






LLM 自对齐技术最新研究进展分享 系列文章继续更新啦!本系列文章将基于下图的架构,对当前 Self-alignment 相关工作进行全面梳理,厘清技术路线并分析潜在问题。
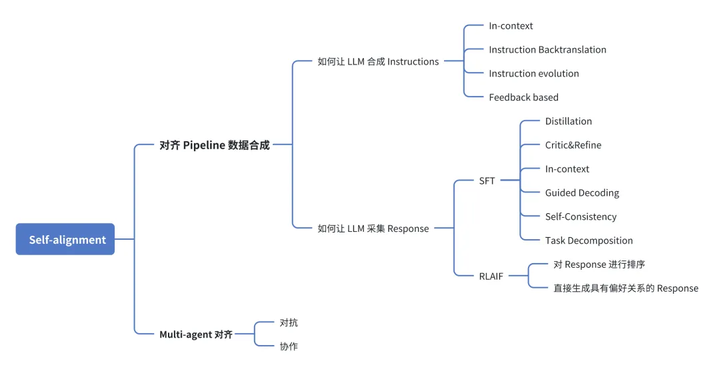
在前面的两篇文章中,我们分别探讨了 “如何让 LLM 合成 Instructions”和“如何让 LLM 采集 Response”,对于“对齐 Pipeline 数据合成”路线的 Self-alignment,我们需要关注的两大问题已全部有了答案。 本文我们将继续探讨 Self-alignment 的另一实现路线——Multi-agent 对齐。 除了对对齐 Pipline 的数据进行合成,另外一种新兴的方式就是依赖于多智能体的互动交互进行对齐。这里互动交互的方式根据组织关系可以分为对抗与协作两个大类。
对抗
Self-Play 指的是 LLM 自己在游戏中通过与其他 LLM 进行竞争对抗,来不断提高某方面的能力。这里游戏和对抗关系的设计多种多样,代表性的有如下几种:
-
Min-max 游戏:参与游戏的双方需要让对方获得奖励值变小,让自己获得的奖励值最大,奖励值的设置可以根据当前对齐目标而定。或者是两个模型进行博弈,一方需要产生优于另一方的的回答。
-
GAN:一个 LLM 作为生成器生成 Response,另一个 LLM 则作为辨别器用来判断和某个分布的一致性,此处的标准分布可以是 SFT 数据集中回答的分布。
-
辩论:多个 LLM 模仿人类进行辩论,这种方式可以让 LLM 生成连贯、具有说服力和逻辑性的回答。
-
Adversarial Taboo 游戏:该游戏中一个 LLM 需要诱导另一个 LLM 不经意间说出特定的单词,而另一个 LLM 则要推理猜出该单词。
-
Red-teaming Game:类似传统安全中的红蓝队对抗,多个 LLM 组成红队,通过多轮对话向蓝队 LLM 进行攻击,这里攻击指的是让蓝队模型产生有害的回答。
-
竞技场对战:类似于 Chatbot Arena,多个 LLM 在竞技场中互相挑战,并由 AI 来作为裁判,收集的胜负回答可以用于 RLHF 或者 SFT。
协作
多智能体之间也可以通过协作来进行对齐,这里的协作一般需要根据 LLM 想要提升的能力模拟对应的现实场景,模拟过程中会产生大量的合成数据,这些数据可以用来进一步 SFT。代表性的模拟场景有如下几个:
-
模拟社交场景:多个智能模仿人类进行社交,例如对 Instructions 和 Response 的社会场景进行角色扮演,模拟可能的结果,或者模拟人类日常社交谈话来提升社交智能,或者模拟构建小社会来对要对齐的 LLM 产生的回答进行评价和建议。
-
医疗诊断场景:多个智能体模拟医生和患者,在该模拟场景下医生智能体可以快速积累经验。
-
对话场景:两个智能体分别模拟正常用户和对话机器人,可以合成对话数据。
虽然协作方式也解决了对齐数据的问题,但是这种合成数据有以下几个问题:
-
现有工作表明随着训练数据的增多,模型性能会不断提高。但由于合成数据的分布与真实数据会有差异,这条定律对合成数据是否有效仍未可知,比如论文(https://arxiv.org/abs/2306.15895)表明简单的 Prompt 生成的数据会有明显的 Bias,如何取得数量和质量的均衡仍是一个问题。另外论文 (AI models collapse when trained on recursively generated data | Nature)发现如果在合成数据上重复训练可能会导致模型崩溃,后续论文(https://arxiv.org/abs/2404.01413)提出混合真实数据和合成数据来避免模型崩溃,这启发通过协作方式合成的数据是否也可以进一步混合真实数据来提高质量。
-
如何进一步提高合成数据的多样性和质量,如结合特定领域的知识进行合成(类 RAG),或多智能体的交互涵盖更多更全的场景,或包含更多的模态交互。
结语
至此 LLM 自对齐技术最新研究进展分享 系列文章到此就完结啦!Self-alignment 作为 AI 领域的一项前沿技术,其核心目标是通过减少人类干预,使大型语言模型(LLM)能够自我优化和调整,以更好地适应各种任务和指令。本系列文章综述了 Self-alignment 的两大实现途径:对齐 Pipline 数据合成和 Multi-agent 对齐。
通过对现有研究的梳理,我们可以看到,无论是利用 LLM 自身生成高质量的指令和响应,还是通过多智能体之间的互动来提升模型性能,Self-alignment 都展现出了巨大的潜力和应用前景。
系列传送门
LLM自对齐技术最新研究分享(一):对齐 Pipeline 数据合成(上)-CSDN博客
LLM自对齐技术最新研究分享(二):对齐 Pipeline 数据合成(下)-CSDN博客
InternLM2.5 是由上海人工智能实验室推出的书生·浦语系列模型的全新版本。相较于上一代,InternLM2.5 全面增强了在复杂场景下的推理能力,支持 1M 超长上下文,能自主进行互联网搜索并从上百个网页中完成信息整合。
开源链接:
https://github.com/InternLM/InternLM
在社区中广受好评的【书生大模型实战营第 3 期】正在火热进行中,带你从入门到进阶,大模型时代不迷航。OpenMMLab 公众号后台回复关键词【实战营】,获取最新报名链接、课程视频以及配套 PDF 资料。
在社区中广受关注的【社区开放麦系列直播】将每周带你解锁一个新知识,OpenMMLab 公众号后台回复关键词【开放麦】,获取历史配套 PDF 资料。
欢迎投递技术稿件:加微信 breezy0101

















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









