







多智能体强化学习:合作关系设定下的多智能体强化学习_UQI-LIUWJ的博客-CSDN博客
非合作关系设定下的多智能体强化学习_UQI-LIUWJ的博客-CSDN博客
都是对A2C的多智能体改进,仅限于离散控制。
我们现在研究连续控制问题:也就是动作空间都是连续集合,动作
是向量。
多智能体深度确定策略梯度
(Multi-Agent Deep Deterministic Policy Gradient,缩写
MADDPG)
是一种很有名的
MARL
方法,它的架构是“中心化训练 +
去中心化决策”。
1 策略网络 和价值网络
设系统里有 m 个智能体。每个智能体对应一个策略网络和一个价值网络![]()
- 策略网络是确定性的:对于确定的输入
,输出的动作
是确定的。
- 价值网络的输入是全局状态
与所有智能体的动作
,输出是一 个实数,表示“基于状态 s 执行动作 a”的好坏程度。
-
第 i 号策略网络
用于控制 第 i 号智能体,
-
价值网络
则用于评价所有动作 a ,给出的分数可以指导第 i 号策略网络做出改进

2 算法推导
训练策略网络和价值网络的算法与单智能体
DPG
非常类似:用确定策略梯度更新策略网络,用 TD
算法更新价值网络。
 https://blog.csdn.net/qq_40206371/article/details/125026217
https://blog.csdn.net/qq_40206371/article/details/125026217
MADDPG 是异策略
(Off-policy),我们可以使用经验回放,重复利用过去的经验。用一个经验回放数组存储收集到的经验,每一条经验都是  这样一个四元组,其中
这样一个四元组,其中

2.1 训练策略网络
训练第
i
号策略网络 的目标是改进
 ,增大第 i
号价值网络的平均打分。
,增大第 i
号价值网络的平均打分。
所以目标函数是:

这里的期望是关于状态S求的。我们可以使用蒙特卡洛近似,从经验回放数组中随机抽取一个状态![]()
它可以看做是随机变量 S 的一个观测值。用所有 m 个策略网络计算动作![]()
那么目标函数的梯度
可以近似成为:

这里 ,于是用链式法则有:

进而我们可以用梯度上升更新参数

这里注意一点:
在更新第
i 号智能体的策略网络的时候,除了用到
全局状态
,还需要用到
所有智能体的策略网络
,以及
第 i 号智能体的价值网络
2.2 训练价值网络
可以用
TD
算法训练第 i 号价值网络,让价值网络更好拟 合价值函数
给定四元组
,用所有m个策略网络计算动作

记,我们计算TD目标
![]()
再计算 TD 误差:
![]()
最后做梯度下降更新参数


3 中心化训练
为了训练第
i
号智能体的策略网络和
价值网络,我们需要用到如下信息:
- 从经验回放数组中取出的
- m个智能体的策略网络
- 第i 号智能体的价值网络

有一个中央控制器,上面部署所有的策略网络和价值网络。
训练过程中,策略网络部署到中央控制器上,所以智能体不能自主做决策,智能体只是执行中央控制器发来的指令。
由于训练使用异策略,可以把收集经验和更新神经网络参数分开做。
3.1 用行为策略收集经验
智能体把其观测
发送给中央控制器。
中央控制器往第 i 号策略网络 输出的动作 中加入随机噪声 ε , 把引入噪声之后的动作
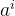
发送给给第
i
号智能体,智能体执行
然后智能体观测到奖励 ,发送给控制器。
,发送给控制器。
控制器把每一轮所有智能体的
,
,
依次存入经验回放组
3.2 中央控制器更新策略网络和价值网络
实际实现的时候,中央控制器上还需要有如下目标网络

设第 i 号智能体当前的参数为:
![]()
中央控制器每次从经验回放数组中随机抽取一个四元组,然后按照下面
的步骤更新所有策略网络和所有价值网络:

和DPG一样,注意一下经验回放的at只有更新价值网络的使用用到过一次


3.3 和MAN-A2C的异同
我们横向看一下这两个模型

不难发现,虽然都是中心化训练+去中心化决策,但是MAN-A2C是策略函数直接内嵌在智能体上;MADDPG是先放在中央控制器上,训练好了再挪下来。
为什么会这样呢?我个人觉得是通信要传输的量不同导致的:
假如MADDPG的策略网络一直在agent上的话:
没有经验回放的话,智能体需要多传一个a到价值网络中去(价值网络中同时需要
才能进行更新)——>传输的参数量比MAN-A2C大,这样会影响运行效率

如果有经验回放的话,中央控制器得添加两次传输:将经验回放的o传给每个agent,每个agent将策略传回中央控制器。这样的话运行时间就更没有保障了
综上,这可能是MADDPG在训练的时候将策略网络放在中央控制器的原因
3.4 改进方法
和改进TD3 一样:

还可以在策略网络和价值网络中使用RNN,记忆历史观测
强化学习笔记:不完全观测问题_UQI-LIUWJ的博客-CSDN博客
4 去中心化决策


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











