







0 前言
多智能体系统中有 m 个智能体,每个智能 体有自己的观测( )和动作
)和动作 。
。
我们考虑
非合作关系
的multi-agent RL。如果做中心化训练,需要用到 m 个状态价值网络
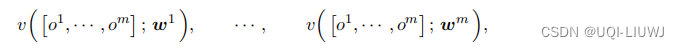
或 m 个动作价值网络
![]()
由于是非合作关系,
m
个价值网络有各自的参数,而且它们的输出各不相同。我们首先
以状态价值网络
v
为例讲解神经网络的结构。
1 不使用自注意力的状态价值网络
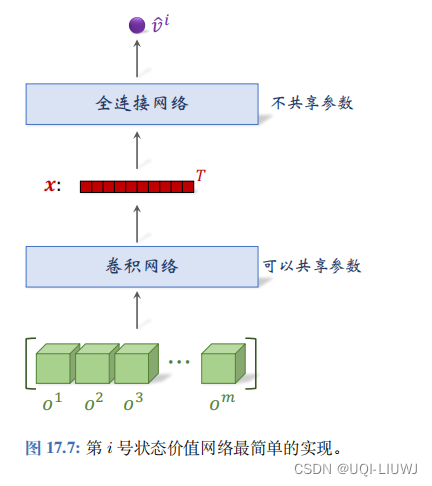
每个价值网络是一个独立的神经网络,有自己的参数。
底层提取特征的卷积网络可以在 m
个价值网络中共享(即复用),而上层的全连接网络不能共享。
神经网络的输入是所有智能体的观测的连接 (Concatenation), 输出是实数
![\hat{v}^i=v([o^1,\cdots,o^m];w^i)](https://latex.csdn.net/eq?%5Chat%7Bv%7D%5Ei%3Dv%28%5Bo%5E1%2C%5Ccdots%2Co%5Em%5D%3Bw%5Ei%29)
1.1 不足之处
-
智能体数量 m 越大,神经网络 的参数越多。
-
神经网络的输入是 m 个观测的连接,它们被映射到特征向量 x 。
-
m 越大,我们就必 须把向量 x 维度设置得越大,否则 x 无法很好地概括
-
x 维度越大,全连接网络的参数就越多,神经网络就越难训练(即需要收集更多的经验才能训练好神经网络)。
-
-
当 m 很大的时候,并非所有智能体的观测
-
第 i 号智能体应当学会判断哪些智能体最相关,并重点关注密切相关的智能体,避免决策受无关的智能体干扰。
-
- 图 17.7 中价值网络的输入是
和
的位置,那么价值网络输出的
会发生变化,这是没有道理的。理想情况下,只要
,那么交换
 的位置就不该改变第 i 号价值网络的输出值
的位置就不该改变第 i 号价值网络的输出值
2 使用自注意力的状态价值网络
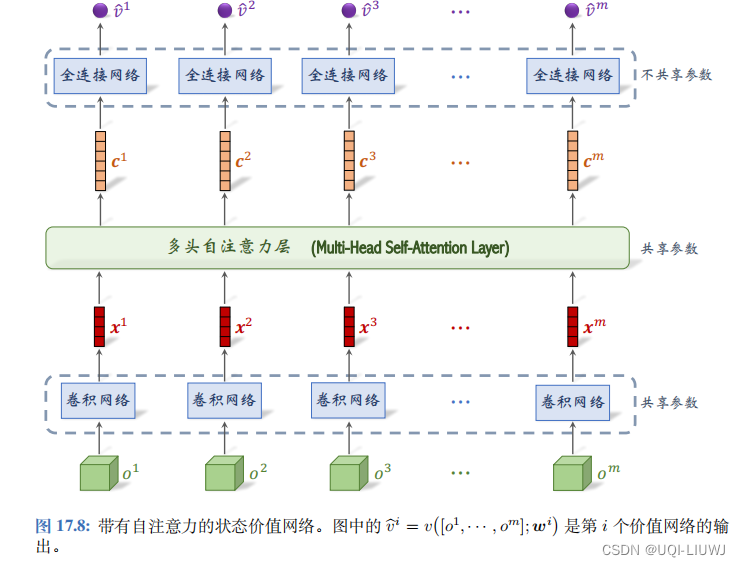
- 输入仍然是所有智能体的观测
-
自注意力层的输入是向量序列
,输出是序列
。向量 ci 依 赖于所有的观测
-
第 i 号全连接网络把向量 c i 作为输入,输出一个实数
3 使用自注意力的动作价值网络
![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











