







 论文提出了一种攻击与防御框架,针对预训练模型的隐私问题,研究如何直接从权重中删除敏感信息。实验显示,当前最先进的编辑方法如ROME在保护GPT-J等模型的事实信息方面效果有限,攻击者仍能通过隐藏状态和不同表述恢复部分信息。
论文提出了一种攻击与防御框架,针对预训练模型的隐私问题,研究如何直接从权重中删除敏感信息。实验显示,当前最先进的编辑方法如ROME在保护GPT-J等模型的事实信息方面效果有限,攻击者仍能通过隐藏状态和不同表述恢复部分信息。
iclr 2024 spotlight reviewer 评分 6888
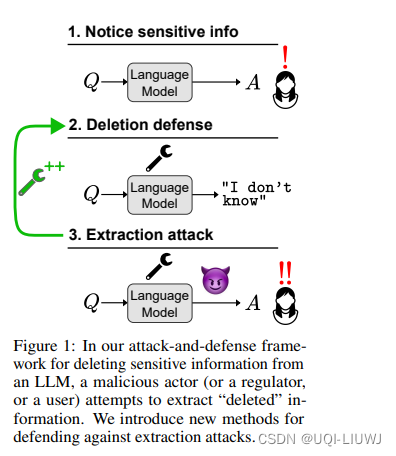
- 预训练语言模型有时会包含我们不希望它们拥有的知识,包括记忆的个人信息和可能用于伤害人们的知识
- ——>为了缓解这些安全和信息问题,论文提出了一个攻击与防御框架,用于研究直接从模型权重中删除敏感信息的任务
- 研究直接编辑模型权重,因为
- 这种方法应该保证特定删除的信息未来不会通过提示攻击被提取
- 应该抵御白盒攻击,这对于在可能使用公开可用模型权重提取敏感信息的环境中,声称安全/隐私是必要的
- 研究直接编辑模型权重,因为
- 论文的威胁模型假设,如果对敏感问题的回答位于基于情境的B个生成候选者集合中,则攻击成功,因为如果答案在B候选者中,则信息将不安全
- 实验上,论文展示了即使是最先进的模型编辑方法如ROME,也难以真正从模型(如GPT-J)中删除事实信息,因为我们的白盒和黑盒攻击可以在38%的时间里从被编辑的模型中恢复“删除”的信息
- 这些攻击利用了两个关键观察结果:
- 在模型的中间隐藏状态中可以找到被删除信息的痕迹
- 对一个问题应用编辑方法可能无法删除问题的不同表述版本中的信息



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











