







防止遗忘和后续翻找的麻烦,记录下平时学到和用到的GPU知识,较为琐碎,不考虑连贯性和严谨性,如有欠妥的地方,欢迎指正。
GPU 学习笔记一:从A100与910B分析中,学习GPU参数的意义。
GPU 学习笔记二:GPU单机多卡组网和拓扑结构分析(基于A100的单机多卡拓扑结构分析)
GPU 学习笔记三:GPU多机多卡组网和拓扑结构分析(基于数据中心分析)
GPU 学习笔记四:GPU多卡通信(基于nccl和hccl)
GPU 学习笔记五:大模型分布式训练实例(基于PyTorch和Deepspeed)
GPU 学习笔记六:NVIDIA GPU架构分析(基于技术演进时间线,持续更新)
GPU 学习笔记七:华为 NPU架构分析(基于技术演进时间线,持续更新)
GPU 学习笔记八:GPU参数对比统计表(记录GPU参数,持续更新)
本文简单介绍A100和910B的结构,对比分析一些重要参数的意义,以案例分析的形式,快速入门了解GPU/NPU。
一、处理器运算单元分析
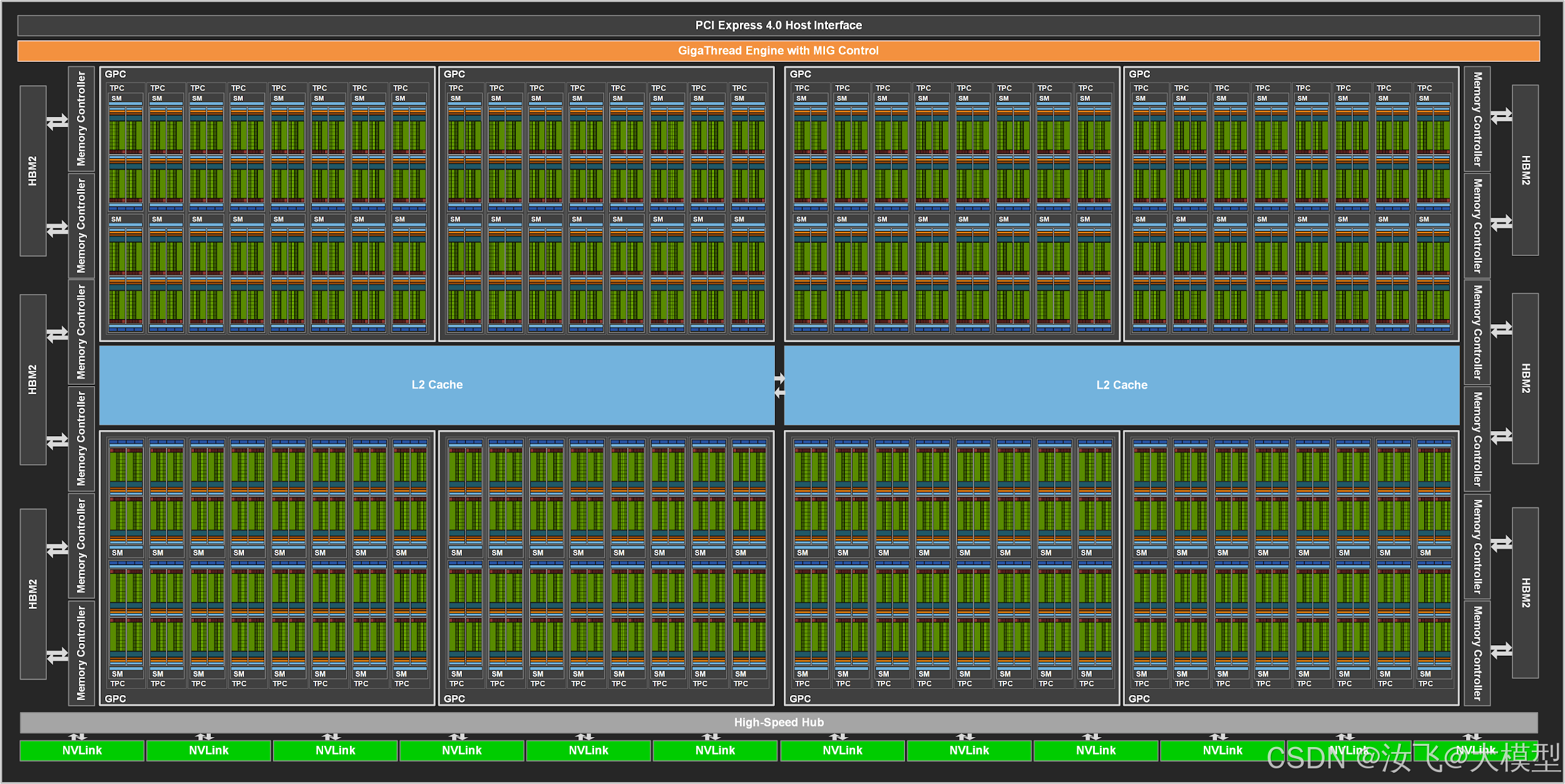
A100采用Nvidia自研的Ampere架构,每个A100卡封装了128个SM,每个SM中配置了64个cuda core和4个第三代tensor core。
注:
Ampere在2020年首次发布,是一款顶尖的AI计算架构,是继volta和turing架构之后的Nvidia新一代技术,他采用了第三代的tensor core,第二代的RT Core,增加了cuda核心数,提高了带宽,并对能效进行了优化。
A100即为采用了该架构的GPU,每个GPU包含8个GPC(GPU处理集群),每个GPC包含8个TPC(文理处理集群),每个TPC包含2个SM,共计8*8*2=128个SM。SM为Stream multiprocessing流式多处理器,是GPU的核心运算单元。
A100除此之外,还采用了6个HBM2堆栈(40GB)或者HBM2e(80GB)的高性能带宽内存。
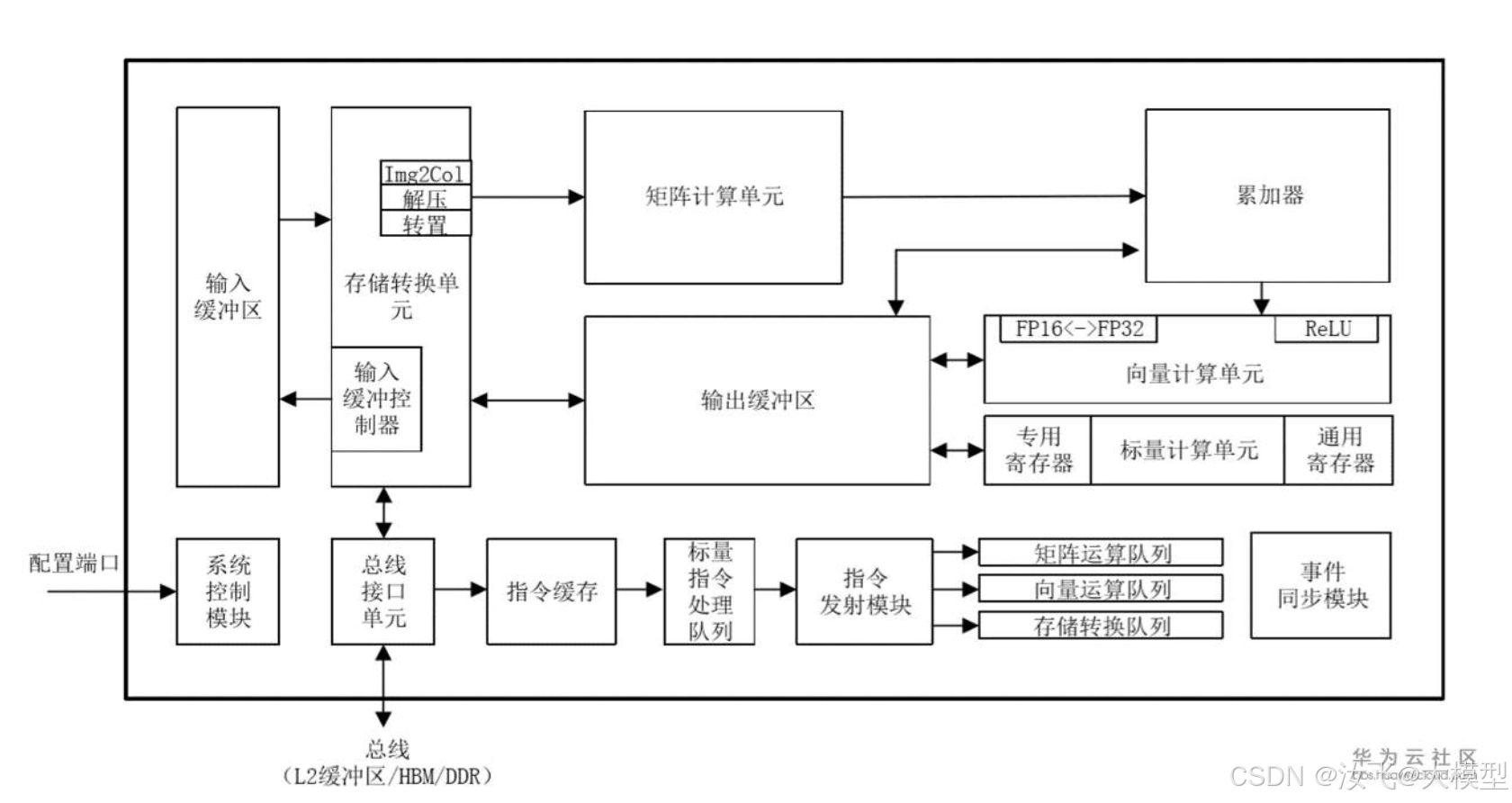
910B采用华为自研的达芬奇AI架构,每个card内置了25个达芬奇AI Core,每个AI Core包含2个AI vector向量计算单元和1个AI cube矩阵计算单元。
注:
达芬奇(Davince)是华为自研的顶尖的AI计算架构,不同于传统的支持通用计算的CPU和GPU,本质上是为了适应某个特定领域中的常见的应用和算法,通常称之为“特定域架构(Domain Specific Architecture,DSA)”芯片。
参见:昇腾开发者社区介绍
二、算力分析:
在A100中,包含了128*64=8192个cuda core和128*4=512个tensor core。
在每个时钟周期,每个cuda core执行1次FP32的FMA运算,总共执行64*1*128=8192次运算;每个tensor core执行1次4*8*8的矩阵运算,即4*8*8=256次FP16/FP32的FMA运算,总共执行4*8*8*4*128=131072次运算。
在910B中,包含了25*2=50个vector core和25*1=25个cube core。
在每个时钟周期,每个vector core执行128次的FP16运算,总共执行25*2*128=6400次运算;每个cube core执行1次16x16x16的矩阵运算,即16x16x16=4096次的FP16/FP32的FMA运算,总共执行4096*25=102400次运算。
Davince架构中的vector core媲美Ampere中的cuda core,cube core媲美tensor core,都为高性能计算提供了强大的支撑。相对于GPU的通用性,NPU更专注于矩阵运算,它们在不同的使用场景中各有优缺点。
普通模式下,单个时钟周期下,A100完成8192+1311072次运算,910B完成6400+102400次运算,910B与A100算力旗鼓相当。但华为910B在单个时钟周期内可处理16x16x16的矩阵计算,远胜于A100的4x8x8,其单次矩阵计算能力高达A100的16倍,效能显著。
A100凭借稀疏矩阵计算支持以及RT/tensor/cuda等丰富的核心单元,在多数场景中显著超越910B。尽管910B在单一矩阵计算上表现出色,但A100在处理多元计算任务时优势更加明显,尤其在稀疏矩阵计算领域,A100的性能尤为突出。
三、内存架构分析
两者都采用了HBM的堆叠技术,将GPU芯片与内存Die封装在一起,与GPU进行高速通信,A100的HBM通信带宽达到1935GB/s。A100的HBM内存大小分为40GB(HBM2)和80GB(HBM2e)两种。910B的HBM内存大小为64GB(HBM2e)。
HBM堆叠技术,将多个GDDR5堆叠集成到封装里和GPU一起。从而提升通信性能,节省了95%表面积。
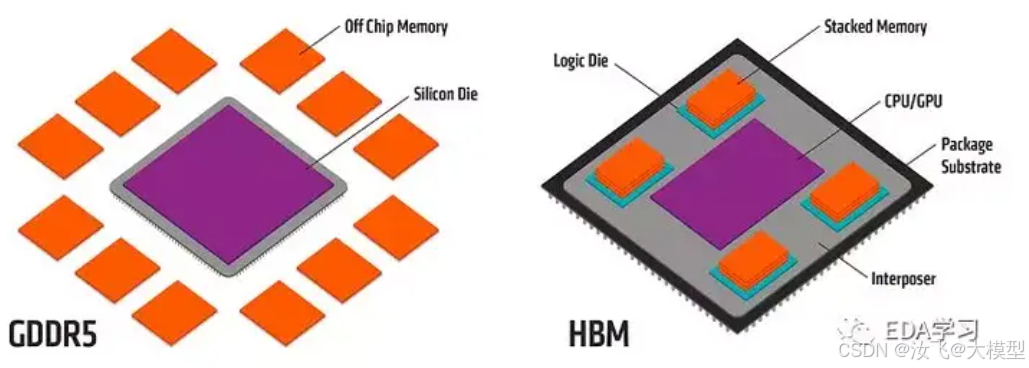
由于910B与A100在内存结构上大相径庭,910B因其在达芬奇AI Core的的解耦设计,实现了AI Vector Core和AI Cube Core的完全解耦,两个计算单元的存储体系也是独立的。此外,在L1缓存上,A100统一为192KB的逻辑区,910B则为独立于Cube单元的存储区域,大小为1MB。在L2缓存上,A100配置了40MB,而910B则配置到192MB。在L1和L2缓存上,910B都显著超越A100。
四、 通信性能分析
NVIDIA通信技术采用了NVLink,NVSwitch,基于RDMA协议的InfiniBand通信技术和RoCE技术,offload cpu技术,PXN单轨通信技术等,大大提升了GPU与GPU以及节点间的通信效率。
在经典的8卡组网拓扑中,每张卡有6个NVLink连接槽,使用NVLink连接线分别与6个NVSwitch交换芯片互联,组成full-mesh拓扑结构。A100采用的是NVLink3第三代技术,每个NVLink连接线包含2个lane,每个lane的双向通信带宽是50GB/s,所以one-to-one的带宽是2lane/NVLink * 50GB/s/lane * 6NVLink = 600GB/s。one-to-many互联的带宽也是600GB/s。
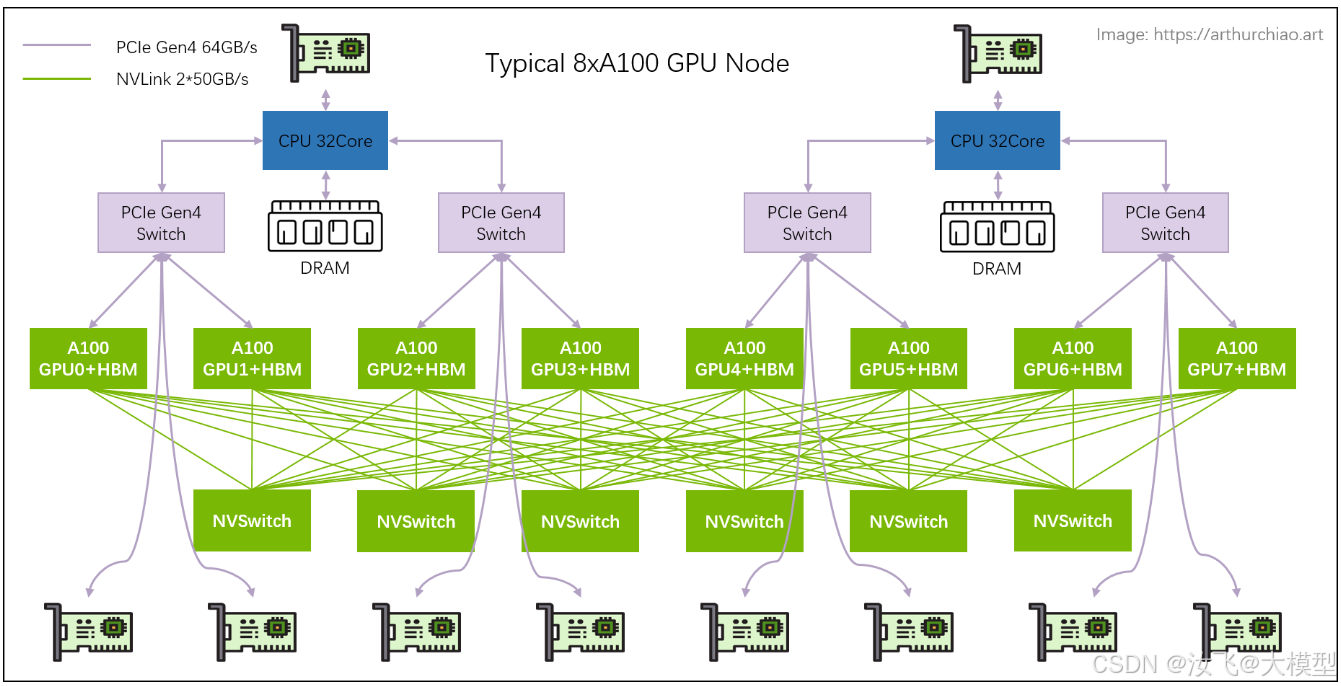
910B则采用了HCCS通信技术,通过PCIe进行互联,通信性能取决于PCIe的带宽,PCIe gen4.0的带宽是64GB/s,,PCIe gen5.0的带宽是128GB/s。
在典型的8卡组网拓扑中,每张卡有7个PCIe连接槽,使用PCIe gen5.0连接线分别与另外7张卡通过互联。one-to-one的带宽是56GB/s,互联one-to-many的带宽就是56GB/s*7=392GB/s。
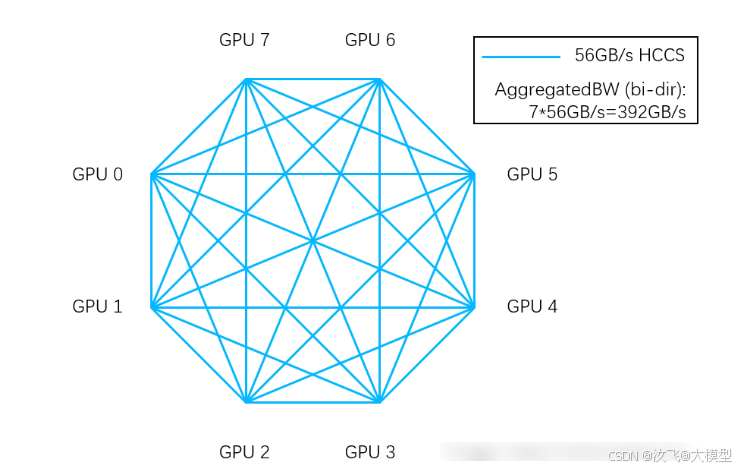
华为910B在CPU-GPU通信中凭借PCIe Gen5占据优势,但整体性能仍显著落后于A100。然而,华为据传已研发出类似“NVSwitch”的首代硬件,显著提升通信性能,前景可期。
五、总结
A100芯片,承袭英伟达技术精髓,不仅深度学习AI性能出众,更在图像处理及通用计算领域展现卓越性能,全面领先行业。
910B芯片,专为神经网络芯片NPU设计,具备超大矩阵与高带宽内存系统,矩阵运算与流水并行处理能力卓越。在深度学习场景中,尤其在GEMM计算上,其性能表现尤为突出。
由于行业技术封锁,国内芯片在制程工艺上尚有欠缺,910B采用7nm技术,落后于4nm技术,910B功耗400W,落后于A100的300W,这就使得国内芯片集成度和能效低于国外,还有较大提升空间。
其次,在生态上,国外龙头企业长期占据优势,国内芯片需要加大生态建设,通过开源吸引更过的伙伴加入,共同推进国内芯片技术的创新和应用,筑建健康繁荣的生态环境。


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









