







 本文探讨了一篇2018年的论文,该论文将深度强化学习(DRL)应用于机器人避障,特别是使用NAF算法。在物理人机交互的背景下,文章介绍了如何定义状态空间、动作空间和奖励函数来实现动态避障。尽管论文缺乏创新,但其奖励函数的设计是关键点,包括末端执行器与目标、动作幅度和障碍物距离的考虑。实验在四种不同场景中验证了算法,展示了DRL在解决复杂避障问题上的潜力。
本文探讨了一篇2018年的论文,该论文将深度强化学习(DRL)应用于机器人避障,特别是使用NAF算法。在物理人机交互的背景下,文章介绍了如何定义状态空间、动作空间和奖励函数来实现动态避障。尽管论文缺乏创新,但其奖励函数的设计是关键点,包括末端执行器与目标、动作幅度和障碍物距离的考虑。实验在四种不同场景中验证了算法,展示了DRL在解决复杂避障问题上的潜力。
基于深度强化学习的机械臂避障
1. 引言
本文介绍一篇2018年发表在 European Control Conference 的文章,虽然不是顶会(看完文章后发现,确实没啥创新的地方),但是和自己的研究方向比较相关,目前被引量为28。

论文传送门:
Deep Reinforcement Learning for Collision Avoidance
of Robotic Manipulators
论文的主要工作就是首次将NAF用在机器人避障中。(我感觉这不算什么亮点…,虽然作者在文章中还强调了“首次”)
2. 论文解读
2.1 背景
在物理人机交互中,避障问题是最重要的问题,而典型的实时避障方法由三部分组成:环境感知、避障算法、机器人控制。本文使用深度强化学习(Deep Reinforcement Learning)的方法在虚拟环境中解决动态障碍物(不可预测其运动轨迹)躲避问题,以此来免去机器人建模的麻烦。
具体而言,本文就是采用NAF实现机器人的动态避障。(关于NAF的介绍,可以参考:【强化学习论文解读 1】 NAF)
2.2 将NAF算法用在机器人避障中
文中介绍了NAF算法的基本原理,这里略去。主要看对于机器人如何定义状态空间。动作空间、还有奖励函数。
状态空间的物理量有:关节位置 q q q,关节速度 q ˙ \dot{q} q˙,目标位置 p t p_{\mathrm{t}} pt,末端执行器位置 p e p_{\mathrm{e}} pe,障碍物位置 p 0 p_{0} p0 ,障碍物速度 p ˙ 0 \dot{p}_{0} p˙0 。文中还解释道:关节速度可以通过关节位置的微分得到,或者基于滑膜的微分器得到;末端执行器的位置通过世界相机得到;障碍物的速度和关节速度采用相同方式得到。(不过vrep好像可以直接拿到物体的运动速度和位置)
动作空间的物理量有:每个关节的旋转速度 q ˙ t a r \dot{q}_{tar} q˙tar
奖励函数由三部分组成:末端执行器和目标点的距离、动作的幅度、障碍物与机器人的距离,即:
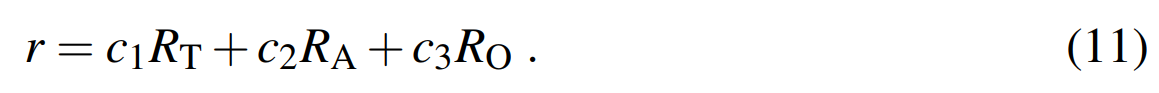
其中 c 1 , c 2 , c 3 c_1,c_2,c_3 c1,c2,c3是根据对预期结果的侧重点来调节的。
其中 R T R_T RT代表末端执行器和目标点的距离,由Huber-Loss函数计算,并不直接采用欧氏距离,即:
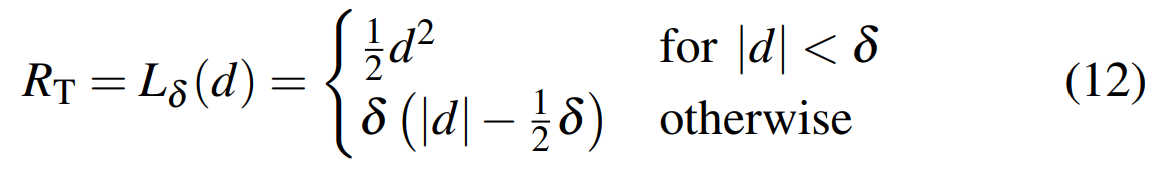
其中
d
d
d是末端执行器和目标点的欧式距离,
δ
\delta
δ是决定Huber-Loss函数平滑性的一个参数(超参,自己调)。
动作幅度
R
A
R_A
RA是强化学习输出的动作向量的范数平方的相反数,作者希望关节速度越小越好,即:

R O R_O RO是障碍物与机器人的距离,由下式计算:

其中 d r e f d_{ref} dref式一个常数,保证 R O R_O RO介于0到1之间, d O d_O dO是由vrep软件计算的障碍物与机器人的最小距离,指数 p p p是为了负奖励的指数衰减。
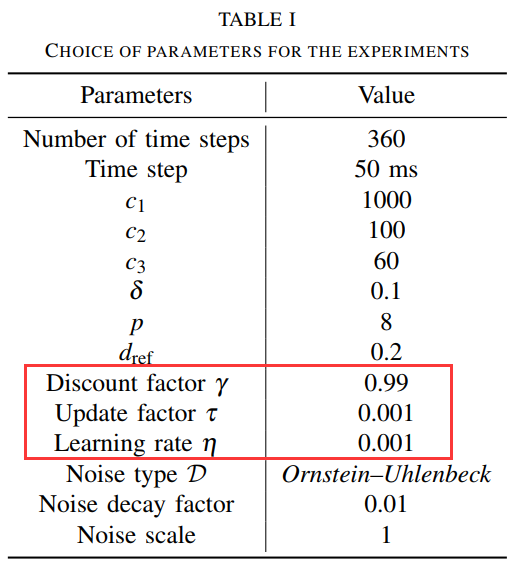
文中的参数设置为下表所示,其中红框上部分为与奖励函数相关的参数,红框内是与NAF相关的参数,红框下部分是与训练过程中的策略探索有关的参数:
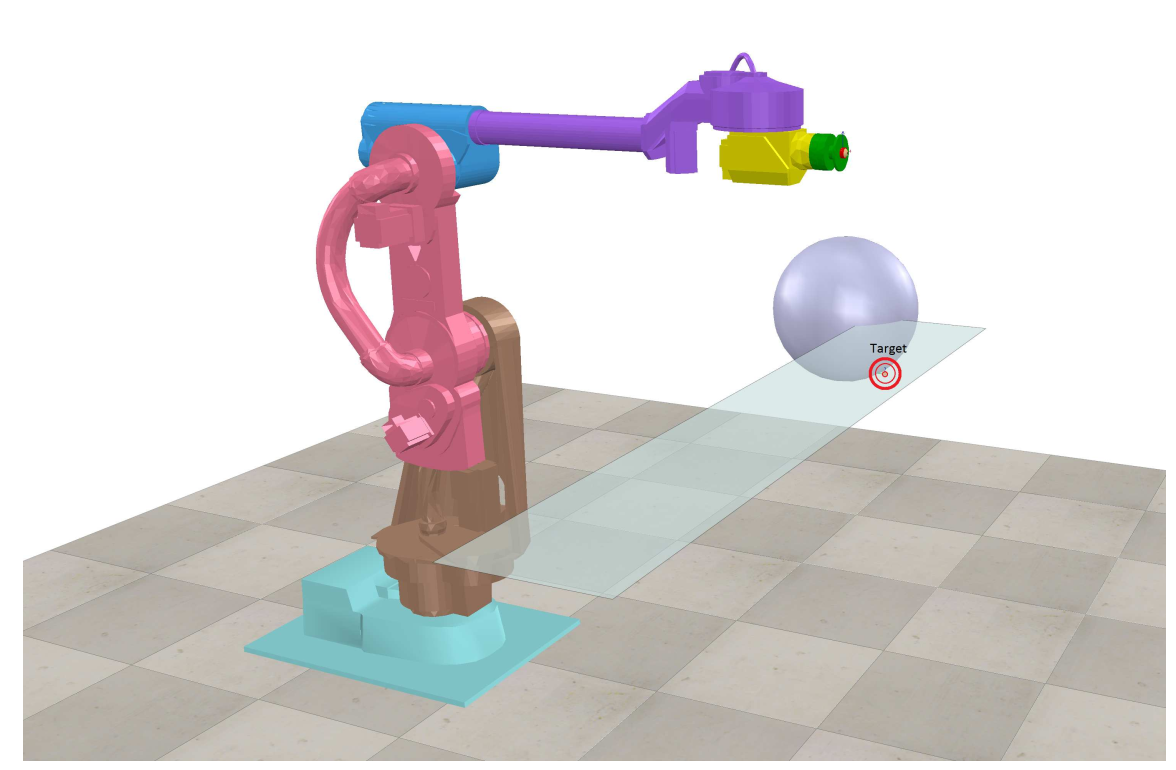
算法在四个场景中进行了验证,但是使用的是同一套参数,就是上表的参数。这四个场景是:
-
固定目标,移动障碍。每一episode目标点的位置相同,障碍以恒定速度从直线路径的一端移动到另一端
-
固定目标,随机移动障碍。每一episode目标点位置相同,障碍沿路径随机移动;球体可以在任何时候改变方向或在一段时间内停止;
-
随机目标、移动障碍。在每一episode开始时随机初始化目标点的位置,障碍物以确定性的方式来回移动。
-
随机目标,随机移动障碍。在每一episode开始时随机初始化目标点的位置,障碍物沿路径随机移动。
这四个场景的训练曲线以及训练后的动画可以见B站链接: 深度强化学习训练机械臂实时避障,VREP仿真
之所以设置这四个场景还有一个原因是作者想要用课程学习的思想,逐步地增加障碍物躲避的难度,复用简单任务的经验
3. 总结
个人感觉此文章唯一的创造性应该就是奖励函数的设置,虽然这个奖励函数也不难想到,而且最关键的机器人与障碍物之间的距离是由vrep软件直接拿到的,所以我感觉整篇文章就是告诉我,NAF能用在机器人避障里。(这好像也是个没什么很大作用的结论…)


















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









