







 本文介绍了一种基于深度强化学习的移动机器人路径规划方法,利用LSTM处理雷达点云信息,结合CNN和DRL,实现了复杂环境下的自主导航。文章详细描述了环境搭建、算法设计与实现过程,包括DQN及其变种、经验回放等关键技术。
本文介绍了一种基于深度强化学习的移动机器人路径规划方法,利用LSTM处理雷达点云信息,结合CNN和DRL,实现了复杂环境下的自主导航。文章详细描述了环境搭建、算法设计与实现过程,包括DQN及其变种、经验回放等关键技术。
前言
一、运行环境
- macOS High Sierra 10.13.6
- Python 2.7.17 :: Anaconda, Inc.
- tensorflow-1.8.0-cp27-cp27m-macosx_10_13_x86_64
二、配置环境
-
官网下载Anaconda https://www.anaconda.com
-
为了方便下载资源,推荐更换清华conda镜像
conda config --prepend channels
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free -
创建虚拟环境
conda create -n tensorflow python=2.7
-
创建成功如下图

-
启动虚拟环境:conda activate tensorflow
-
关闭虚拟环境:conda deactivate
-
下载基于macOS CPU优化的tensorflow框架
https://github.com/lakshayg/tensorflow-build
选择对应版本下载.whl文件
-
安装tensorflow
pip install --ignore-installed --upgrade /path/to/binary.whl —user
-
验证tensorflow是否安装成功
ps:在使用Homebrew过程中 我发现一个有趣的现象

这时会一直卡在update中
解决方案:不要关闭这个终端 打开新的终端界面 输入相同指令 即可跳过update 正常下载

三、算法设计
- 整体结构
- 技术实现
-
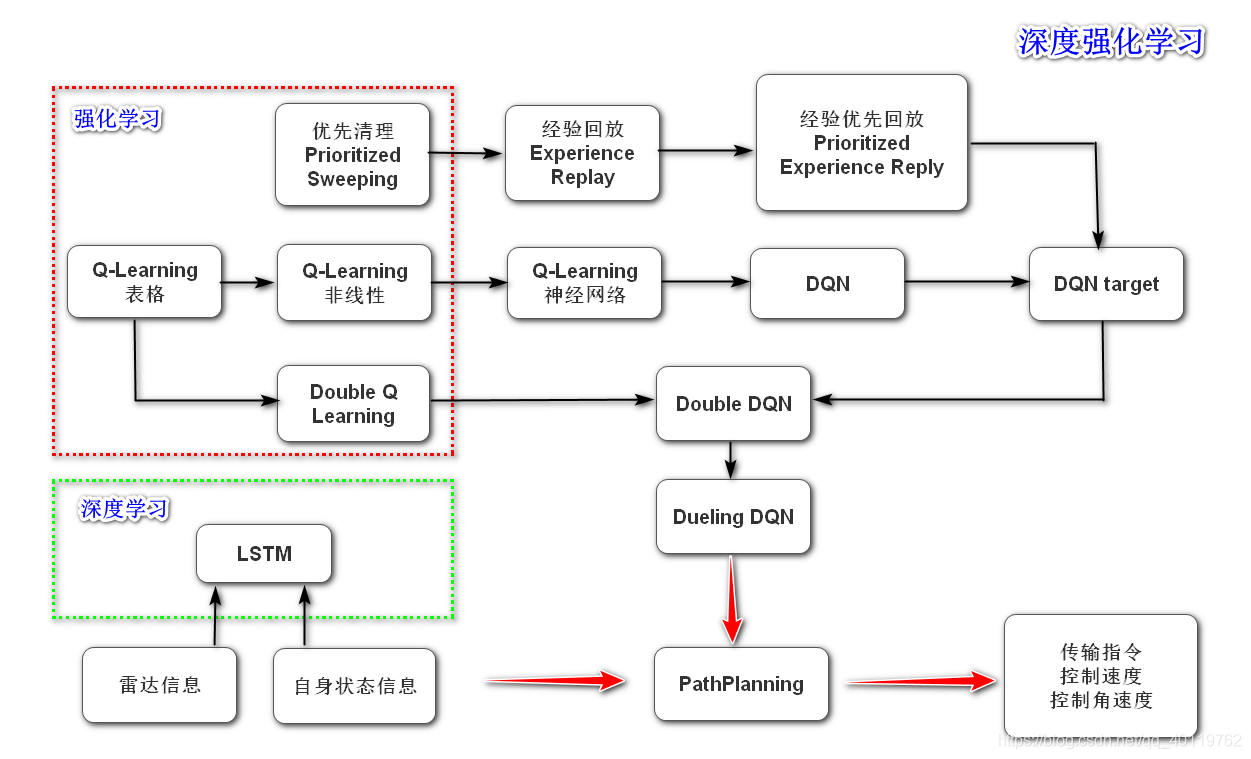
深度强化学习算法整体结构:
-
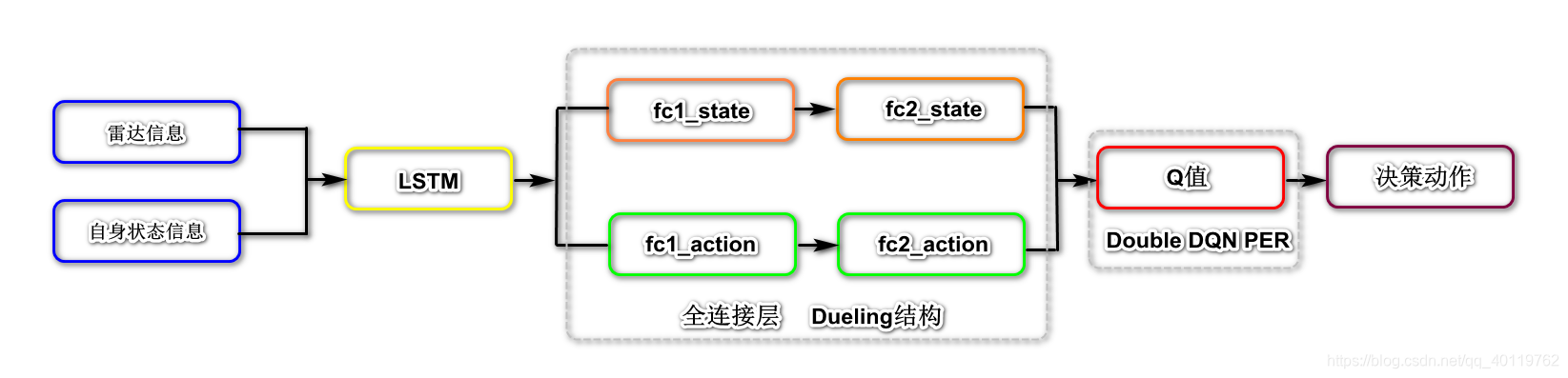
神经网络结构:
-
交互式展示应用核心业务:
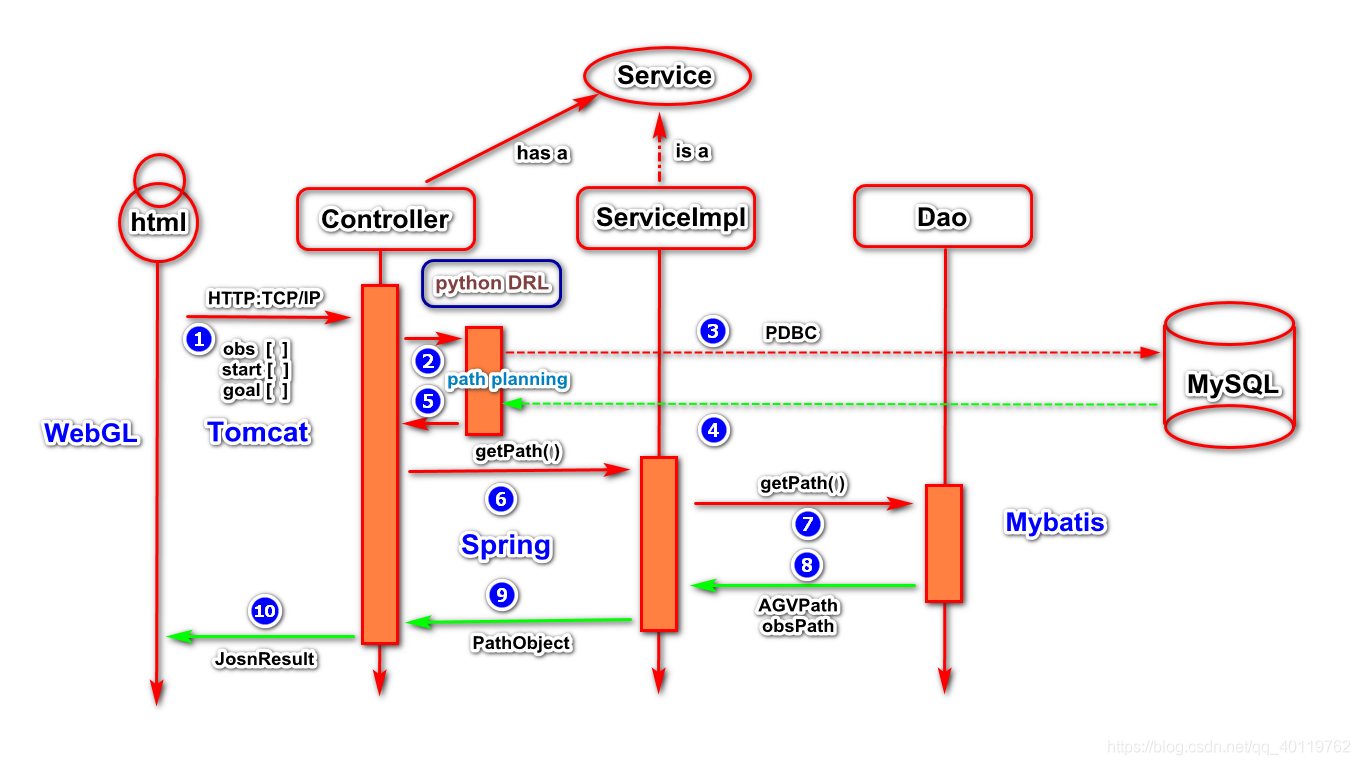
四、具体实现
-
DQN算法
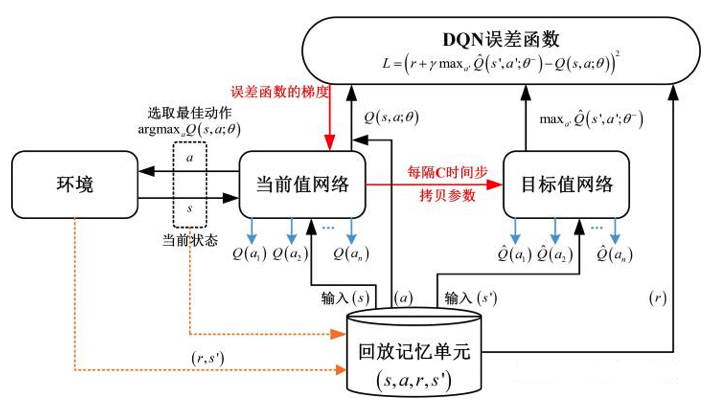

-
Double DQN
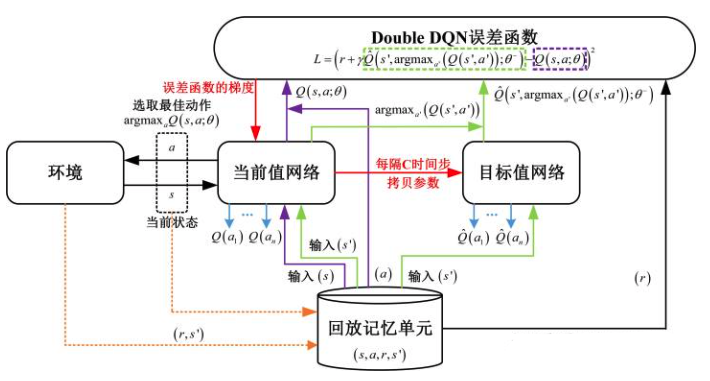
-
Dueling DQN
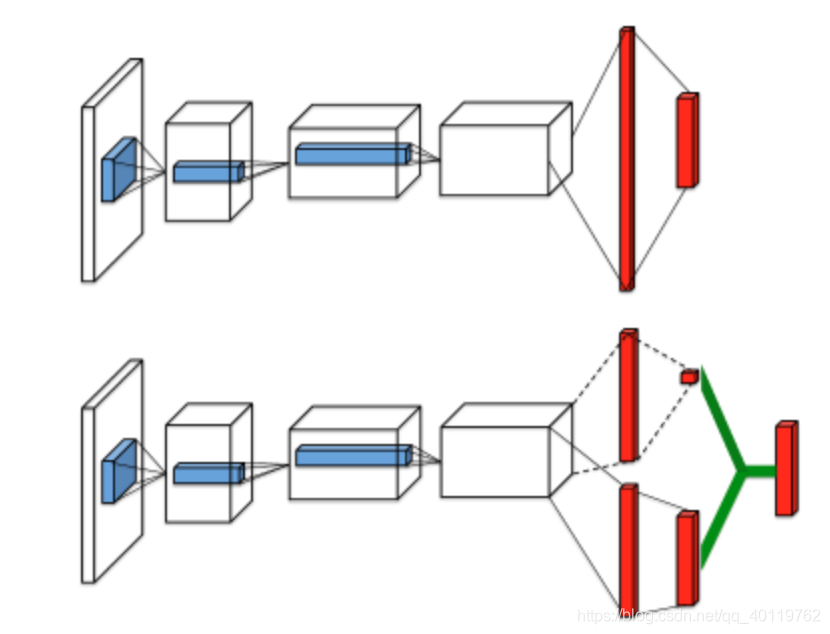
-
经验优先回放
-
自身状态信息
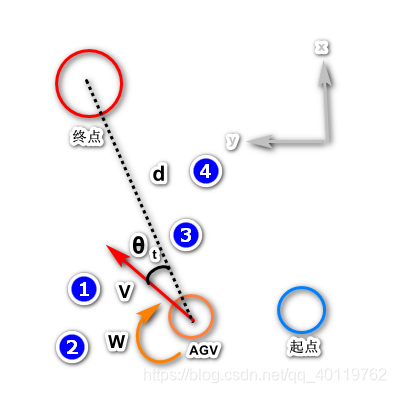
包括自身 速度 角速度 到目标点距离 以及与目标点方向夹角 四维信息 -
雷达信息
一次探测360维信息
探测范围360度全视野
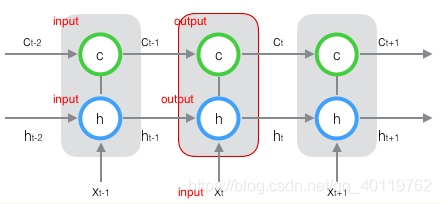
因为其产生的点云属于长序列信息,比较难直接拆分成一个个独立的样本来通过CNN进行训练。所以采用LSTM网络来处理LIDAR点云信息,其中cell单元为512个
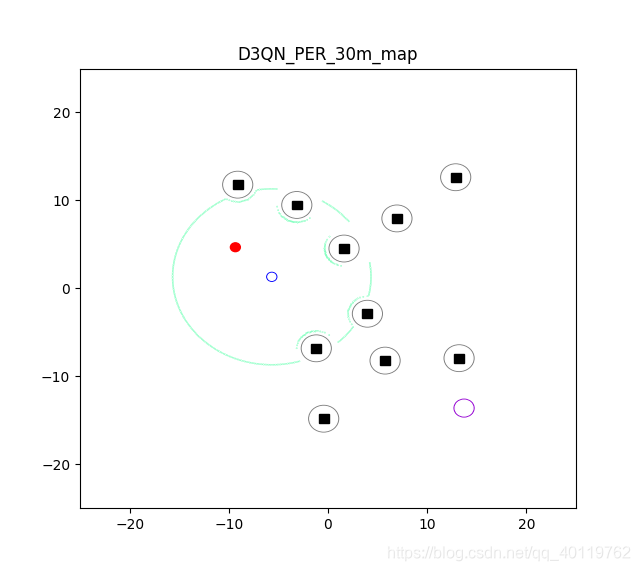
- 控制运动指令集
| 指令编号 | 速度 | 角速度 |
|---|---|---|
| 0 | 4m/s | -1rad/s |
| 1 | 4m/s | -0.5rad/s |
| 2 | 4m/s | 0.0rad/s |
| 3 | 4m/s | 0.25rad/s |
| 4 | 4m/s | 1.0rad/s |
| 5 | 2m/s | -1.0rad/s |
| 6 | 2m/s | 0.0rad/s |
| 7 | 2m/s | 1.0rad/s |
| 8 | 0m/s | -1.0rad/s |
| 9 | 0m/s | 0.0rad/s |
| 10 | 0m/s | 1.0rad/s |
[注: 以上参数仅作为参考 根据实际情况可以成比例修改]
- 算法参数
| 参数名 | 大小 |
|---|---|
| 衰减系数 | 0.99 |
| 学习率 | 0.001 |
| 贪婪策略阈值 | 0.1 |
| 记忆池大小 | 5000 |
| 训练步数阈值 | 50000 |
| 训练回合阈值 | 1200 |
| Q-现实更新步数 | 500 |
| 最小batchsize | 32 |
| 经验回放终止阈值 | 0.00001 |

3. 奖励参数
# 假如上一时刻到目标的距离<这一时刻到目标的距离就会有负的奖励
if self.d_last < self.d:
reward = reward - 0.1 * (self.d - self.d_last)
if self.d_last >= self.d:
reward = reward + 0.1 * (self.d_last - self.d)
# 速度发生变化就会有负的奖励
reward = reward - 0.01 * (abs(self.w_last - self.cmd[1]) + abs(self.v_last - self.cmd[0]))
# 到达目标点有正的奖励
if self.d < self.dis:
reward = reward + 20
# 碰撞障碍物以及边界有负的奖励
for i in range(len(self.obs_pos)):
if math.sqrt((self.robotstate[0] - self.obs_pos[i][0]) ** 2 + (self.robotstate[1] - self.obs_pos[i][1]) ** 2) < 2:
reward = reward - 1
self.done_list = True
if self.robotstate[0] >= 19.5 or self.robotstate[0] <= -19.5:
reward = reward - 1
self.done_list = True
if self.robotstate[1] >= 19.5 or self.robotstate[1] <= -19.5:
reward = reward - 1
self.done_list = True
- 移动障碍运动规则
for i in range(2):
a=random.uniform(0,0.2)
b=random.uniform(0,0.2)
for h in range(1,6):
self.obs_pos[i][0] =self.obs_pos[i][0] +a
self.obs_pos[i][1] =self.obs_pos[i][1] +b
for i in range(2):
a=random.uniform(0,0.2)
b=random.uniform(0,0.2)
self.obs_pos[i+2][0] =self.obs_pos[i+2][0] - a
self.obs_pos[i+2][1] =self.obs_pos[i+2][1] - b
for i in range(2):
a=random.uniform(0,0.1)
b=random.uniform(0,0.1)
self.obs_pos[i+4][0] =self.obs_pos[i+4][0] - a
self.obs_pos[i+4][1] =self.obs_pos[i+4][1] + b
for i in range(2):
a=random.uniform(0,0.2)
b=random.uniform(0,0.2)
self.obs_pos[i+6][0] =self.obs_pos[i+6][0] + a
self.obs_pos[i+6][1] =self.obs_pos[i+6][1] - b
for i in range(2):
a=random.uniform(-0.1,0.2)
b=random.uniform(-0.1,0.2)
self.obs_pos[i+8][0] =self.obs_pos[i+8][0] + a
self.obs_pos[i+8][1] =self.obs_pos[i+8][1] + b
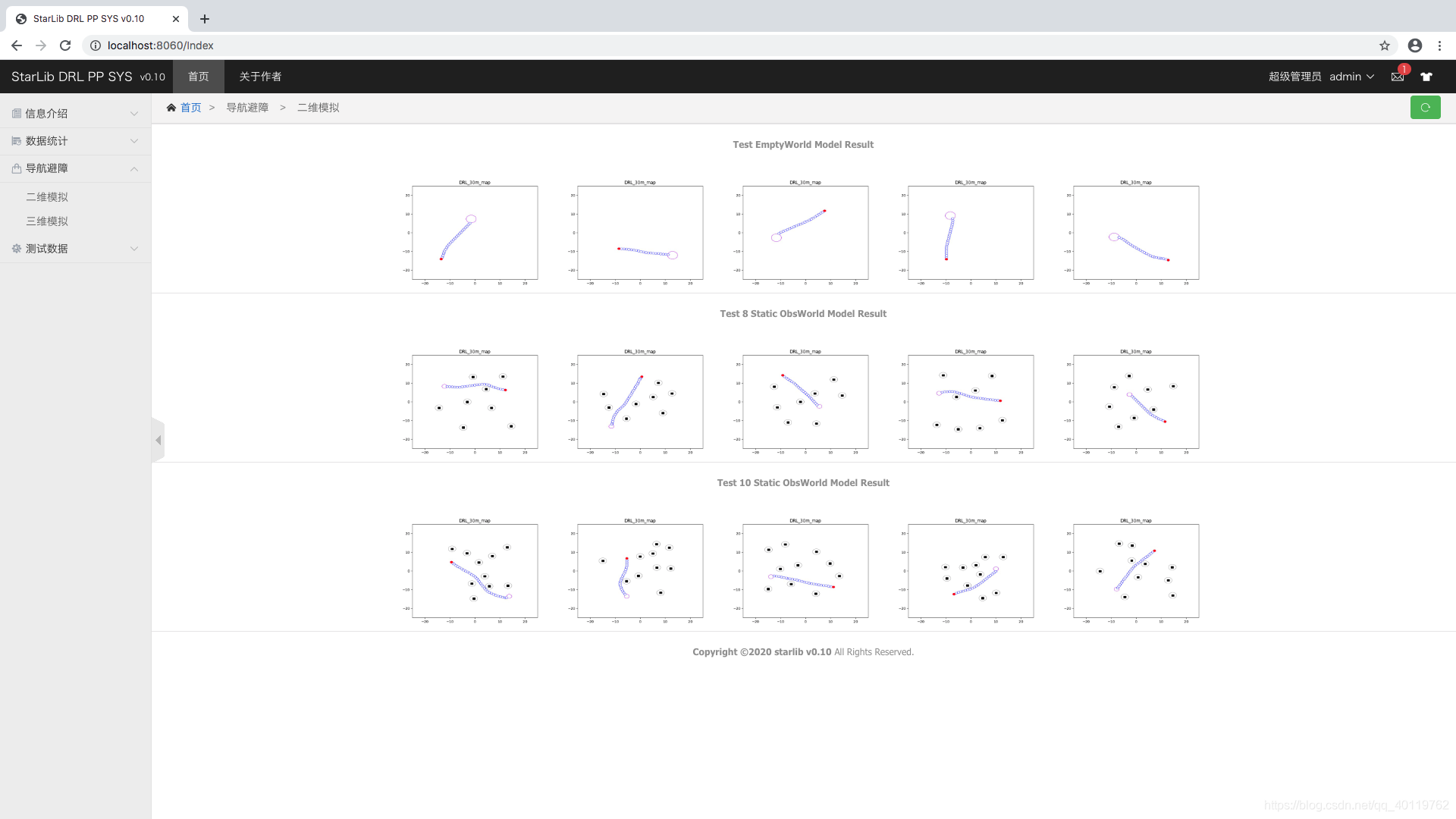
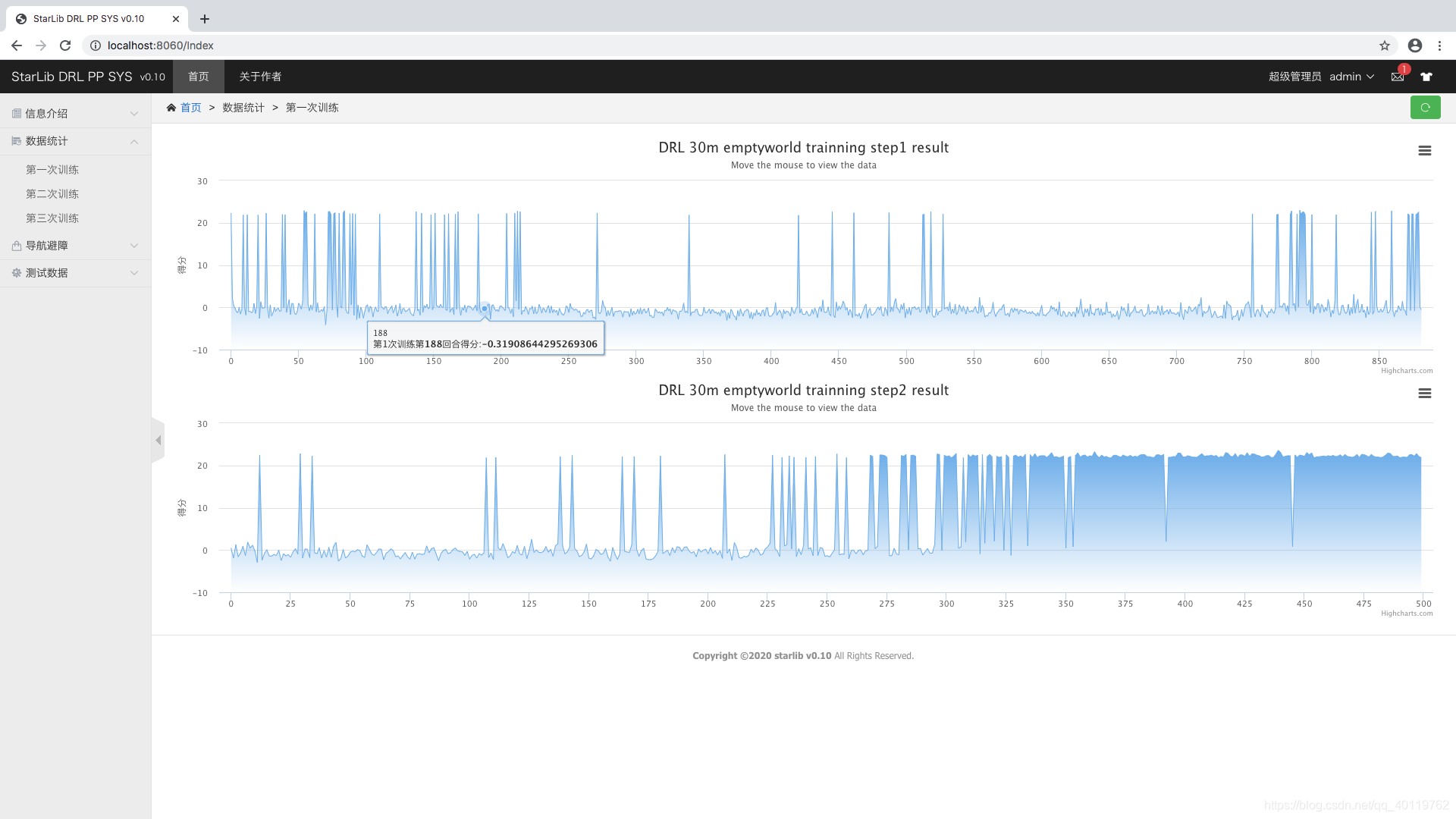
第一轮训练 无障碍条件下两次训练
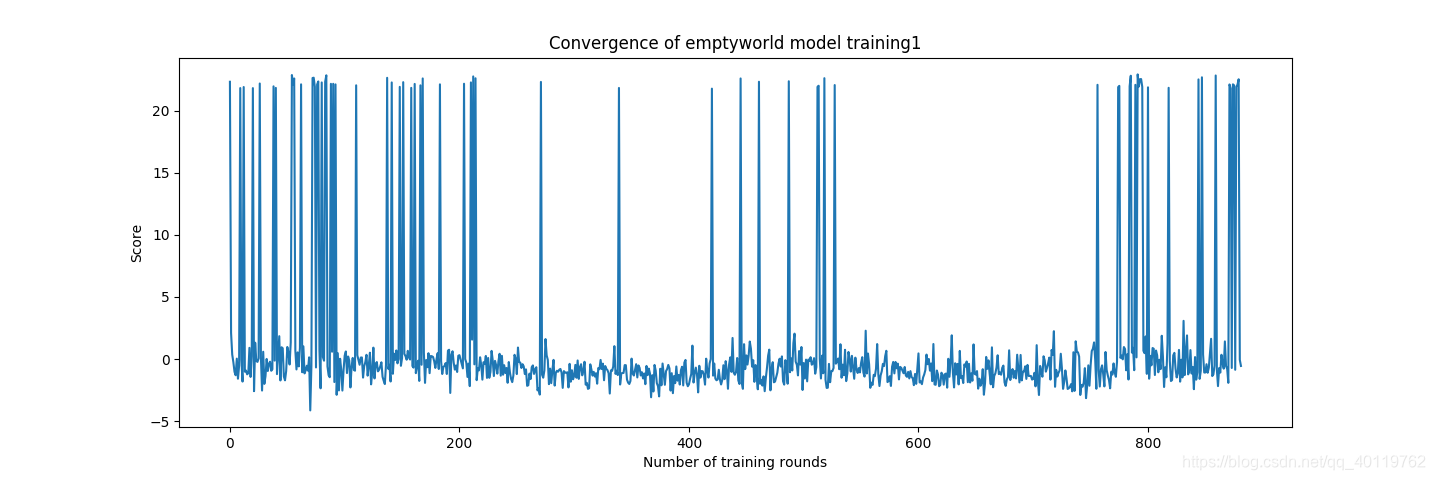
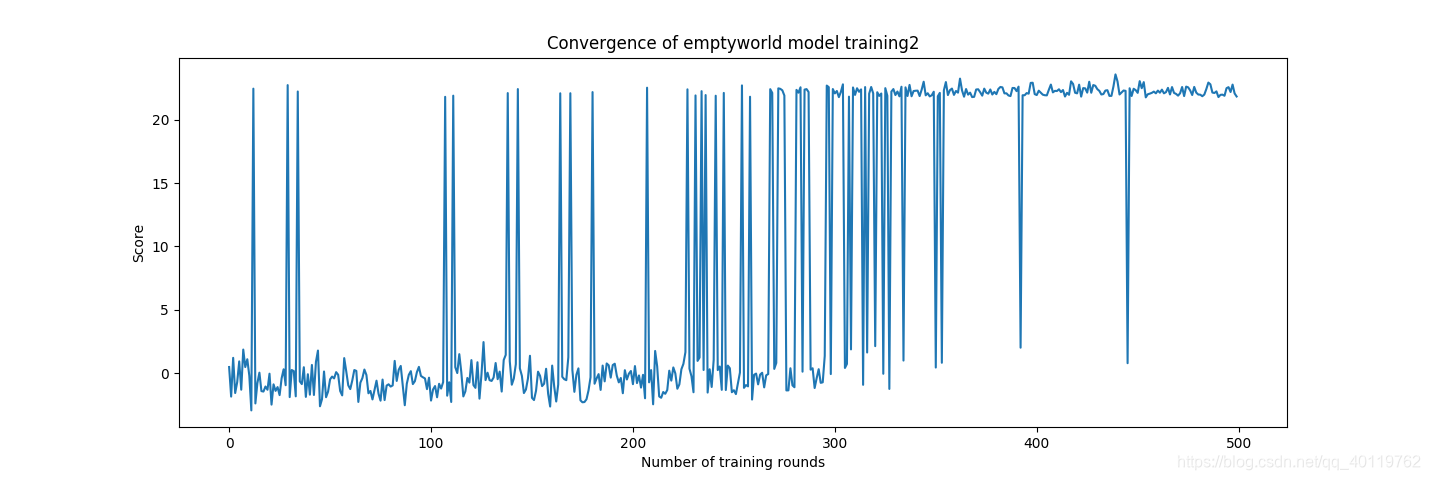
第二轮训练 八个静态障碍条件下训练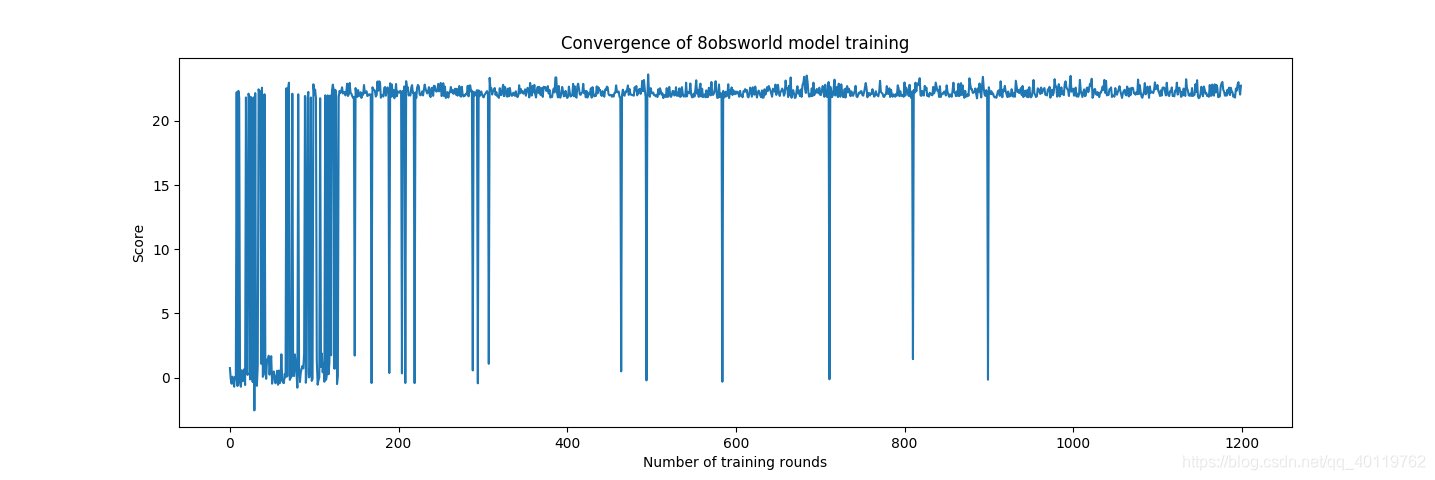
第三轮训练 十个动态障碍条件下训练
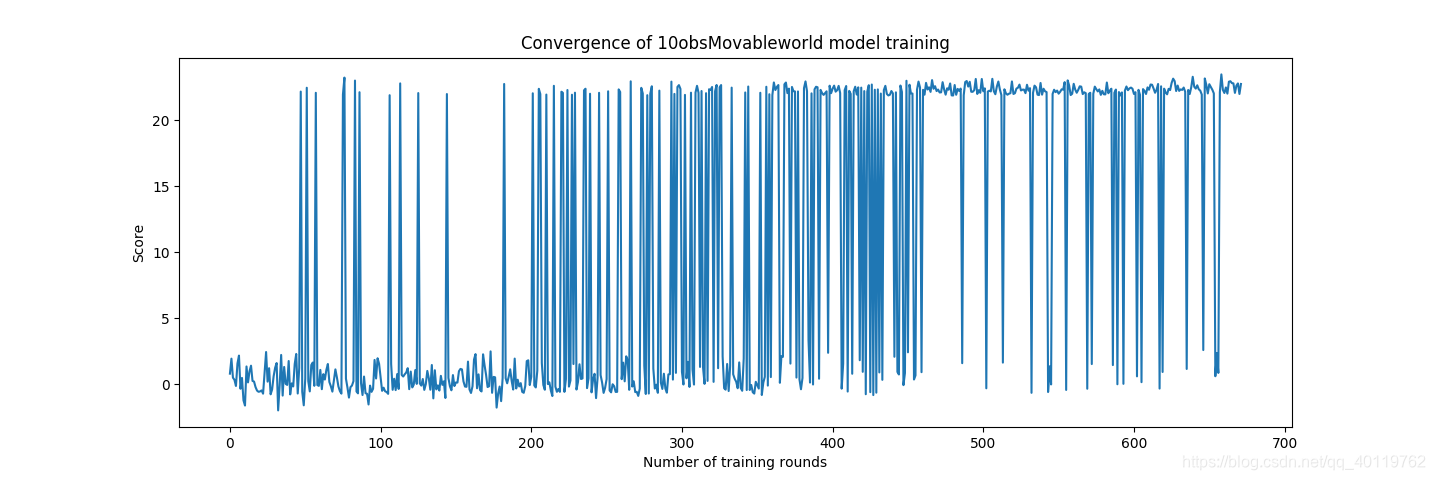
- 主要技术及基本原理


脚手架 简化Spring配置
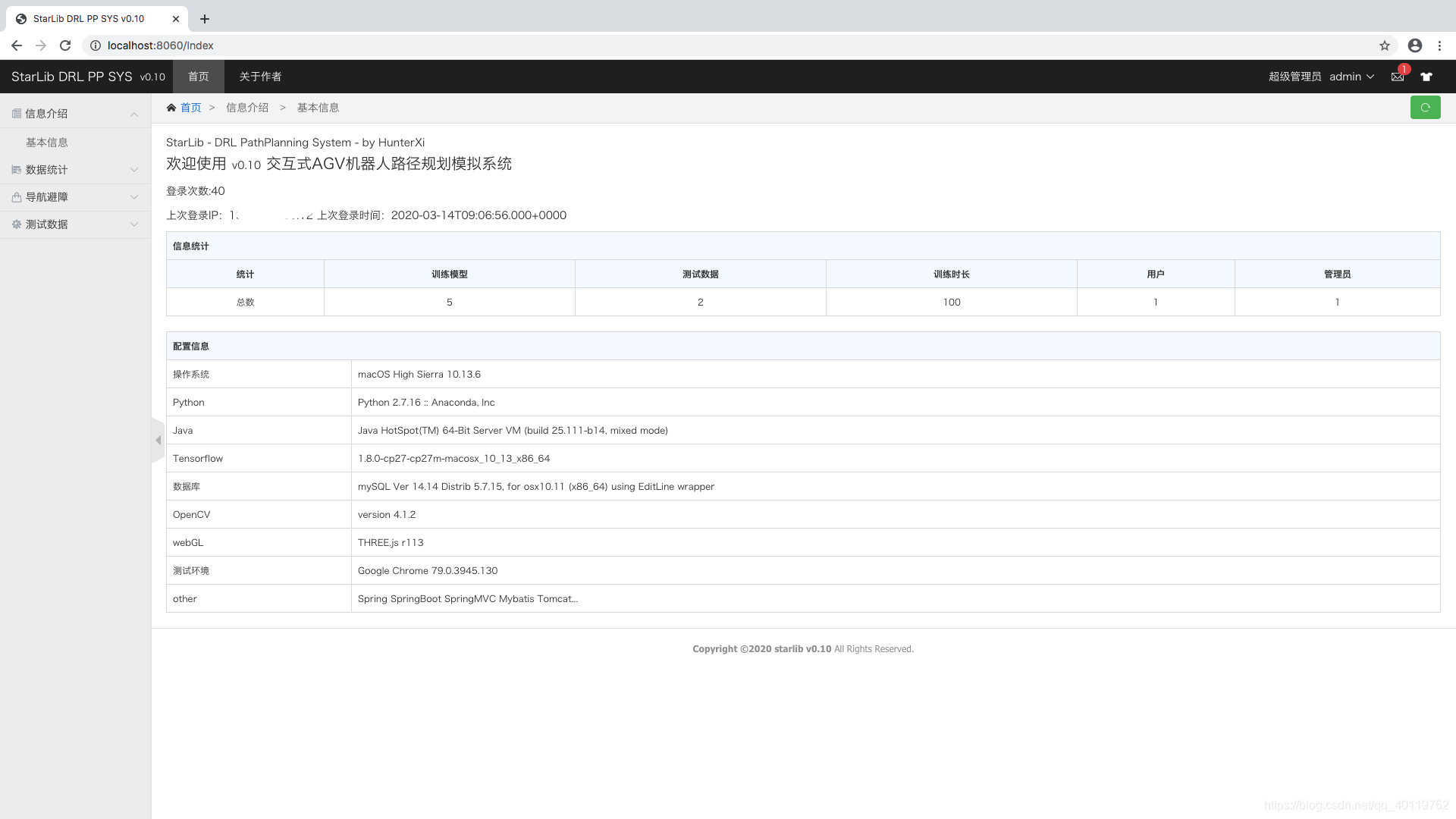
- 页面效果展示


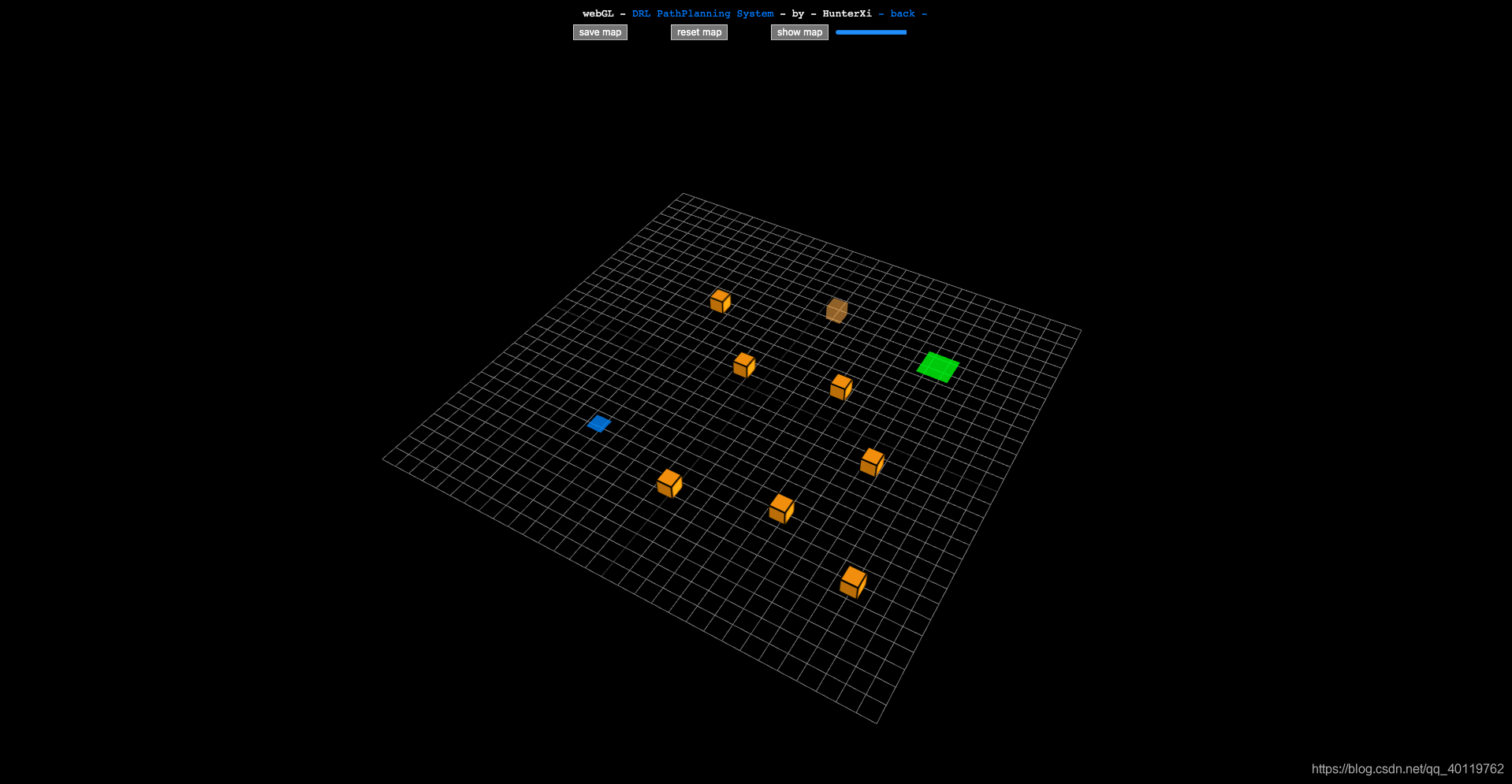
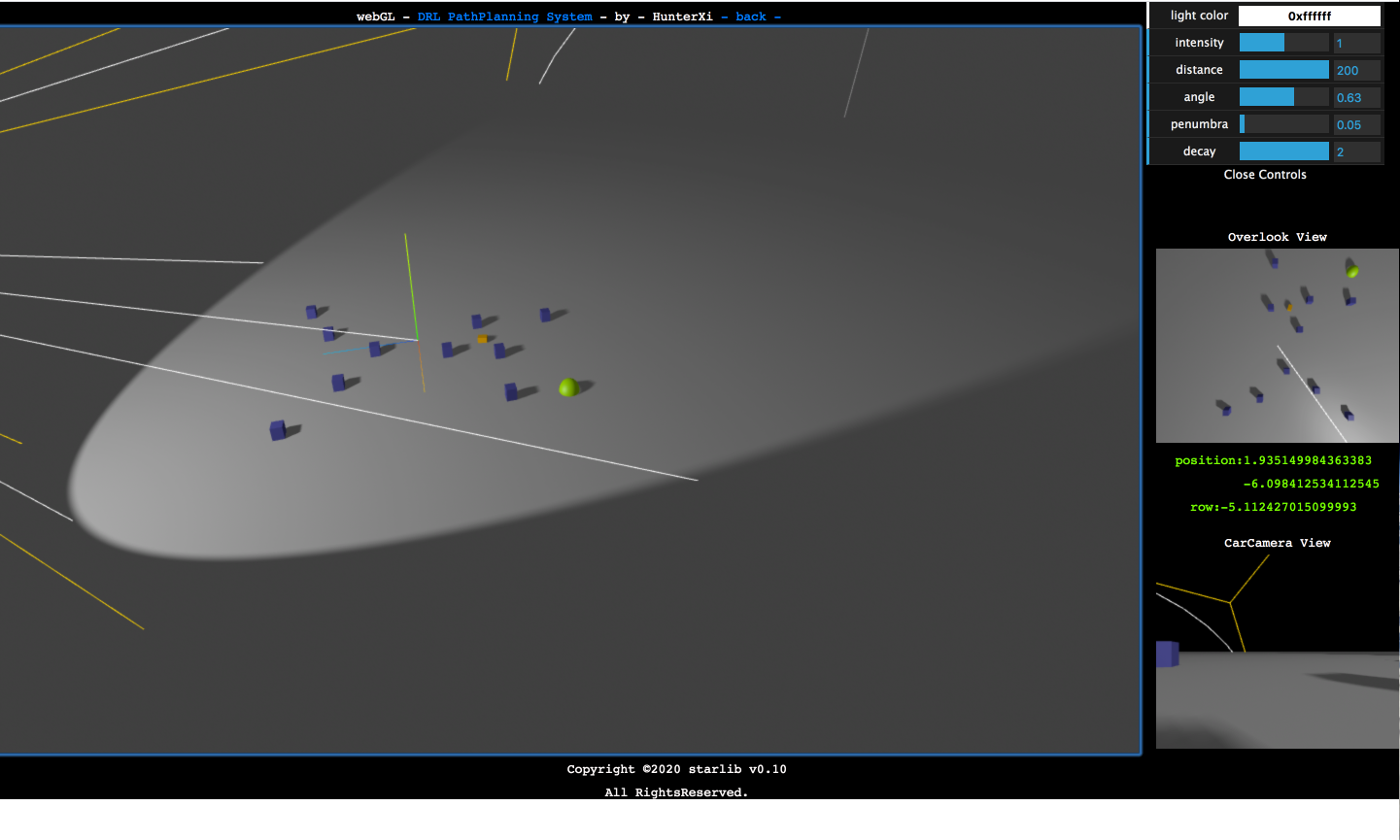

















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









