







有监督学习
有监督学习和无监督学习的区别在于输入的数据是否带有标签。有监督学习通过带标签的训练数据,学习如何预测未知数据的标签问题,其主要分为两个方面的问题:分类和回归。当输出是离散的,学习任务为分类任务,当输出为连续的,学习任务为回归任务。
回归
回归定义
Regression 就是找到一个函数 f u n c t i o n function function ,通过输入特征 x x x,输出一个数值 S c a l a r Scalar Scalar。例如股市预测、自动驾驶和推荐系统等。
模型步骤
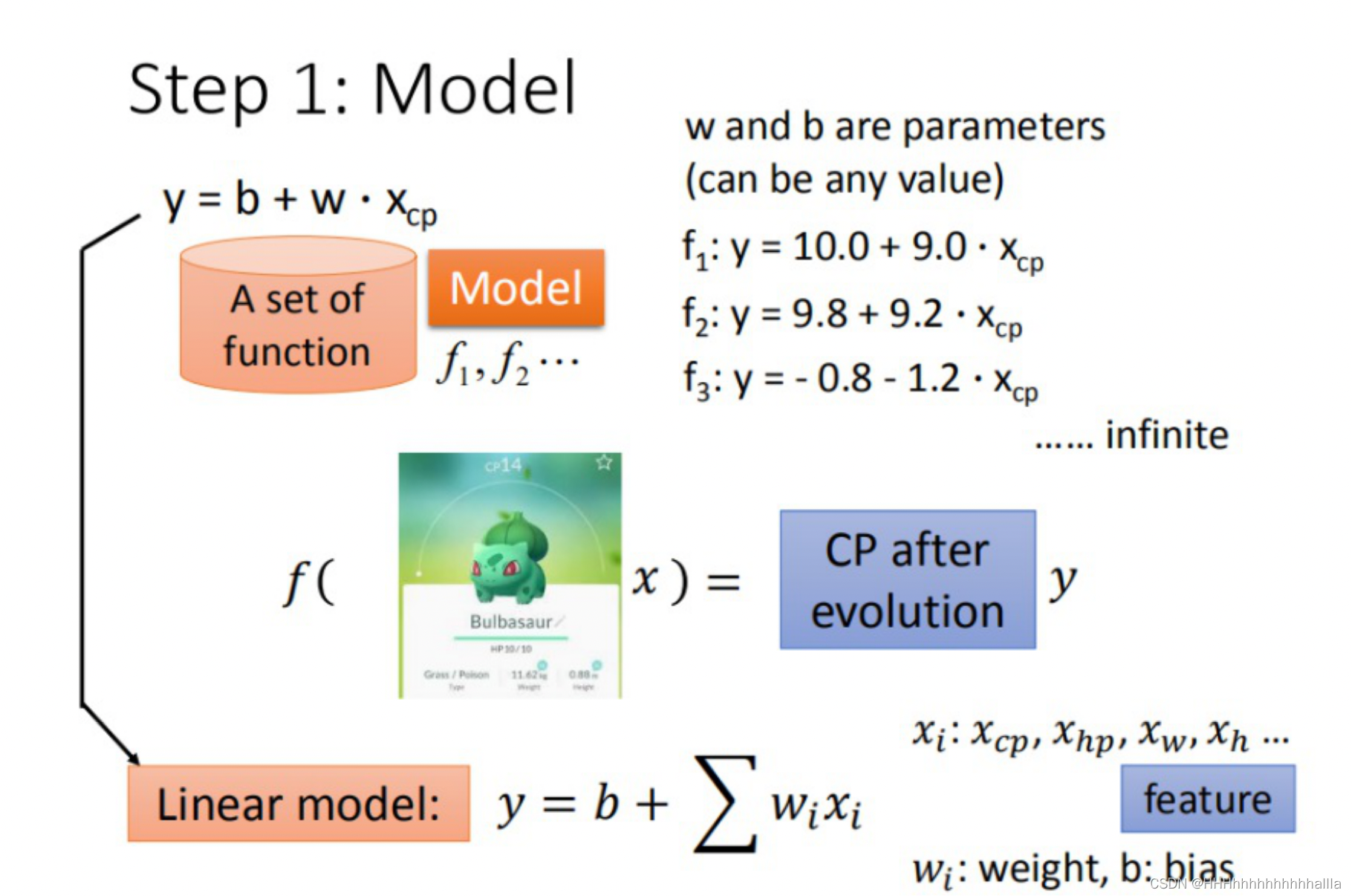
step1:模型假设,选择模型框架(线性模型)
step2:模型评估,如何判断众多模型的好坏(损失函数)
step3:模型优化,如何筛选最优的模型(梯度下降)
Step 1::模型假设 - 线性模型
a.一元线性模型(单个特征)
以一个特征
x
x
x 为例,线性模型假设
y
=
b
+
w
⋅
x
y = b + w·x
y=b+w⋅x ,所以
w
w
w 和
b
b
b 可以猜测很多模型:
f
1
:
y
=
10.0
+
9.0
⋅
x
f1: y = 10.0 + 9.0·x
f1:y=10.0+9.0⋅x
f
2
:
y
=
−
0.8
+
12.0
⋅
x
f2: y =-0.8 + 12.0·x
f2:y=−0.8+12.0⋅x
b.多元线性模型(多个特征)
在实际应用中,输入特征肯定不止
x
1
x_{1}
x1 这一个,所以我们假设线性模型 Linear model:
y
=
b
+
∑
w
i
x
i
y = b + \sum w_{i} x_{i}
y=b+∑wixi
- x i x_{i} xi :就是各种特征(fetrure) x c p , x h p , ⋅ ⋅ ⋅ x_{cp},x_{hp},··· xcp,xhp,⋅⋅⋅
- w i wi wi:各个特征的权重 w c p , w h p , ⋅ ⋅ ⋅ w_{cp},w_{hp},··· wcp,whp,⋅⋅⋅
-
b
b
b:偏移量
Step 2:模型评估 - 损失函数
从数学的角度来讲,我们使用距离。求【真实的y值】与【模型预测的y值】差,来判定模型的好坏,也就是使用损失函数(Loss function) 来衡量模型的好坏。
Loss function: L ( w , b ) = ∑ ( y i − ( b + w ⋅ x i ) ) 2 L(w,b)= \sum({y}^i - (b + w·x_{i}) )^2 L(w,b)=∑(yi−(b+w⋅xi))2

Step 3:最佳模型 - 梯度下降
已知损失函数是 L ( w , b ) = ∑ ( y i − ( b + w ⋅ x i ) ) 2 L(w,b)= \sum({y}^i - (b + w·x_{i}) )^2 L(w,b)=∑(yi−(b+w⋅xi))2 ,需要找到一个令结果最小的 L ∗ L^* L∗,在实际的场景中,我们遇到 的参数肯定不止 w w w, b b b。常用方法:梯度下降,根据微分结果,即当前斜率,根据斜率来判定移动方向。
一般步骤:
- 步骤1:随机选取一个 w 0 w^0 w0
- 步骤2:计算微分,也就是当前的斜率,根据斜率来判定移动的方向
- 大于0向右移动(增加 w w w)
- 小于0向左移动(减少 w w w)
- 步骤3:根据学习率移动(移动的步长)
- 重复步骤2和步骤3,直到找到最低点
单个特征:

多个特征:


常见问题
当建立的模型越来越复杂时,即加入越来越多的特征时,可能会出现过拟合的问题,即在training set上表现优秀的模型反而在testing set上的效果更差。

步骤优化
1.重新定义模型
2.加入更多特征和更多输入数据
3.加入正则化,考虑每个特征的权重之和















 6645
6645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









