







1 几种方式
1.1 微调 finetune
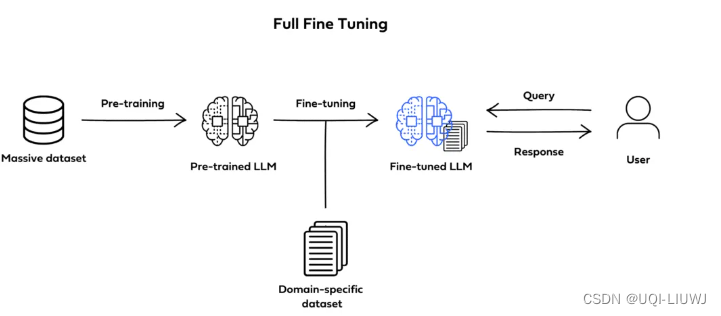
1.1.1 全面微调
- 在全面微调中,所有模型参数都会更新
1.1.2 参数高效微调(PEFT)
- 仅更新一小部分参数来进一步调整预训练模型
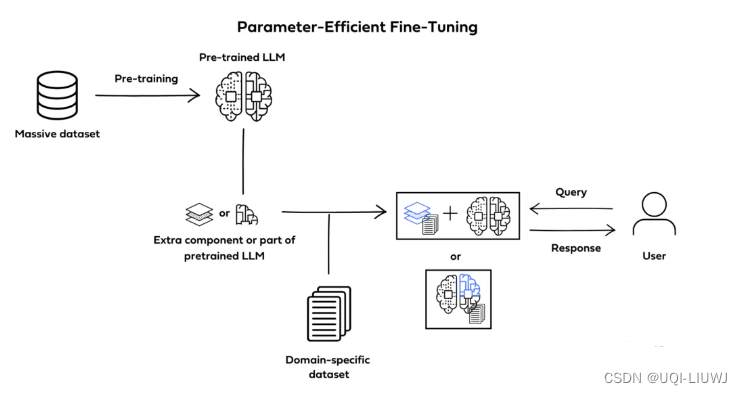
- 相比于全面微调,PEFT
- 更高效、更快的训练
- 保留预训练中的知识
1.2 prompt engineering
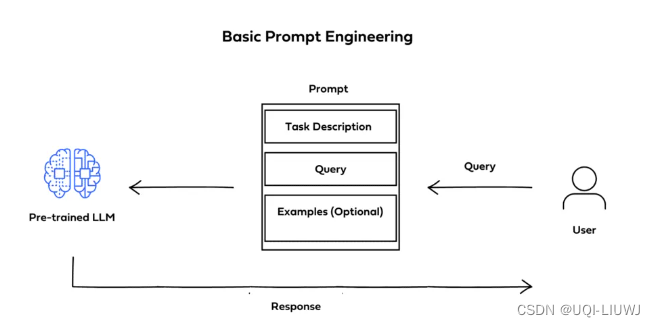
- 又分为
-
Zero-shot Prompting
-
Few-shot prompting
-
在用户的查询前添加一些示例,这些示例本质上是样本输入和预期模型输出对
-
-
1.3 rag
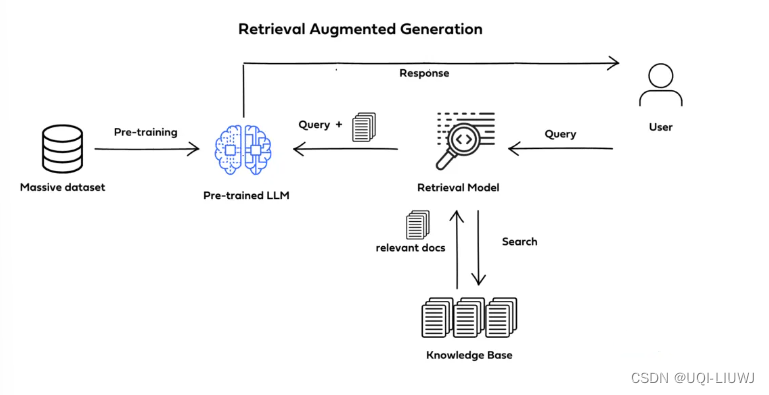
2 对比
| Prompt Engineering | RAG | 微调 | 从零训练大模型 | |
介绍 | 通过提供少量示例提供尽可能多的上下文,使基础模型更好地了解用例 | 增加了直接来自向量化信息存储的特定于用例的上下文 | 在特定领域的数据上更新模型权重 | 模型是在用例特定数据上从零开始训练的 |
准确性 | 与其他方法相比,它产生的结果最不准确 | 与Prompt Engineering相比,它产生的结果大大改善,而且产生幻觉的可能性非常低 | 也提供了相当精确的结果,输出的质量与RAG相当 | 产生幻觉的几率几乎为零,输出的准确率也是比较中最高的 |
实现的复杂性 | 相当低的实现复杂性 | 比Prompt Engineering具有更高的复杂性 | 更复杂 | 最高的实现复杂性 |
工作量投入 | 需要大量的迭代努力才能做到正确 基础模型对提示的措辞非常敏感,改变一个词甚至一个动词有时会产生完全不同的反应 | 由于涉及到创建嵌入和设置矢量存储的任务,RAG也需要很多的工作量,比Prompt Engineering要高一些 | 微调则比前两个要更加费力。 虽然微调可以用很少的数据完成(在某些情况下甚至大约或少于30个示例),但是设置微调并获得正确的可调参数值需要时间 | 从头开始训练是所有方法中最费力的方法。 它需要大量的迭代开发来获得具有正确技术和业务结果的最佳模型。 这个过程从收集和管理数据开始,设计模型体系结构,并使用不同的建模方法进行实验,以获得特定用例的最佳模型。 这个过程可能会很长(几周到几个月) |
灵活性 | 非常高的灵活性,因为只需要根据基础模型和用例的变化更改提示模板 | 很最高程度的灵活性 可以独立地更改嵌入模型、向量存储和LLM,而对其他组件的影响最小 | 灵活性非常低 因为数据和输入的任何更改都需要另一个微调周期,这可能非常复杂且耗时 | 灵活性最低的 |
知识维度 |
|
| ||
稳定性、可解释性 |
|
| ||
成本 |
|
| ||
|
| |||
| ||||
| 但知识内容多的情况下,检索成本会变高 | ||||
任务特定 vs 通用性 | 微调通常是为特定任务进行优化,而RAG是通用的,可以用于多种任务 | 微调对于特定任务的完成效果好,但在通用性问题上不够灵活 | ||
即时性 vs 训练 | RAG 模型可以实现即时的知识更新,无需重新训练,在及时性要求高的应用中占优势 | 微调通常需要重新训练模型,时间成本较高 | ||
隐私性 | 隐私性的挑战来源于 |
- 总结:
- 准确性(低——>高):Prompt Engineering<RAG ≈微调<从零训练大模型
- 实现复杂性(低——>高):Prompt Engineering<RAG <微调<从零训练大模型
- 工作量投入(少——>多):Prompt Engineering<RAG <微调<从零训练大模型
- 灵活性(少——>多):从零训练大模型<微调<Prompt Engineering<RAG
适用场景
| RAG | 微调 |
|
|
3 对比结果可视化
3.1 成本

3.2 实施复杂性
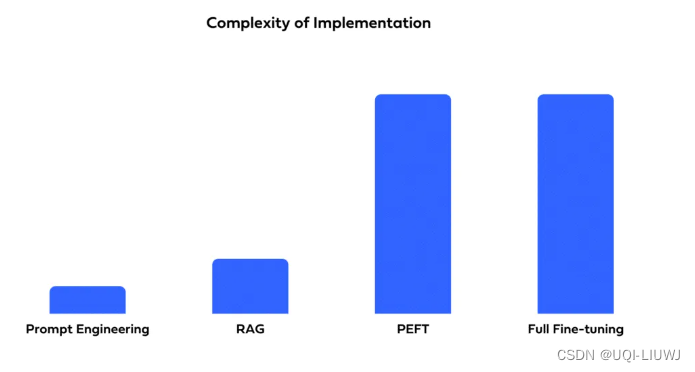
3.3 特定领域术语
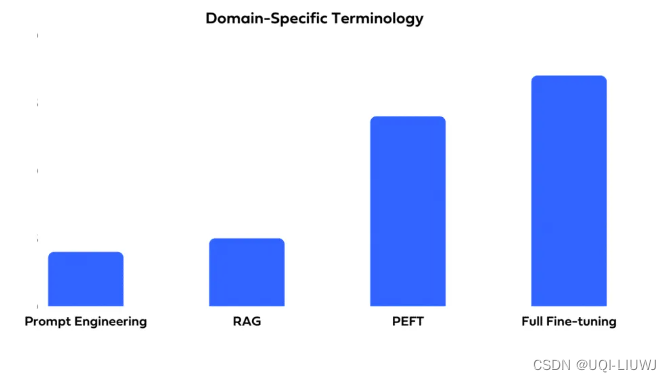
3.4 最新知识
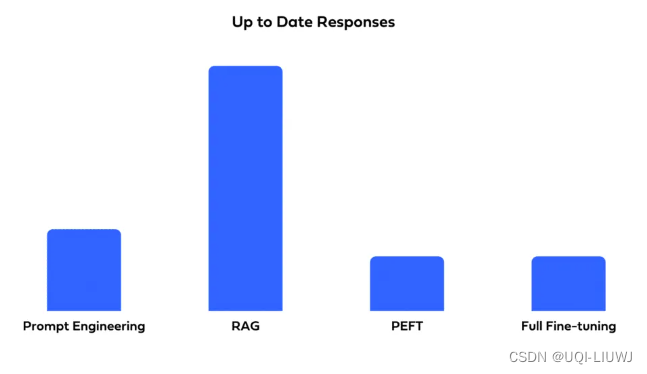
3.5 透明度和可解释性
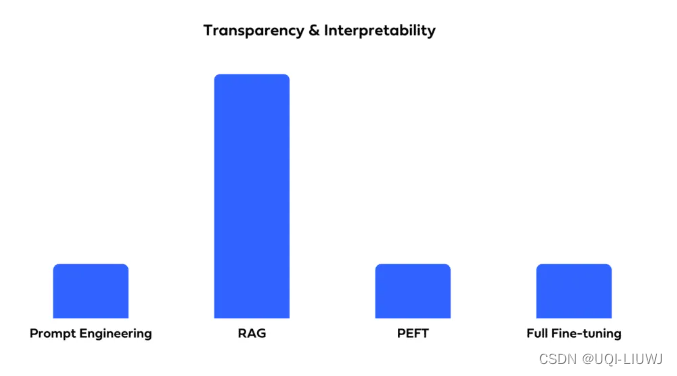
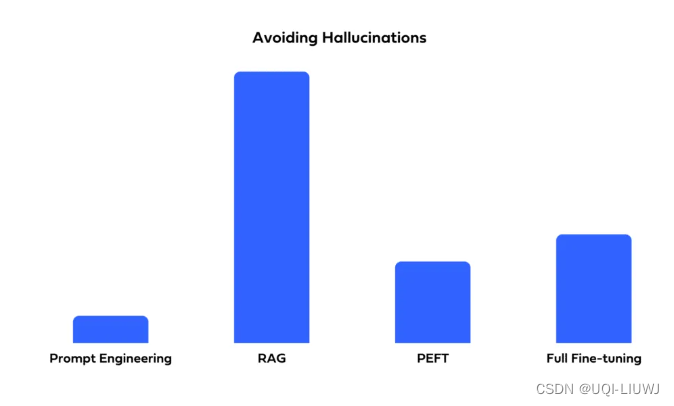
3.6 幻觉















 6651
6651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











