








论文信息
论文来源:
arXiv
论文引用:
Han X, Gao T, Lin Y, et al. More data, more relations, more context and more openness: A review and outlook for relation extraction[J]. arXiv preprint arXiv:2004.03186, 2020.
论文链接:
https://arxiv.org/abs/2004.03186
1. 文章概要
关系事实(Relational facts)是人类知识的重要组成部分,显式或隐式地隐藏在文本中。
为了从文本中抽取这些事实,人们多年来一直在进行关系抽取(Relation Extraction, RE)。
关系事实通常以三元组 的形式组织。
- “Steve Jobs co-founded Apple” 表明事实 (Apple Inc., founded by, Steve Jobs)
- 从“Hamilton made its debut in New York, USA ”.推断出事实 (USA, contains, New York)
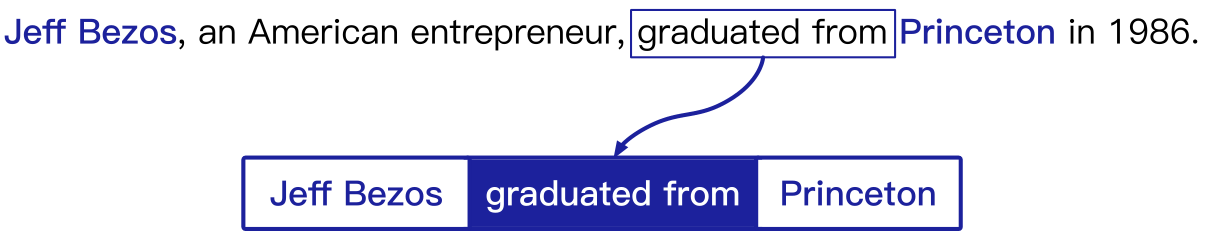
关系抽取的主要目标是根据句子语义信息推测实体间的关系。
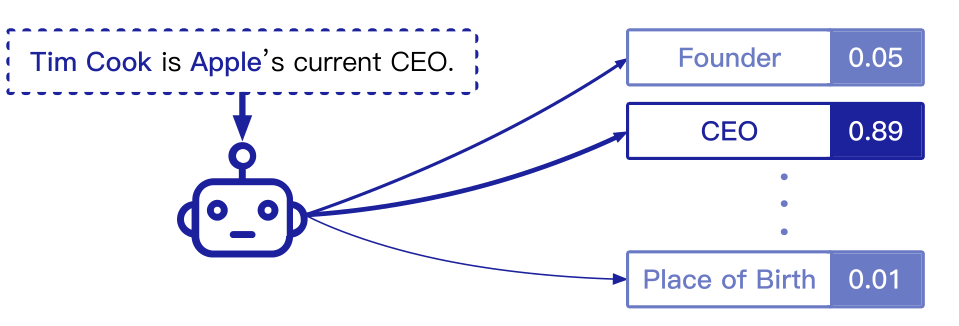
上图是RE的一个例子。给定两个实体和一句提及它们的话,RE模型在预定义的关系集中对它们之间的关系进行分类。
早期的关系抽取任务主要依赖统计方法:模式挖掘(Patten Mining)、基于特征的方法(Feature-based Methods)、图模型(Graphical Models)。
近期广泛采用的方法基于神经网络,效果显著,在多个公开数据集上证明了其能力。
但大多数方法只能在简化的环境中工作。这些方法主要关注具有大量人工标注的训练模型上,只能将单句话中的两个给定实体进行关系分类,而且关系类别是预定义的。
但是,现实世界比这种简单的设置要复杂得多:
-
收集高质量的人工注释既昂贵又耗时;
-
数据分布不均衡,存在长尾效应,某些关系无法提供大量的训练示例;
-
大多数事实由包含多个句子的较长上下文表示;
-
很难使用预定义关系集合来覆盖那些仍在开放式增长的关系;
本文认为,为了提升RE的效果,可以在以下四个方向进行研究:
(1) 使用更多数据
关系抽取作为有监督任务,依赖大量标注数据。这一问题可以通过远程监督(distant supervision)引入更多自动标记的数据来缓解。然而,距离较远的方法会带来噪声示例,并且只利用提及实体对的单句,这显著削弱了提取性能。设计一种模式以获得高质量和高覆盖率的数据来训练鲁棒的RE模型仍然是一个有待探索的问题。
(2) 更有效地学习
在实际情况下,实体间关系和实体对的出现频率往往服从长尾分布,许多长尾关系( long-tail relations)仅包含一些训练示例。但是,传统的RE方法很难做到和人类一样很好地概括有限实例的关系模式。因此,开发有效的学习模式以更好地利用有限或小样本(few-shot)的例子是一个潜在的研究方向。通俗地说,如何提高深度模型的学习能力,实现”举一反三“。
(3) 处理复杂语境
现有模型主要从单个句子中抽取实体间关系,要求句子必须同时包含两个实体。实际上,许多关系事实是在复杂的上下文中表达的(例如,一篇文档的多个句子中,甚至在多个文档中)。如何在更复杂的语境下进行关系抽取,也是关系抽取面临的问题。
(4) 开放关系问题
在现实世界中,每天都有新的关系从不同的领域出现,因此很难人工覆盖所有的领域。然而,常规的RE框架通常是为预先定义好的封闭关系集合设计的,将任务转换为关系分类问题。文本中蕴含的实体间的新型关系无法被有效获取。如何利用深度学习模型自动发现实体间未定义的新型关系,实现开放关系抽取,仍然是一个”开放“问题。
2. 现有工作
信息抽取(Information extraction, IE)旨在从非结构化文本中提取结构信息,是自然语言处理的一个重要领域。关系抽取(RE)作为IE中的一项重要任务,特别着重于抽取实体之间的关系。
一个完整的RE系统包含三部分:
- 命名实体识别(Named Entity Recognizing),用于从文本中识别命名实体
- 实体链接(Entity Linking),将抽取的实体和已有知识图谱关联
- 关系分类(Relation Classification),根据上下文对实体关系进行分类
在这些步骤中,关系识别是最关键和最困难的任务,因为它需要模型来很好地理解上下文的语义。因此,RE通常专注于研究分类部分,这也称为关系分类。
关系抽取模型的发展
基于模式的方法
⇒
\Rightarrow
⇒ 基于统计的方法
⇒
\Rightarrow
⇒ 基于神经网络的方法
早期的方法,可以参考我的这篇博客:斯坦福Introduction to NLP:第十讲关系抽取
2.1 基于模式的模型(Pattern Extraction Models)
使用句法分析工具识别文本中的语法元素,然后根据这些元素自动构建模式规则。
为了更好的覆盖率和精确率,后续工作包括:大量语料、更多形式的模板。
局限:由于自动构建的模式通常有错误,需要人类专家的进一步检查
2.2 基于统计的模型(Statistical Relation Extraction Models)
与使用模式规则相比,统计方法带来了更好的覆盖率,并且需要更少的人力,因此被广泛研究。
-
典型的有基于特征的方法(Feature-based Methods),为实体对及其相应上下文设计了词法,句法和语义特征用于分类。
-
由于支持向量机(SVM)的广泛使用,大量的探索使用核函数测量关系表示和文本实例之间的相似性
-
还有一些其他的统计方法,着重于抽取和推断隐藏在文本中的潜在信息。图方法以有向无环图的形式抽象实体、文本和关系之间的依赖关系,然后使用推理模型来识别正确的关系。
-
受到其他NLP任务中成功嵌入模型(word2vec)的启发,有研究人员将文本编码到低维语义空间中,并从文本嵌入中抽取关系,此外也有利用KG Embedding进行RE。
局限: 基于特征和基于内核的模型需要很多努力来设计特征或内核函数。虽然图形和嵌入方法可以预测关系,而无需过多的人工干预,但它们在模型容量方面仍然有限。
关于SRE的综述:
Relation Extraction : A Survey
2.3 基于神经网络的模型(Neural Relation Extraction Models)
神经关系抽取(Neural Relation Extraction, NRE)模型引入神经网络从文本中自动抽取语义特征。
与SRE模型相比,NRE方法可以有效地捕捉文本信息,并推广到更广泛的数据。
其研究主要集中在设计和利用各种网络架构来捕捉文本中的关系语义。
几种典型的网络结构
- 递归神经网络(recursive neural networks)采用递归的神经网络对句子的语法分析树建模,试图在提取语义特征的同时考虑句子的词法和句法特征
- 卷积神经网络(CNN)捕捉句子的局部特征,对句子语义进行编码
- 循环神经网络(RNN)更好地处理长序列数据
- 图神经网络(GNN)构建用于推理的单词/实体图
- 基于注意力的网络(attention-based NN)利用注意力机制聚集全局关系信息
与SRE模型不同,NRE主要利用词嵌入(word embedding)和位置嵌入(position embedding),而不是手工特征作为输入。除了词嵌入和位置嵌入,还有其他将句法信息整合到NRE模型中的工作。分别采用CNNs和RNNs编码最短依赖路径(shortest dependency paths )。
现在Transformer和预训练语言模型达到了最新的SOTA
下图是不同年份最先进的RE模型在广泛使用的数据集SemEval2010任务8上的性能。(原论文中的图)
SemEval-2010 Task-8的任务设定为,对预先定义好的关系类别标注大量的训练和测试样例,样例都是相对简单的短句,而且每种关系的样例分布也比较均匀。
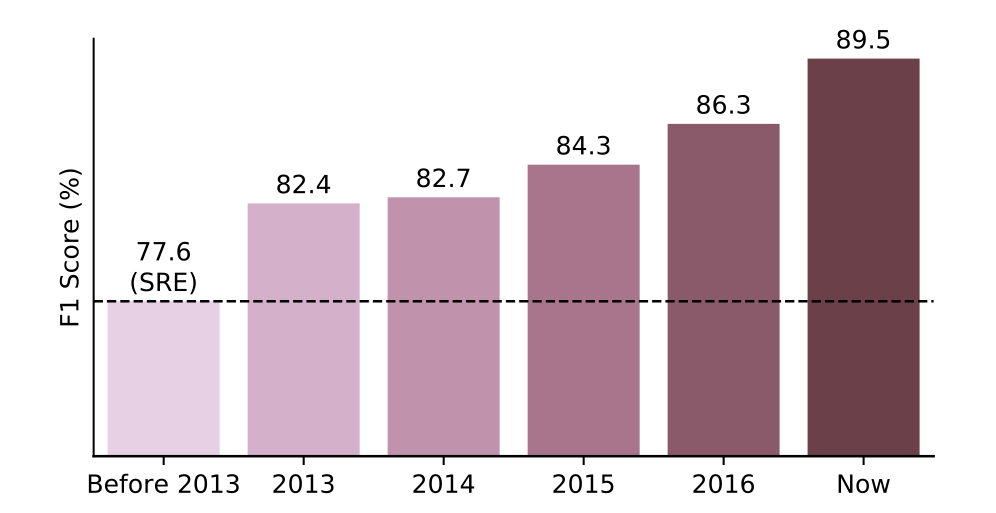
2021.06更新数据:
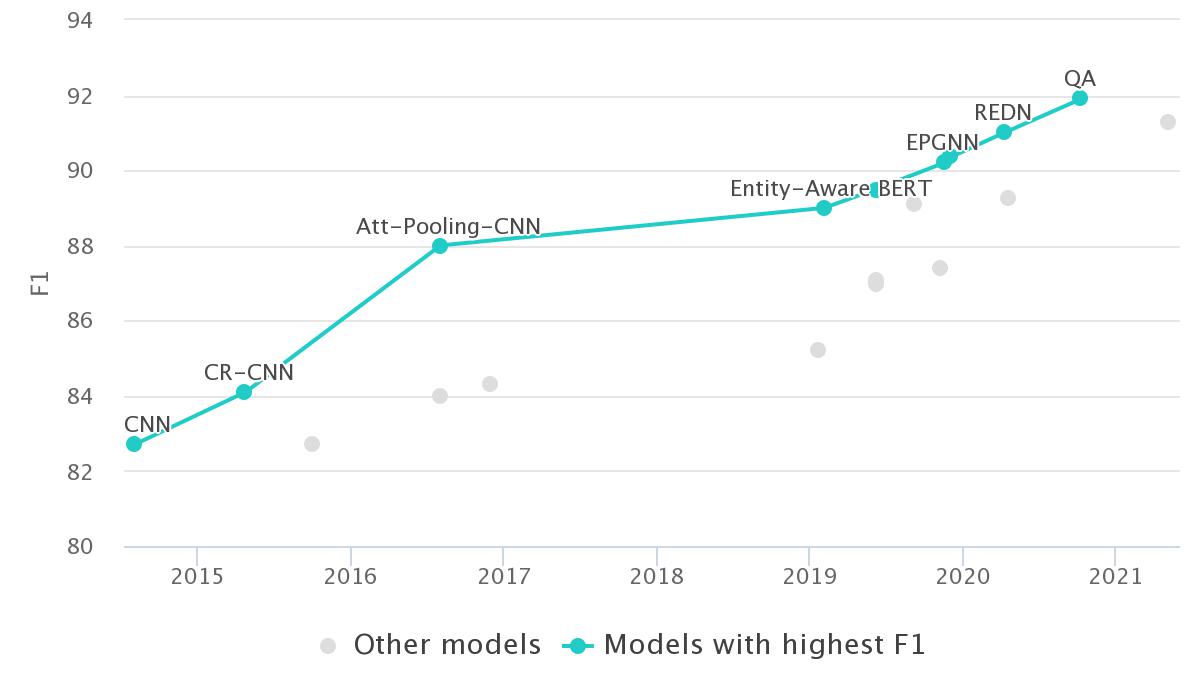
SOTA数据来源:https://paperswithcode.com/sota/relation-extraction-on-semeval-2010-task-8
神经模型的采用(从2013年开始)带来了性能的极大提升。
3. 关系抽取的更多发展方向
3.1 使用更多数据
受监督的NRE模型缺乏大规模高质量的训练数据,因为手动标记数据既耗时又耗费人力。
为了解决标注数据稀少的问题,使用远程监督(Distant Supervision, DS),通过自动对齐已有知识图谱和纯文本来自动标注大规模训练数据。远程监督的思想并不复杂,具体来说:如果两个实体在知识图谱中被标记为某个关系,那么我们就认为同时包含这两个实体的所有句子也在表达这种关系。将已有的标注样本的关系应用在含有相同实体对的未标注样本中。
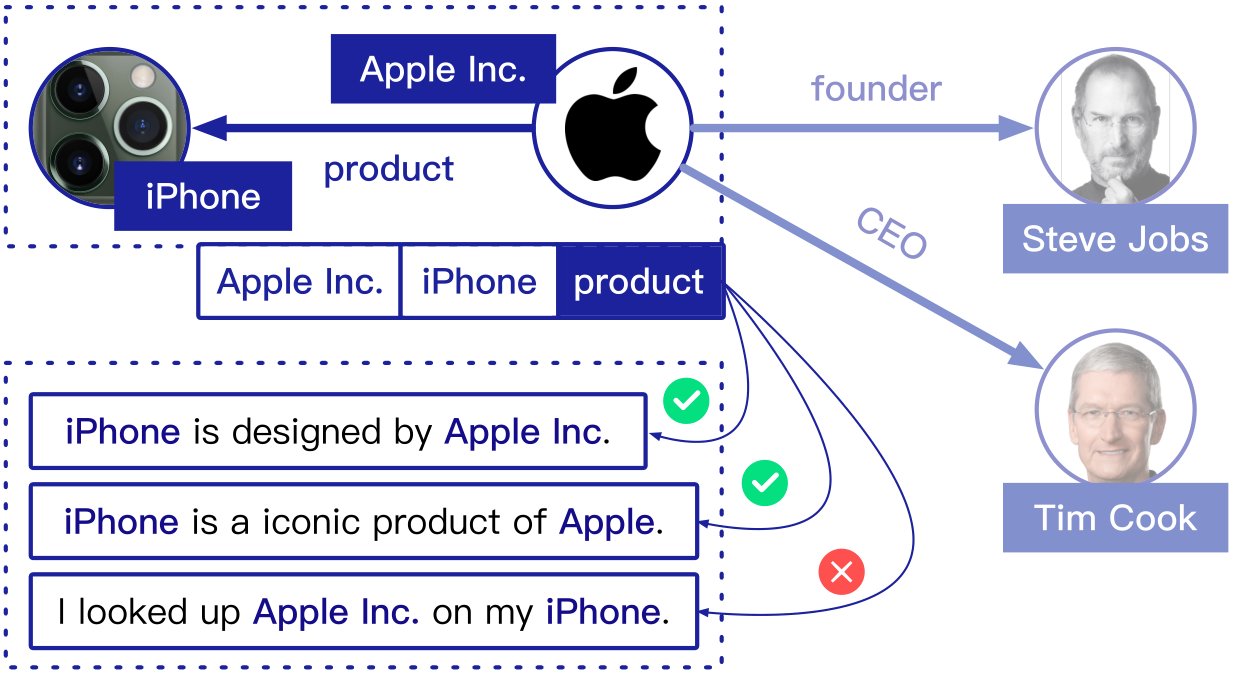
上图是一个远距离监督的例子,有了事实(Apple Inc.,Product,iPhone),DS找到所有提到两个实体的句子,用关系“product”标注这些句子。
远程监督是自动标注训练数据的有效策略,但其过强的设定不可避免地产生错误标注。
现有用来解决噪声数据问题的方法可以被分为三种:
- 采用多实例学习方法,将具有相同实体对的句子组合起来,然后从中选择信息量丰富的实例(informative instances)预测实体间关系。可以通过图模型,启发式选择策略和注意力机制选择(信息量丰富)实例。
- 引入额外的上下文信息实现去噪,比如引入知识图谱来指导示例的选择,采用多语种的语料库以实现数据的一致性和互补性。
- 利用复杂的机制和训练策略来增强远程监督的NRE模型。结合不同的架构和训练策略来构建混合框架;通过在训练期间改变不确信的标签,引入了软标签方案;强化学习和对抗训练。
开放的问题:
- 现有的DS方法主要对自动标注的实例去噪。目前的DS方案仍然类似于(Mintz等人,2009)中的原始方案,它只是涵盖了在相同的句子中提到实体对的情况。为了实现更好的覆盖和更少的噪声,探索更好的自动标记数据的DS方案也是有价值的。
- 受到最近预训练语言模型和主动学习(active learning)的启发,利用大规模未标记数据及利用知识图谱,在循环中引入人类专家知识也是有相当的前景的。
3.2 更高效地学习
现实世界的关系分布是长尾的,只有常见的关系有足够的训练实例,绝大部分的关系和实体对的可用样例非常有限。
DS数据集NYT-10和Wiki-distance的训练部分的关系分布(对数标度),表明现实世界的关系分布存在长尾问题,其中许多关系甚至只有不到10个训练实例。
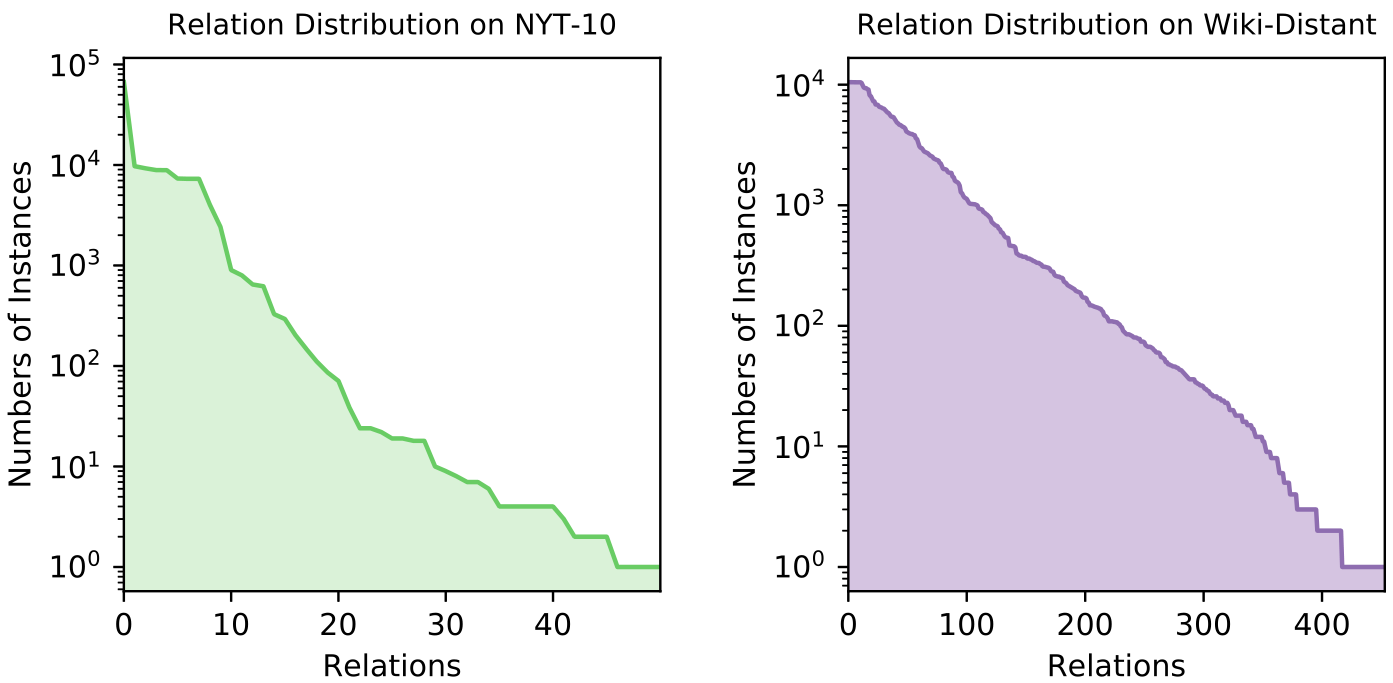
小样本学习(few-shot learning)适合解决这一问题。
该基准采用N-way K-shot设置,其中模型被赋予N个随机采样的新关系,以及每个关系的K个训练示例。在信息有限的情况下,RE模型需要将查询实例分类到给定的关系中。关系抽取小样本学习问题仅为每种关系提供极少量样例(如3-5个),要求尽可能提高测试样例上的关系分类效果。
如下图所示:
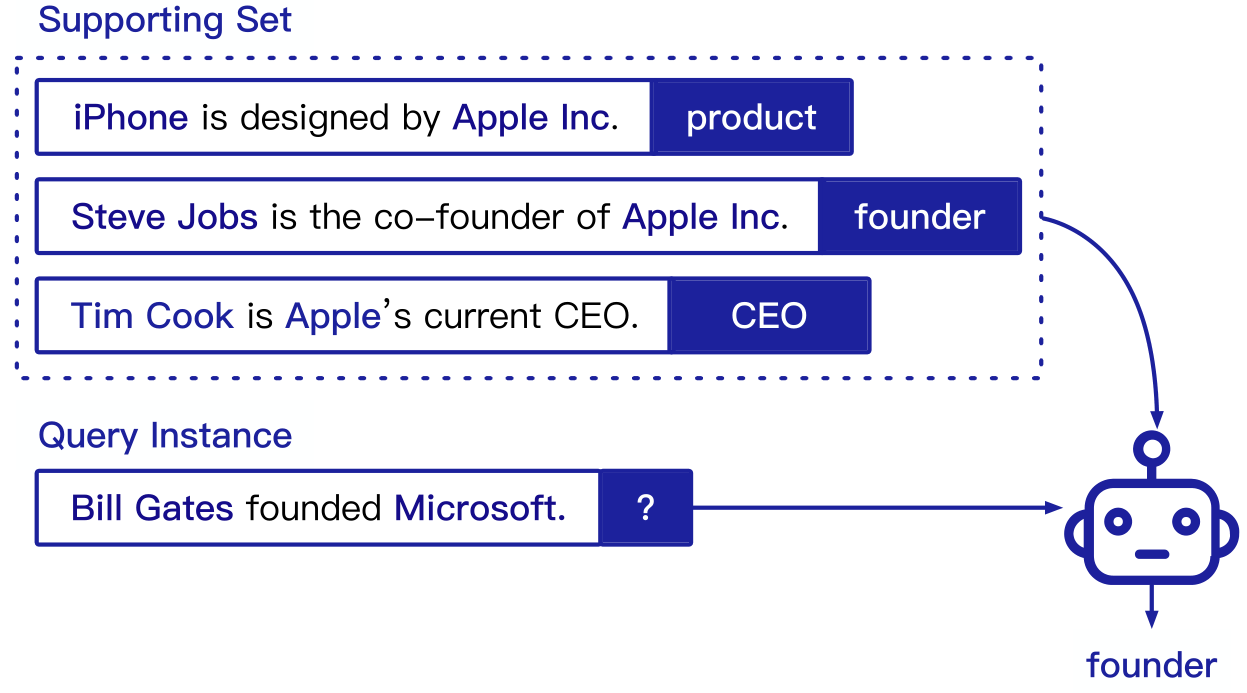
小样本学习的两种方式:
- 度量学习(Metric learning)学习现有数据的语义度量,并通过将查询与训练示例进行比较来对查询进行分类。通常涉及对语句层面表示的距离度量(相似度),也有工作使用词级别的注意力机制作出细粒度的比较。
- 元学习(Meta-learning),也称为“学会学习”,旨在通过对元训练数据上获得的经验掌握参数初始化和优化的方法
metric learning全称是 Distance metric learning,就是通过机器学习的形式,根据训练数据,自动构造出一种基于特定任务的度量函数。
现有的小样本学习的问题有:
(1)领域迁移(domain adaptation)
要将小样本学习模型用于生产环境中,应具备从资源丰富领域迁移到资源匮乏领域(low-resource domains)的能力。要求关系抽取模型在原语料进行训练后,还可以在新领域语料上进行小样本学习。
(2)以上都不是检测(none-of-the-above detection)
N-way K-shot设置中,假设所有查询都表示一个给定的关系。但实际上,大部分句子都与我们归纳兴趣的关系无关。传统的小样本模型不能很好地处理这个问题,研究如何识别NOTA实例至关重要。
(3) 现有的评估协议(evaluation protocol)可能会高估RE模型的表现。
和常规的关系抽取任务不同,小样本RE随机抽取N个关系,N通常很小(5 or 10)而且这N个关系很有可能不同,所以简化为非常简单的分类任务。
下面是一个实验
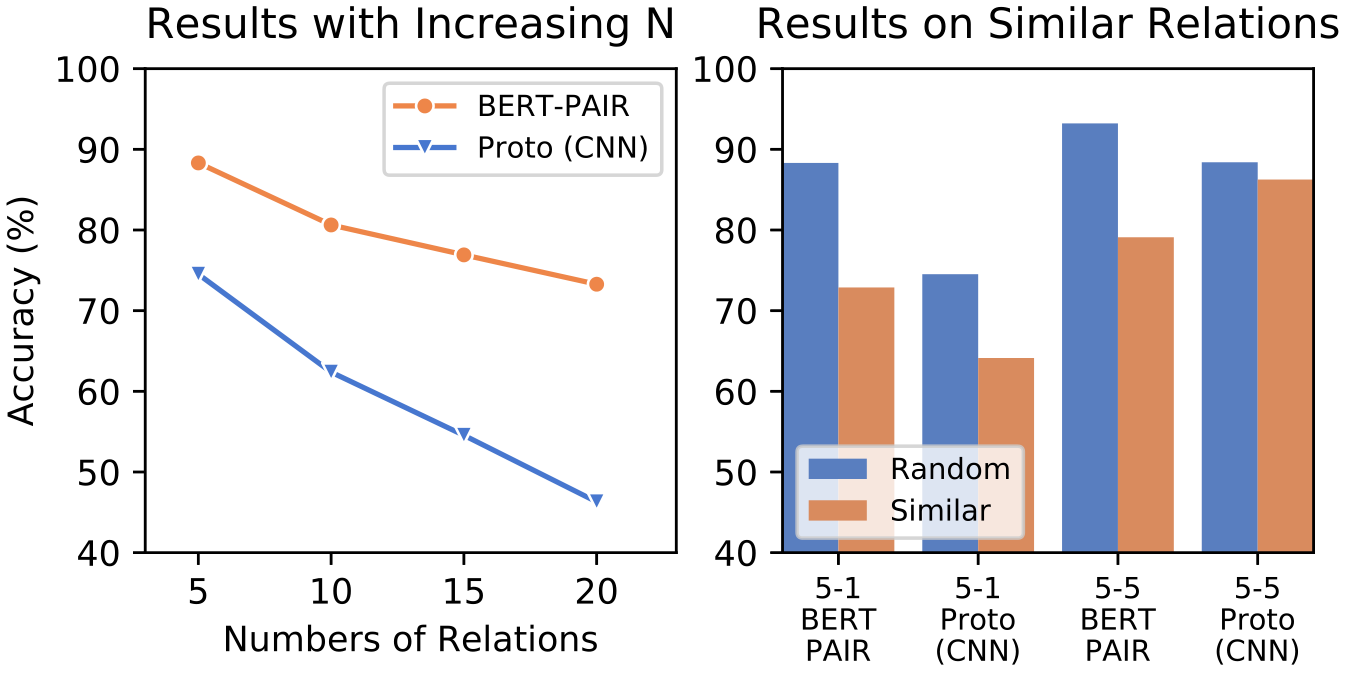
左图:随着关系数量N增大,模型的性能急剧下降,说明现有的基于小样本学习的RE模型远无法实际应用。
右图:人工挑选5个语义相似的关系而不是随机采样,few-shot RE模型的效果也会急剧下降。说明现有的基于小样本学习的模型不能真正的理解上下文语义。
3.3 处理复杂语境
下图是文档级RE的一个例子。给定一个包含几个句子和多个实体的段落,需要模型来提取文档中表达的这些实体之间所有可能的关系。
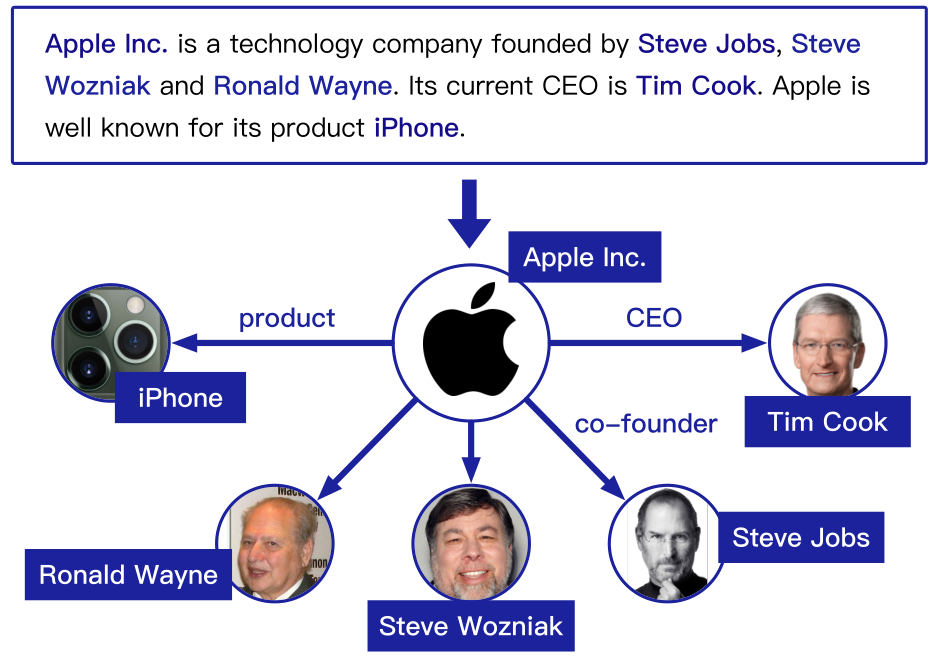
一个文档通常会提到许多呈现复杂跨语句关系的实体。大多数现有的方法集中在句子级关系抽取,因此不足以识别在一个长段落中多个句子共同表达的这些关系事实。事实上,大多数关系事实只能从诸如文档这样的复杂语境中提取,而不能从单个句子中提取。
目前有这样一些方法:
-
基于语法的方法(Syntactic methods),依靠从各种句法结构中提取的文本特征,如共指注释、依存句法分析树和话语关系,来连接文档中的句子。
-
构建句间实体图,可以利用实体间的多跳路径(multi-hop paths between entities)来推断正确的关系。
-
运用图结构神经网络(graph-structured neural networks)对跨句的依赖关系进行建模以进行关系提取,从而引入记忆和推理能力。
3.4 开放关系问题
大多数RE系统在人类专家设计的预先指定的关系集内工作。然而,现实世界中的关系无止境地增长,不可能仅靠人类来处理所有新出现地关系。因此,需要不依赖于预先定义的关系集的,工作在开放场景中的RE系统。
(1)开放信息抽取(Open information extraction, Open IE)
开放信息提取的一个例子,它提取关系参数(实体)和短语,而不依赖于任何预定义的关系类型。
(2) 关系发现(Relation discovery)
从无监督数据中发现没见过的关系。
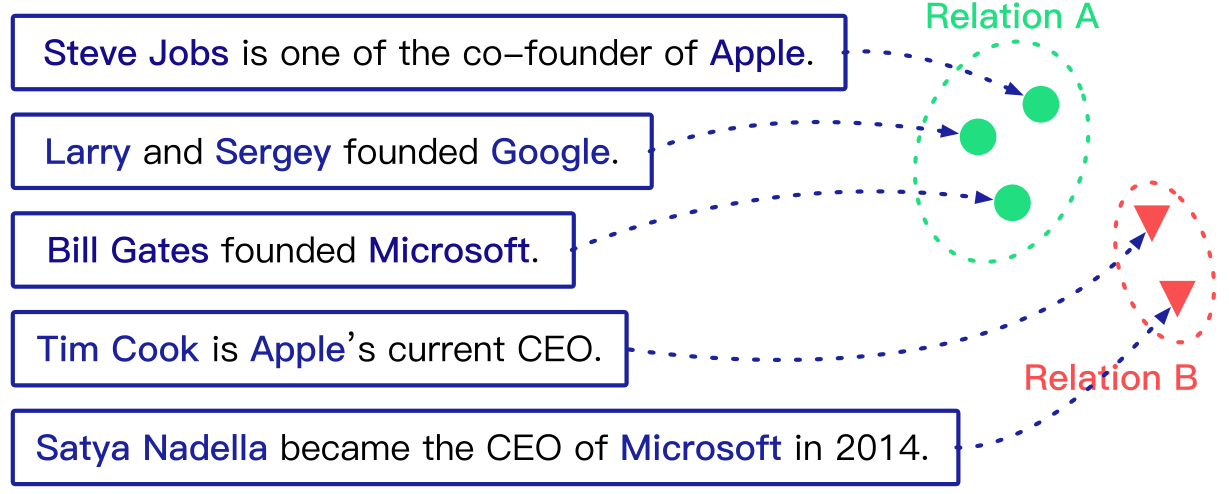
基于聚类的关系发现的一个例子,它通过聚类未标记的关系实例来识别潜在的关系类型。
仍未解决的问题:
- 在Open IE中规范化关系端语和参数对于下游任务至关重要。
- 在关系发现中几乎没有处理不适用(not applicable,N/A)关系
4. 其他挑战
4.1 从文本或名称中学习
在关系抽取的过程中,实体名称及其上下文均提供了有用的分类信息。
实体名称提供了种类的信息,缩小了可能的关系的范围。
例如,我们可以很容易地知道“JFK International Airport”是一个机场。
在训练过程中,也可以形成实体嵌入来帮助关系分类(如KG的链接预测任务)。另一方面,关系通常可以从实体对周围的文本语义中提取出来。在某些情况下,只能通过对上下文的推理来隐含地推断关系。
由于有两个信息来源,研究它们中的每一个对RE模型性能的贡献是很有趣的。
因此,我们为实验设计了三种不同的设置:
(1)正常设置(Normal),其中姓名和文本都作为输入;
(2)屏蔽实体(ME)设置,其中实体名称用特殊标记替换;
(3)仅实体设置(OE),仅提供两个实体的名称。
实验的所有模型来自OpenNRE
结果分别为:
BERT在Wiki80上的准确度
BERT在TACRED上的F-1值
PCNN-ATT在NYT-10和Wiki-Distant上的AUC值
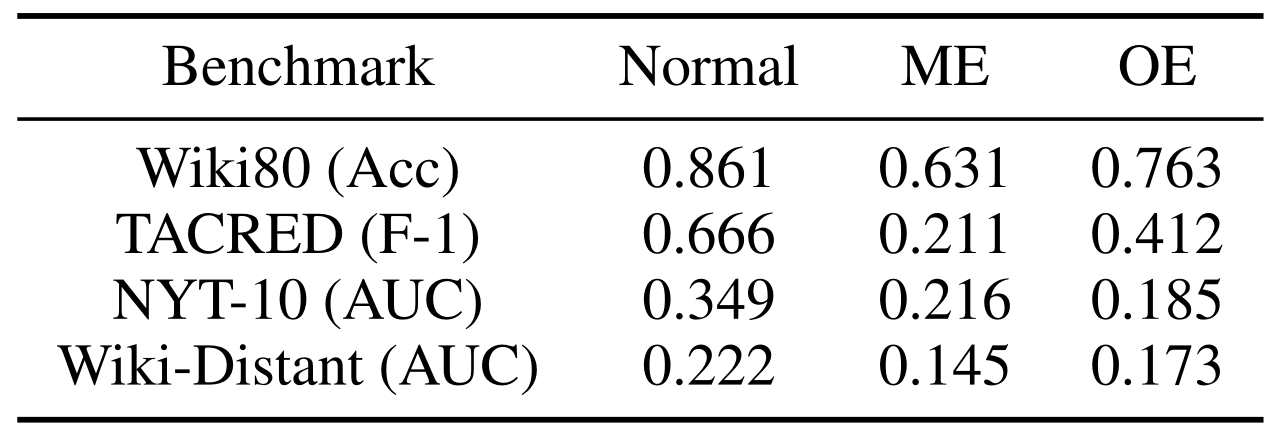
与正常设置相比,模型的ME和OE设置,均遭受巨大的性能下降,仅使用实体名称的效果会优于仅使用屏蔽实体的文本。实验结果与人的直接相反,在给关系分类时,模型从其名称中学到的更多。
4.2 针对特殊领域的RE数据集
目前,对于有监督的RE,数据集有
- MUC
- ACE-2005
- SemEval-2010 Task 8
- KBP37
- TACRED
远程监督
- NYT-10
小样本学习RE
- FewRel
文档级别RE
- DocRED
例如,句子之间的关系(例如,两个实体在两个不同的句子中被提到)是一个重要的问题,但是没有具体的数据集可以帮助研究人员研究它。
5. 备注
做笔记仅为了获得对关系抽取这个经典问题的整体认识,因此没有标注原综述中涉及的参考文献。
THUNLP的刘知远老师在2019年末写了一篇知乎专栏知识图谱从哪里来:实体关系抽取的现状与未来,可作为本篇论文的阅读辅助材料。
翻译参考:https://zhuanlan.zhihu.com/p/131275999














 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









