







最新版本的 MMDetection 已经支持 Open Images 数据集啦。在具体的实现过程中,我们使用了对长尾问题涨点明显的 Class Aware Sampler 策略进行训练。相较于基础的 Faster R-CNN ,Open Images Challenge 2019 的测试精度有超过 10 个点的提升( 54.87 -> 64.98);Open Images v6 的测试精度有接近 10 个点的提升(51.6 -> 60.0)。
那 MMDetection 究竟是怎样实现的呢?我们将按照以下 8 个步骤一一展开,带大家一探究竟。
- 准备工作
- Dataset 结构设计
- 数据集支持(标注文件的读取)
- 评价指标(mAP)的调研和支持
- 对齐评价指标
- 对齐训练结果
- Class Aware Sampler 调研和设计
- 再次对齐训练结果
准备工作
首先我们需要了解下: Open Images 是什么,它在经典检测器(如 Faster R-CNN)上的性能,以及 Open Images 标注文件的细节。
Open Images 数据集
Open Images 是 Google Research 在 2016 年推出的一个超大规模的目标检测数据集。到目前一共发布了 6 个版本(v1-v6),其中 v1-v4 以丰富图片数量、提升标注准确性和质量为主,v4 之后图片不再变动,以更新之前的标注框准确性,增加其他的标注信息为主。
总体来说,Open Images v6 包含 1,743,042 (1.7 M) 张图片,验证集包含 41,620 (41 K) 张图片,测试集包含 125,436 (125 K) 张图片。标注信息包含 601 个类别和 15,851,536 (16 M) 个标注框。与此同时,在 2018 和 2019 年,Open Images 还有一个挑战赛版本( Open Images Challenge),相较于 Open Images 发布版本,Open Images Challenge 标注信息类别减少到 500 类。
Open Images 在经典检测器上的性能
在经过了一系列调研之后,我们选择了 TSD 的性能作为 Open Images 训练结果对齐的目标。选择 TSD 的主要原因有 2 个:1.TSD 是 Open Images Challenge 2019 的第一名,并且 release 了相关模型的权重;2. TSD 使用 MMDetection 框架进行的开发,并且极大地保留了原有数据的格式。
Open Images Challenge 2019 的验证集在 Faster R-CNN 上能够达到 70.7。所以,我们的目标是:首先要支持 Open Images 数据的读取,然后训练一个 Faster R-CNN ,并且希望 mAP 要至少达到 70.7。
Open Images 标注文件
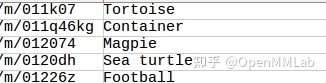
这里主要介绍 Open Images v6 数据集的标注文件,Open Images v6 的标注文件是 csv 文件,我们可以用 excel 打开来看一下它的标注细节。标注文件内容示意图如下所示:

可以看到,标注文件包含了 13 个信息,其中重要的信息包括: ImageID (图像索引); LabelName (类别信息);Xmin, Xmax, Ymin, Ymax (标注框位置);以及IsGroupOf(是否为一组对象,当某些区域有超过 5 个同类别实例且彼此严重遮挡时,就会标注为IsGroupOf,例如一群人或一碗苹果)。大致观察了标注文件以后,我们注意到:
- 虽然标注文件中有类别信息,但我们无法知道类别的含义。
- 标注文件中标注框是相对位置(即归一化之后的位置)。
那针对这 2 个问题,我们要怎么解决呢?
Dataset 结构设计
现在,我们按以下解决方案,重新设计下 Dataset 结构,以解决上文提到的 Open Images 标注文件存在的 2 个问题。
解决无法获取类别含义的问题
Open Images 在标注文件里面类别名使用的是 MID 格式的编码。当然,官方提供了类别映射文件 class-descriptions-boxable.csv,因此在加载数据时也需要加载这个文件。标注文件示例和类别映射文件示例如下图所示:
这样我们只需要加载这个文件并生成一个字典映射,就可以轻松地获取到类别的含义了。
解决标注文件中标注框是相对位置的问题
在训练和测试过程中,我们需要使用绝对位置的标注框进行 loss 计算或者 mAP 计算。所以在处理过程中,我们必须要获得图片的长宽信息,从而将标注框的相对位置转化为绝对位置。但遗憾的是: Open Images 标注文件并没有提供图片的长宽信息,我们还需要额外考虑如何获取图片的长宽信息。我们可以通过 pipeline 中的 LoadImageFromFile 获得到图片的长宽信息。
img_bytes = self.file_client.get(filename)
img = mmcv.imfrombytes(
img_bytes, flag=self.color_type, channel_order=self.channel_order)
if self.to_float32:
img = img.astype(np.float32)
results['filename'] = filename
results['ori_filename'] = results['img_info']['filename']
results['img'] = img
results['img_shape'] = img.shape
results['ori_shape'] = img.shape 所以在训练的时候,我们只需要在 LoadAnnotations 处理一下,通过 LoadImageFromFile 获得的图片长宽信息,然后将相对标注框转化成绝对标注框。
if self.denorm_bbox:
h, w = results['img_shape'][:2]
bbox_num = results['gt_bboxes'].shape[0]
if bbox_num != 0:
results['gt_bboxes'][:, 0::2] *= w
results['gt_bboxes'][:, 1::2] *= h
results['gt_bboxes'] = results['gt_bboxes'].astype(np.float32) 但是在测试时,尤其是计算 mAP 时,一次性获取所有图片的长宽信息就没有那么容易了。这是因为训练时,我们读取一张图片,处理一张图片,然后训练一张图片。但是计算 mAP 时,是所有的图片都结束测试后,我们才计算 mAP,图片的信息不能传到 dataset.evaluate 里面。
这时我们有两个选择:一是通过脚本提前获得测试图片的长宽信息;二是每次通过 pipeline 之后把图片的信息给保存下来。
这两种方法在 MMDetection 中都有支持,但是需要注意由于分布式训练在数据共享通信的一些问题,通过 pipeline 保存图片信息的方法会显著降低推理速度,因此不建议使用。
Open Images mAP 的支持
在支持 Open Images 过程中,最让人头疼的莫过于支持 Open Images mAP 的计算了。尽管 Open Images 的 mAP 计算基于 PASCAL VOC 数据集,但是还要考虑其他几个重要因素:
标注文件未包含的类要忽略
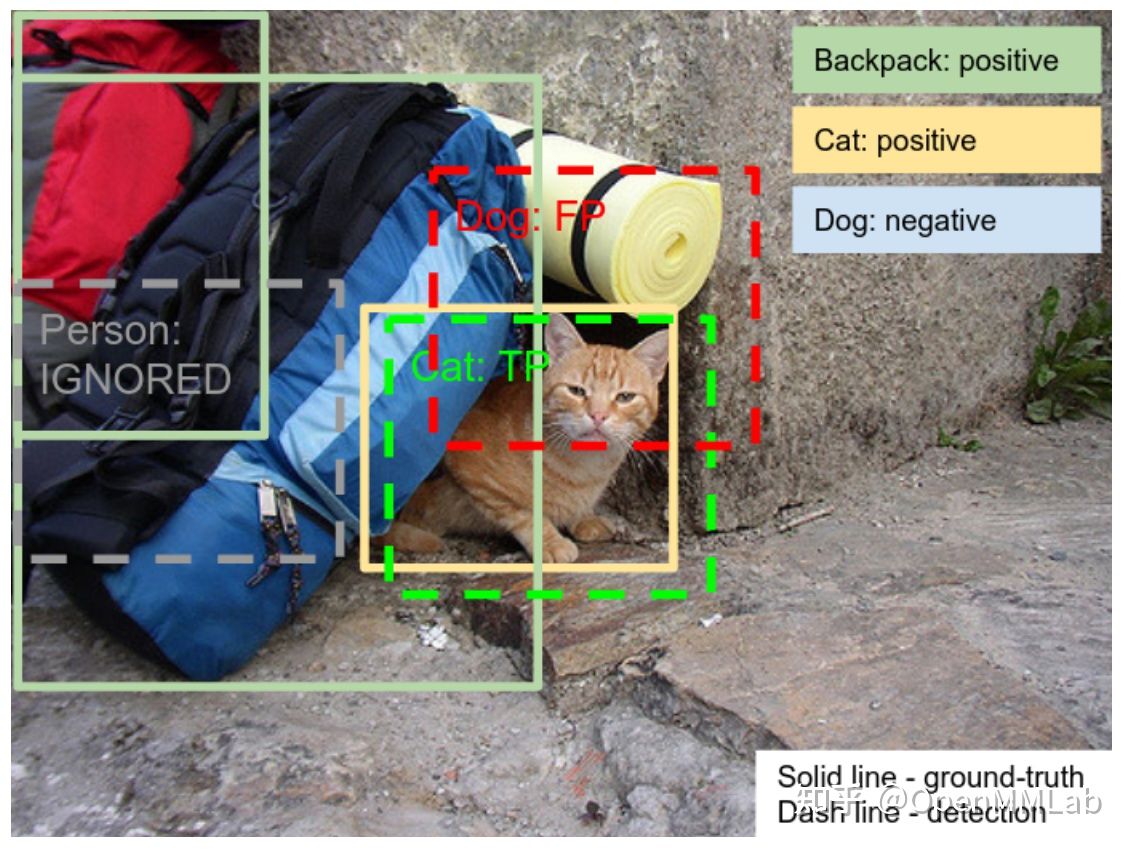
图片来源: https://storage.googleapis.com/openimages/web/evaluation.html
如上图所示,我们看到图片里面正类有 Backpack 和 Cat,负类有 Dog。所以当网络预测了一个 Person 类别的框时,我们需要忽略这个框。这里也就用到了另外一个非常重要的标注文件 validation-annotations-human-imagelabels-boxable.csv ,这个文件用来表示图片所包含的正负类别。

Confidence 为 1 的是正类,为 0 的是负类。
带有 GroupOf 标签的框要单独考虑
在前文我们介绍了 Open Images 独有的 GroupOf 参数,示例如下图所示:

图片来源: https://storage.googleapis.com/openimages/web/evaluation.html
可以看到:这一盆苹果没有一个一个标注,而是整体标注了一个框,然后使用了 GroupOf 参数。在计算 TP (True Positive) 和 FP (False Positive) 时,如果遇见了 GroupOf 的框,需要计算预测框和真实标注框 (GT) 的前景交叉比率 (Intersection over Foreground, IoF)。
另外,如果有多个预测框和一个 GT 框的 IoF 大于阈值,那么只保留 Score 最高的那个预测框设置为 TP,剩下的忽略掉;如果所有预测框和这个 GT 框的 IoF 小于阈值的话,那么就将 GT 框设置为 FP。
所以,我们的计算逻辑从之前的只计算每一个预测框和 GT 的交并比 (Intersection over Union, IoU) 变成了首先计算每一个预测框和非 GroupOf GT 的 IoU,然后获得预测框的 TP 和 FP 的信息,之后再计算每一个预测框和 GroupOf GT 的 IoF。
需要注意:如果某一个预测框已经是 TP,也就是匹配到了一个 non-groupof 的 GT,那么它不参与 IoF 的处理。在处理 IoF 的时候,因为会首先按照 Score 对预测框进行排序,如果某一个预测框 IoF 大于阈值,这个 GroupOf 框会变成已分配状态,如果后面还有预测框和这个 GroupOf 框的 IoF 大于阈值,那么会都忽略掉。由于代码实现比较长和复杂,这里只将代码的逻辑抽取出来进行简单讲解,感兴趣的同学可以去看看源码。
# 一些基础处理,获得 GT 和预测框的相关信息。
gt_ignore_inds = np.concatenate(
(np.zeros(gt_bboxes.shape[0], dtype=np.bool),
np.ones(gt_bboxes_ignore.shape[0], dtype=np.bool)))
gt_bboxes = np.vstack((gt_bboxes, gt_bboxes_ignore))
num_dets = det_bboxes.shape[0]
num_gts = gt_bboxes.shape[0]
tp = np.zeros((num_scales, num_dets), dtype=np.float32)
fp = np.zeros((num_scales, num_dets), dtype=np.float32)
...
# 如果 GT 中有 GroupOf 参数,并且考虑 GroupOf 进行计算
if gt_bboxes_group_of is not None and use_group_of:
# 将 gt_bbox 分为 non_group_gt_bboxes 和 group_gt_bboxes 并分别计算相应的 IoU 和 IoA(IoF)
assert gt_bboxes_group_of.shape[0] == gt_bboxes.shape[0]
non_group_gt_bboxes = gt_bboxes[~gt_bboxes_group_of]
group_gt_bboxes = gt_bboxes[gt_bboxes_group_of]
num_gts_group = group_gt_bboxes.shape[0]
ious = bbox_overlaps(det_bboxes, non_group_gt_bboxes)
ioas = bbox_overlaps(det_bboxes, group_gt_bboxes, mode='iof')
else:
# 和普通的 TPFP 计算一样,只计算 IoU
ious = bbox_overlaps(
det_bboxes, gt_bboxes, use_legacy_coordinate=use_legacy_coordinate)
ioas = None
if ious.shape[1] > 0:
# 计算 non_group_gt_bboxes 并分配 tpfp。
...
else:
# 如果没有 no-group-of 的话,所有的预测框都标注为 fp
...
if ioas is None or ioas.shape[1] <= 0:
# 如果不用 IoA 或者没有 group_gt_bboxes 的话直接返回
return tp, fp, det_bboxes
else:
# 计算 group_gt_bboxes 的 tpfp
det_bboxes_group = np.zeros(
(num_scales, ioas.shape[1], det_bboxes.shape[1]), dtype=float)
match_group_of = np.zeros((num_scales, num_dets), dtype=bool)
# 根据 group_gt_bboxes 的数量设定 tp
tp_group = np.zeros((num_scales, num_gts_group), dtype=np.float32)
# 分配 tpfp
...
# fp_group 是 tp_group 取反
fp_group = (tp_group <= 0).astype(float)
tps = []
fps = []
# 将计算得到的 group-of 和 non-group-of 的 tp,fp 和 det-boxes(预测框) 合并起来
for i in range(num_scales):
tps.append(
np.concatenate((tp[i][~match_group_of[i]], tp_group[i])))
fps.append(
np.concatenate((fp[i][~match_group_of[i]], fp_group[i])))
det_bboxes = np.concatenate(
(det_bboxes[~match_group_of[i]], det_bboxes_group[i]))
tp = np.vstack(tps)
fp = np.vstack(fps)
return tp, fp, det_bboxes
代码中有两个地方需要注意一下:
1. 如果遇到了预测框和 GroupOf 标注框的 IoF 小于阈值,那么设定 fp = 1 而不去设定 fp_group = 1。也就是这个框的 fp 是 non-groupof 的结果。
2. 因为会忽略掉一些预测框,所以最后返回的时候需要返回忽略掉一些预测框的 det_bboxes。
类别的类继承关系要考虑
Open Images 的类别是有父子类继承关系的,示例如下图所示:

可以看到:自行车头盔(Bicycle Helmet)和橄榄球头盔(Football Helmet)有一个父类叫做头盔(Helmet),在计算 AP 时,除了需要计算自行车头盔,也要将其 GT 和 预测框映射到它的父类也就是“头盔”上,一同计算 AP(即父类被认为是新的一个类别参与到计算 mAP 中)。
Open Images 专门提供了类别关系的 json 文件 bbox_labels_600_hierarchy.json,所以在计算 mAP 之前我们需要进行前处理。前处理总共处理两件事:一是忽略没有出现在 Image Level 中的类别预测框;二是当前类别的 GT 和预测框映射到它的父类中。
对齐 TSD 的结果
我们首先使用了 TSD 发布的 Open Images Challenge 2019 训练好的模型进行了精度验证,使用 TSD 的 evaluate 和 MMDetection 支持的 evaluate 进行了精度对齐。在对其过程中,发现了一处 TSD 实现不正确的地方:在获得 GT 包含的类别时 TSD 还加入了 [0],即把第 0 类加进了 gt_label 中。在改进了上述问题后,TSD 的实验结果和 MMDetection 计算的结果如下表所示:
| mAP | |
| TSD 官方提供精度 | 70.7000 |
| TSD 原始代码 | 70.7690 |
| 解决了 gt_label 加入 [0] | 70.8001 |
| MMdetection 直接读取 TSD 结果 | 70.8001 |
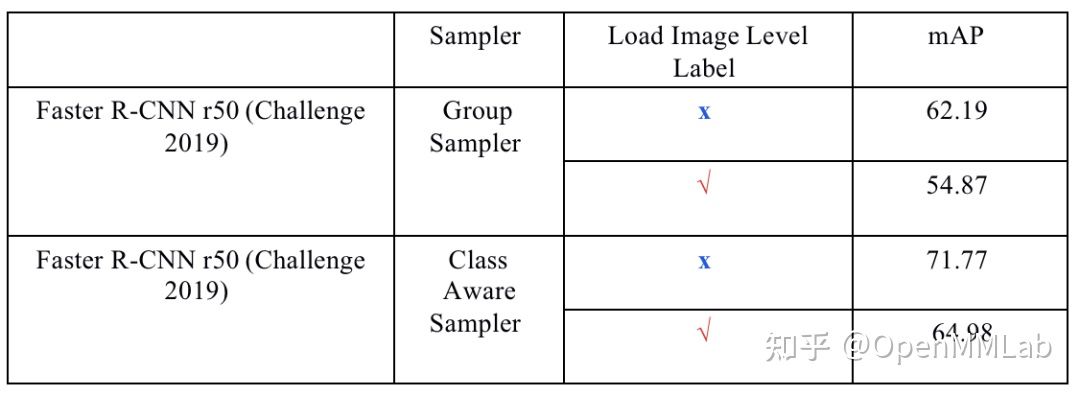
需要注意一点的是:TSD 在计算 mAP 过程中考虑了父类,但是没有考虑 Image level label。如果考虑了这一点,mAP 会有一定变化:
使用 Faster R-CNN 训练 Open Images Challenge 2019
在成功对齐了 TSD 的测试精度之后,我们使用最基础的 Faster R-CNN r50 FPN 开始了信心满满的训练。我们借鉴了 TSD 的相关设置,首先在 Open Images Challenge 2019 数据集上进行了训练,配置文件代码如下段所示:
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/openimages_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
model = dict(roi_head=dict(bbox_head=dict(num_classes=601)))
# Using 32 GPUS while training
optimizer = dict(type='SGD', lr=0.08, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(
_delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=26000,
warmup_ratio=1.0 / 64,
step=[8, 11])
但是训练结束之后发现,我们的精度和 TSD 差距很大:
| mAP | |
| TSD baseline | 70.80 |
| MMDet rerun | 54.87 |
我们重新查看了 TSD 的代码,发现它们 Sampler 没有简单地使用 Group Sampler,而是使用了 Class Aware Sampler,所以我们对 Class Aware Sampler 进行了简单调研。
Class Aware Sampler 介绍
关于 Class Aware Sampler
论文《Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks》首次提出使用 Class Aware Sampler 解决训练中的数据不平衡的问题,并且获得了 ILSVRC 2015 Scene Classification 挑战赛的第一名。
Class Aware Sampler 在训练过程中,尽可能统一地填充 mini-batch,并且避免相同的示例和类别一直以一个顺序出现。所以它使用了两个 list 来解决:一是 class list (List) 用于统计类别数据;二是 per-class image lists (List[List]),用来保存对应的类别在哪些图片中出现。
具体流程:首先从 class list 中抽取一个类别 X,然后从 per-class image lists 对应 X 类别的 images list 中抽取 1 张图片。当对应 X 类别出现的图片已经取完之后对这个列表进行打乱。实验结果表明这种方法可以将准确率提高 0.6%。
目标检测中使用 Class Aware Sampler
在目标检测中主要有两种 Class Aware Sampler 的方法,一种基于 TSD ,另一种基于 OLTR。两种方法都保留了 Class Aware Sampler 论文的逻辑,通过类别列表和类别对应图像列表来获取图片 ID。不同的是 TSD 保证了训练和实际数据的 total size 一致,而 OLTR 通过增加 reduce 参数来减少训练 total size 过大的问题。
由于代码实现比较长和复杂,兴趣的同学可以去看看源码:TSD 代码细节请参考这里,OLTR 代码细节请参考这里。
TSD 代码的实现方法
这种方法保证了训练和实际数据的 total size 一致,实现细节简单来说就是:
每一次按照类别列表,从每个类别对应的图片列表中取出第 1 张图片的 id。类别列表遍历结束后,随机打乱类别列表和类别对应的图片列表,重复至达到了 total size。核心代码如下:
def gen_class_num_indices(class_num_list):
# 首先对 class list 随机排列,之后从对应的 class_dic list 中抽取第 1 个image序号, 返回的是一个 list 包含了 class_num 个数字。 对应的就是每个 iter 所索引的 image_id
class_indices = np.random.permutation(self.class_num)
id_indices = [
self.class_dic[class_indice + 1][
np.random.permutation(class_num_list[class_indice])[0]
]
for class_indice in class_indices
if class_num_list[class_indice] != 0
]
return id_indices
num_bins = int(math.floor(self.total_size * 1.0 / self.class_num))
indices = []
for i in range(num_bins):
indices += gen_class_num_indices(self.class_num_list)
# add extra samples to make it evenly divisible
indices += indices[: (self.total_size - len(indices))] # 不够的上补,疑问:为什么不能再随机1次 然后去掉多余的
Distribution Balance Loss 实现方法
该方法最大程度上保留了 Class Aware Sampler 的论文逻辑,并且增加了 reduce 参数。其中比较核心代码如下:
class RandomCycleIter:
def __init__ (self, data, test_mode=False):
self.data_list = list(data)
self.length = len(self.data_list)
self.i = self.length - 1
self.test_mode = test_mode
def __next__ (self):
self.i += 1
if self.i == self.length:
self.i = 0
if not self.test_mode:
random.shuffle(self.data_list)
return self.data_list[self.i]
def class_aware_sample_generator (cls_iter, data_iter_list, n, num_samples_cls=1):
# next(cls_iter): 是从 cls_iter 里面取数,
# [data_iter_list[next(cls_iter)]: 是索引到 data_iter_list 里面去选择对应的索引
# * num_samples_cls: 是获得一个包含 num_samples_cls 个 data_iter_list[next(cls_iter) 的 list: [data_iter_list[next(cls_iter)], data_iter_list[next(cls_iter)], ...]
# temp_tuple: 最后获得了 num_samples_cls 个 对应图片的索引.
# num_samples_cls: 表示 1 次读取 label 的图片数量
i, j = 0, 0
while i < n:
if j >= num_samples_cls:
j = 0
if j == 0:
temp_tuple = next(zip(*[data_iter_list[next(cls_iter)]]*num_samples_cls))
yield temp_tuple[j]
else:
yield temp_tuple[j]
i += 1
j += 1
class ClassAwareSampler(Sampler):
def __iter__(self):
return class_aware_sample_generator(self.class_iter, self.data_iter_list,
self.num_samples, self.num_samples_cls)
... Class Aware Sampler 和 ClassBalanceDataset 的区别
Class Aware Sampler 乍一看和 MMDetction 中已经支持的 ClassBalanceDataset 好像做的事情差不多,但其实还是有一定区别:
- Class Aware Sampler 是按顺序遍历每个类别(可以选一次抽取几张图片),类别遍历完一次后进行第二次、第三次遍历;而 ClassBalanceDataset 是生成 1 个 list,然后再用普通的 sampler 来读取。
- Class Aware Sampler 不考虑图片中包含类别的因素。 ClassBalanceDataset, 考虑的是该张图片中包含类别最多需要重复的次数,并且计算重复次数的方式也不太一样。例如 image_1 包含 1,2 两个类别,那么如果 1 类别不需要重复,2 类别重复两次,则 Class Aware Sampler 训练中一共训练 image_1 三次;而 ClassBalanceDataset 只会训练两次(因为类别 2 需要重复次数最多)。
代码重新设计
参考了上述代码,我们重新设计了代码:
- Online 方法获得 class-dict;
- 采用 TSD 类型方法保证 total size 和 dataset 一致;
- 借鉴了 DB-Loss 的 RandomCycleIter 思想,更新了 TSD 获取图片索引的方法。
使用 Class Aware Sampler 重新训练
同样地,我们使用 Faster R-CNN r50 FPN,采用 Class Aware Sampler 策略对 Open Images Challenge 2019 数据集上进行了重新训练。配置文件代码如下段所示:
_base_ = ['faster_rcnn_r50_fpn_32x2_1x_openimages_challenge.py']
# Use ClassAwareSampler
data = dict(
train_dataloader=dict(class_aware_sampler=dict(num_sample_class=1))) 实验结果如下:
| Model | Sampler | mAP | Remark |
| Faster-rcnn-r50-fpn | Group Sampler | 54.87 | |
| Faster-rcnn-r50-fpn | Class Aware Sampler (TSD Version) | 64.84 | baseline |
| Faster-rcnn-r50-fpn | Class Aware Sampler (MMDet version) | 64.98 | baseline + 0.14 |
总结
本文我们带大家了解了 Open Images 在 MMDetection 实现的全过程。在具体的实现过程中,我们使用了对长尾问题涨点明显的 Class Aware Sampler 策略进行训练。相较于基础的 Faster R-CNN ,Open Images Challenge 2019 的测试精度有超过 10 个点的提升( 54.87 -> 64.98);Open Images v6 的测试精度有接近 10 个点的提升(51.6 -> 60.0)。
最后的实验结果如下表所示:
| Model | Backbone | Lr schd | Sampler | Dataset | mAP |
| Faster R-CNN | R-50 | 1x | Group Sampler | Open Images v6 | 51.6 |
| Faster R-CNN | R-50 | 1x | Class Aware Sampler | Open Images v6 | 60.6 |
| Faster R-CNN | R-50 | 1x | Group Sampler | Open Images Challenge 2019 | 54.9 |
| Faster R-CNN | R-50 | 1x | Class Aware Sampler | Open Images Challenge 2019 | 65.0 |
| Retinanet | R-50 | 1x | Group Sampler | Open Images v6 | 61.5 |
| SSD | VGG16 | 36e | Group Sampler | Open Images v6 | 35.4 |
MMDetection 支持 Open Images 后,大家可以使用更大规模的预训练模型在下游任务上进行 finetune,同时大家也可以使用 MMDetection 打 Open Images 的挑战赛啦。Class Aware Sampler 的支持也为大家提供了长尾问题的解决方案,方便大家获得更高的性能。
如果大家想复现或者进一步实验,可以参考相关配置文件和 PR。
- 支持 OpenImages 数据集: https://github.com/open-mmlab/mmdetection/pull/6331
- 支持 Class Aware Sampler: https://github.com/open-mmlab/mmdetection/pull/7436
欢迎大家来 MMDetection 体验,喜欢的话记得给 MMDetection 点个 star~
https://github.com/open-mmlab/mmdetectiongithub.com/open-mmlab/mmdetection















 1260
1260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









