN-GFC,如表2所示。
如表2所示,所提出的LLDN-GFC比基于传统CNN的不同深度骨干网LLDNs具有更好的性能。特别是,LLDN-GFC在四条或更多车道线被遮挡的情况下表现出了强大的性能。
图6显示了基于中间特征图可视化的LLDN-GFC鲁棒性的定性评估。我们可以在热图上观察到,project 28- gfc - t3 (a)和project 28- gfc - m3 (b)都明显提取出了分辨率更高的通道,尤其是在较深的层。这与©和(d)所示的基于cnn的LLDN形成对比,后者的车道往往模糊。也就是说,与基于cnn的LLDNs提取的车道特征相比,Proj28-GFC-T3和Proj28-GFC-M3提取的车道特征在背景上更有特色。此外,即使在存在遮挡的情况下,project 28- gfct3和project 28- gfc - m3也能够通过与非遮挡车道的相关性来预测车道形状,这是基于cnn的lldn中没有观察到的。
 图6。车道闭塞情况下LLDN-GFC与基于cnn的lldn车道检测性能比较。四列分别为(a) project 28- gfct3, (b) project 28- gfc - m3, © project 28- rnf - c13和(d) project 28- rnf - s13的推断结果。第一行显示了推断结果在左上角有标签的前视图图像上的投影,第二行显示了对BEV点云的推断。从第三行到第五行,我们展示了沿主干的第1、2、3块输出特征图通道采样的热图(如GFC的第1、2、3个变压器块或RNF的剩余块)。附录D中介绍了各种场景的热图,如曲线和合并车道线。
图6。车道闭塞情况下LLDN-GFC与基于cnn的lldn车道检测性能比较。四列分别为(a) project 28- gfct3, (b) project 28- gfc - m3, © project 28- rnf - c13和(d) project 28- rnf - s13的推断结果。第一行显示了推断结果在左上角有标签的前视图图像上的投影,第二行显示了对BEV点云的推断。从第三行到第五行,我们展示了沿主干的第1、2、3块输出特征图通道采样的热图(如GFC的第1、2、3个变压器块或RNF的剩余块)。附录D中介绍了各种场景的热图,如曲线和合并车道线。
4.2. LLDN-GFC关注可视化
在本小节中,我们讨论了所提出的LLDN-GFC, Proj28-GFC-T3,利用注意力分数的可视化对遮挡场景的鲁棒性。本文提出的GFC基于自我注意机制,利用数据单元之间的相关性,使网络更加关注特征图上有意义的区域。因此,通过可视化每个Transformer块产生的注意力得分,我们可以看到GFC-T3认为重要的区域,如图7所示。
从可视化中,我们可以看到,网络通过衰减非车道线(无关)特征的大小,更多地关注包含车道线的区域。随着层的加深,网络扩展其兴趣区域,表现为具有高注意力分数的区域不断增加。我们观察到,为GFC-T3使用三个变压器块足以确保自我注意机制覆盖包含车道线的点云的整个区域。此外,请注意,对于查询位置(图7中的黄色框),即使查询位置被遮挡,网络对车道线存在的区域也会产生很高的关注分数。这样的现象表明LLDN-GFC对遮挡的鲁棒性,该算法通过考虑整个点云进行预测,仍然可以准确地估计出遮挡的车道线。这对于基于cnn的LLDN可能不可能,因为LLDN的特征是通过局部卷积识别的。

图7。Proj28-GFC-T3注意力得分可视化。(aupper)是将推理结果投影到左上角有标签的前视图图像上,(a-lower)是在BEV点云上的推理结果和当前查询补丁(黄色框)。(b) ~ (d)分别表示BEV中的点云、车道推理结果、查询patch、标签用青色表示,GFC的block 1、block 2、block 3的注意得分用紫色表示。
4.3. LLDN-GFC与摄像机车道检测
文献中大多数最先进的车道线检测网络都是针对前视相机图像的。这意味着大多数CLDNs被训练来检测前视图中的车道线。另一方面,LLDN-GFC训练用于检测BEV地图中的车道线。此外,采集数据的环境也不同。CULane主要由城市道路的数据组成,而k lane则由城市道路和高速路的数据组成。由于这些激光雷达和相机数据集不使用相同的表示,并且是在不同的环境中采集的,所以我们不能简单地使用文献中报告的性能来比较CLDNs。
然而,最近的CLDNs显示,与白天数据相比,夜间数据的性能有显著下降。例如,CondLaneNet-Large[16]、LaneATT-Large[28]和CurveLane-NAS-L[34]在白天和夜间条件下分别下降了18.67%、20.93%和21.8%。相比之下,如表1所示,提出的LLDN-GFC几乎没有性能下降(只有0.2%的差异)。这是因为激光雷达对光照条件具有鲁棒性,这表明LLDN在自动驾驶中是一个可靠的功能。
5. 结论
在这项工作中,我们介绍了K-Lane数据集,据我们所知,它是第一个用于激光雷达车道线检测的公开可用数据集。K-Lane由超过15K在多样化和具有挑战性驾驶环境下的高质量标注的激光雷达数据组成,以及校准良好的前视RGB图像。驾驶场景包括多种光照(白天和夜间),车道遮挡(最多6条被遮挡的车道线),和道路结构(合并、分流、弯曲车道)。此外,我们还提供开发工具包为K-Lane包括标注、可视化、训练和基准测试工具。我们还介绍了一个基线网络用于激光雷达车道线检测,我们称之为LLDN-GFC。LLDN-GFC利用自我注意机制,通过全局关联提取车道特征,与传统的基于cnn的LLDNs相比,显示出优越的性能。此外,我们还展示了激光雷达车道线检测的重要性,与基于摄像头的车道检测网络相比,在白天检测和夜间检测之间,性能几乎没有下降。因此,我们希望本研究能为激光雷达车道线检测领域的进一步研究铺平道路,及提高自动驾驶的安全性

















 7115
7115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











