







数据预处理
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. 数据预处理
1.1 读取数据
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..','data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')

默认情况下,以下值被解释为 NaN:‘’、‘#N/A’、‘#N/AN/A’、‘#NA’、‘-1.#IND’、‘-1.#QNAN’、 ‘-NaN’、‘-nan’、‘1.#IND’、‘1.#QNAN’、‘’、‘N/A’、‘NA’、‘NULL’、‘NaN’、‘n /a’、‘nan’、‘null’。
一个问题:可以看到 NumRooms 识别为 float,而 Price 识别为了 int 类型,那么 pandas 的 read_csv() 函数是怎么识别一个数是 float 还是 int ?
谁知道这个问题答案的话评论区告诉我一下。
1.2 处理缺失值

其中 inputs 为 data 的 [0, 2) 列的所有行
iloc[ ] 中的参数为前闭后开

对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
简单讲就是把所有的类别值全部分为多个列,列数为类别数+1,然后进行 one-hot 编码。dunmy_na 参数默认为 False,默认不生成 xxx_nan 列。
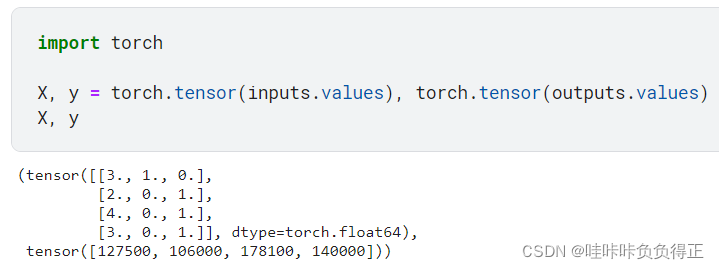
1.3 转换为张量格式
2 . 练习
2.1 删除缺失值最多的列

isna() 会输出布尔值,如果为 nan 就是 True,否则为 False。
drop 中的 axis 参数:
















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











