







1 内部评估方法
- 当一个聚类结果是基于数据聚类自身进行评估的,这一类叫做内部评估方法。
- 如果某个聚类算法聚类的结果是类间相似性低,类内相似性高,那么内部评估方法会给予较高的分数评价。
- 不过内部评价方法的缺点是:
-
这些评估方法对某些算法有倾向性,如k-means聚类都是基于点之间的距离进行优化的,而那些基于距离的内部评估方法就会过度的赞誉这些生成的聚类结果
-
——>这些内部评估方法是基于特定场景判定一个算法要优于另一个
-
-
1.1 SSE 和方差
拟合数据和原始数据对应点的误差的平方和

1.2 Compactness(紧密性)(CP)
每一个类各点到聚类中心的平均距离
CP越低意味着类内聚类距离越近

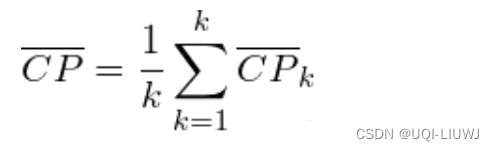
1.3 Separation(间隔性)(SP)
- 各聚类中心两两之间平均距离
- SP越高意味类间聚类距离越远
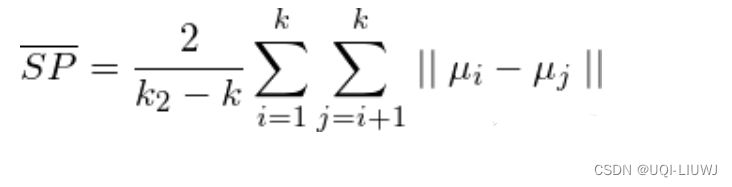
1.4 轮廓系数 Silhouette Coefficient
对于单个样本,设a是与它同类别中其他样本的平均距离,b是与它距离最近不同类别中样本的平均距离,其轮廓系数为:
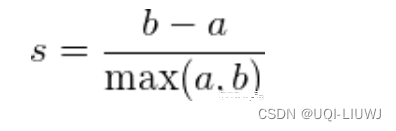
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。
轮廓系数的取值范围是[-1,1],同类别样本距离越相近不同类别样本距离越远,分数越高
1.5 Davies-Bouldin Index(戴维森堡丁指数)
- 任意两类别的类内距离平均距离(CP)之和除以两聚类中心距离求最大值。
- DB越小意味着类内距离越小同时类间距离越大
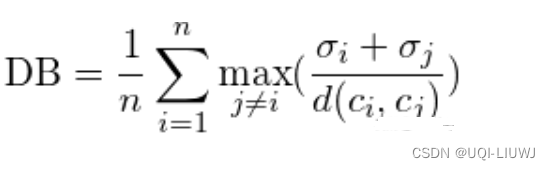
1.6 Dunn Validity Index (邓恩指数)(DVI)
- 任意两个簇元素的最短距离(类间)除以任意簇中的最大距离(类内)。
- DVI越大意味着类间距离越大同时类内距离越小。
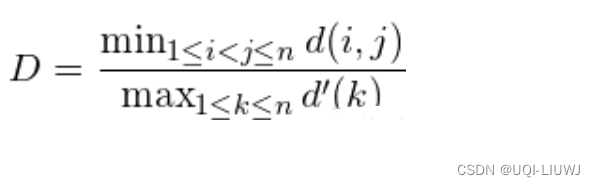
2 外部评估指标
- 在外部评估方法中,聚类结果是通过使用没被用来做训练集的数据进行评估。
- 这些数据已经预先分类好,被用作ground truth
2.1 纯度(Purity
- 每个簇中最多的类作为这个簇所代表的类
- 计算正确分配的类的数量,然后除以N















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











