








💪 专业从事且热爱图像处理,图像处理专栏更新如下👇:
📝《图像去噪》
📝《超分辨率重建》
📝《语义分割》
📝《风格迁移》
📝《目标检测》
📝《图像增强》
📝《模型优化》
📝《模型实战部署》
📝《图像配准融合》
📝《数据集》
📝《高效助手》
📝《C++》
📝《Qt》


图像噪声一直是我在图像处理过程中的一个痛点,虽然目前去噪算法很多,但是既能兼顾细节又能去噪,且参数量还得小的模型不多。最近研究了SwinIR网络,效果确实牛。我使用自己策略训练去噪模型,训练5天后进行测试,相比官网提供模型竟然涨点3.48🤪。我自己训练好的模型权重文件会在博文中提供下载链接,学者可以验证。下面总结SwinIR网络的训练及推理测试过程。
一、SwinIR网络
SwinIR (基于Swin Transformer的图像修复网络) 是2021年提出的一种深度学习模型,专为图像修复任务设计,适用于超分辨率、去噪和压缩伪影去除等任务。SwinIR 依赖于Swin Transformer,这是一个采用分层架构并结合了滑动窗口的transformer模型,使得网络能够在图像中捕获局部和全局信息。SwinIR的分层结构和滑动窗口机制相比全局注意力机制模型降低了计算成本。
SwinIR的关键组成部分:
Swin Transformer骨干网络:SwinIR使用Swin Transformer作为骨干网络。Swin Transformer通过分层结构和滑动窗口机制在不同图像尺度上提取细节,提高了模型在处理高分辨率图像时的性能,同时控制了计算成本。
滑动窗口机制:SwinIR中的滑动窗口技术将图像分割成重叠的小窗口,并在连续层中移动窗口位置,从而更好地捕获上下文信息。这一特性确保了局部和全局特征的有效提取,这是高质量图像修复的关键。
图像修复模块:SwinIR包含多个残差Swin Transformer模块,每个模块由一个Swin Transformer层和残差连接组成。这种设计提高了模型恢复细节的能力,并减少了传统卷积神经网络(CNN)中的过度平滑问题。
参数量对比见下:

网结构见下,关于网络结构设计细则,学者详看原论文:

二、源码包获取
SwinIR官网提供的源码链接为:code
论文地址:paper
配套教程的源码包获取方式已在文章结尾提供,扫码到「视觉研坊」中回复关键字:图像去噪SwinIR,会自动回复下载链接。我提供的源码包中在原作者基础上做了一些代码改动,同时提供了部分训练集和测试集,官网的模型权重也提供了部分,想要测试更多官网模型的学者去官网上下载,下载官网模型权重地址:官网模型权重,见下:

我自己训练的高斯噪声标准差为7模型下载链接后续会更新。
下载源码包解压后的样子见下:

三、环境准备
下面是我自己训练和测试的环境,仅供参考,其它环境也行:

四、数据准备
4.1 训练集
下面是各个训练集,对应有下载链接:
DIV2K数据集,共800张图像,大小7.1G,下载链接:DIV2K
Flicker2K数据集,共2650张图像,大小20.1G,下载链接:Flickr2k
OST数据集,共10324张,较多可选,下载链接:OST
FFHQ数据集,前2000张图像,人脸)+Manga 109(漫画),下载链接:FFHQ
SCUT-CTW 1500数据集,共1000张图像,大小743M,下载链接:SCUT-CTW 1500
4.2 测试集
Set5 + Set14 + BSD100 + Urban100 + Manga109测试集的下载链接为:测试集
打开链接后有各个测试集,下载需要使用的,见下:

RealSRSet+5images测试集下载链接为:RealSRSet+5images
BSD68+CBSD68+Kodak24+McMaster+RNI15+RNI6+Set12测试集下载链接:测试集
五、训练
SwinIR网络去噪方面可以处理彩色图像和灰度图像,本教程以去除灰度图像为例,它们的训练方法都是一样的,只是配置文件中n_channels参修改即可,n_channels赋值为3时表示处理彩色图像;n_channels赋值为1时表示处理灰度图像。见下:

5.1 配置参数修改
在我提供的源码包中,我重新新建了一个train_swinir_denoising_gray_CN.json配置文件,每一个参数我都详细写明了中文注释。建议学者在我提供配置文件基础上调参。下面是在训练前需要结合自己数据集和电脑配置调整的参数:


5.2 单卡训练
SwinIR网络模型较大,单卡训练显存至少12G,dataloader_batch_size参数设置为1,显存低于12G,训练过程会报显存不够。
单卡训练在终端输入下面命令:
python main_train_psnr.py --opt options/swinir/train_swinir_denoising_gray_CN.json
如果有多张显卡,想指定在某一张卡上训练,使用下面训练命令,举例在第二张卡上训练,见下图:
CUDA_VISIBLE_DEVICES=1 python main_train_psnr.py --opt options/swinir/train_swinir_denoising_gray_CN.json

5.3 多卡训练
5.3.1 配置参数修改
我只有两张卡,这里举例在两张卡上训练,先修改配置参数,见下:


这里我设置为2是因为的一块GPU显存只有12G,一块显存只有batch_size设置为1时才能训练,所以多卡训练dataloader_batch_size参数我只能设置为2,平均到每一张卡上batch_size就为1。
5.3.2 多卡训练时dataloader_batch_size参数设置问题
在使用多个GPU进行训练时,dataloader_batch_size参数通常指的是每个GPU上的批处理大小。
总批处理大小: 可以选择一个期望的总批处理大小(即在所有GPU上合计的批处理大小)。例如,如果你希望总批处理大小为12,并且使用3张GPU,那么每张GPU上的dataloader_batch_size应设置为:
d a t a l o a d e r B a t c h S i z e = 总批处理大小 G P U 数量 = 12 3 = 4 dataloaderBatchSize=\frac{总批处理大小}{GPU数量}=\frac{12}{3}=4 dataloaderBatchSize=GPU数量总批处理大小=312=4
5.3.3 多卡训练命令
在终端中输入下面命令,启动多卡训练:
python -m torch.distributed.launch --nproc_per_node=2 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_denoising_gray_CN.json --dist True
多卡的只需要修改–nproc_per_node参数,如果你有3张显卡,并且想要使用全部的显卡进行训练,将–nproc_per_node参数设置为3。
启用两张卡训练,见下:

下面是正确训练的输出过程:

5.4 报错
5.4.1 报错内容
在使用原作者源码时,可能会出现下面错误:Traceback (most recent call last):
File “F:/Code/Python/SwinIR/KAIR-master/main_train_psnr.py”, line 249, in
main()
File “F:/Code/Python/SwinIR/KAIR-master/main_train_psnr.py”, line 46, in main
opt = option.parse(parser.parse_args().opt, is_train=True)
File “F:\Code\Python\SwinIR\KAIR-master\utils\utils_option.py”, line 30, in parse
for line in f:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xaf in position 78: illegal multibyte sequence

5.4.2 报错原因
这个错误是由于读取 JSON 配置文件时使用了 GBK 编码,而文件包含了无法被 GBK 解析的字符。解决方案是指定 utf-8 编码来读取文件。
5.4.3 解决办法
修改 utils_option.py 文件中读取配置文件的部分代码。找到报错文件 utils/utils_option.py 的第 30 行附近,确保以 utf-8 编码打开文件,如下所示:

5.5 模型保存
启动5.3训练后,经过漫长的训练过程,见下:

在训练过程中的模型自动保存到根目录下的denoising文件夹中,见下:

训练好的模型,带G的进行推理测试:

六、推理测试
6.1 灰度图像去噪测试
在终端输入下面测试命令,这里给的例子是测试官网提供的高斯噪声标准差为15模型。
python main_test_swinir.py --task gray_dn --noise 15 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/RealSRSet+5images
参数解析:
--task 表示启动要进行的功能,这里的灰度图像去噪,可选的有classical_sr, lightweight_sr, real_sr,gray_dn, color_dn, jpeg_car
--noise 表示高斯噪声标准差
--model_path 表示待测试模型路径
--folder_gt 表示待测试图像路径

测试结果位于根目录下的result文件夹中,见下:
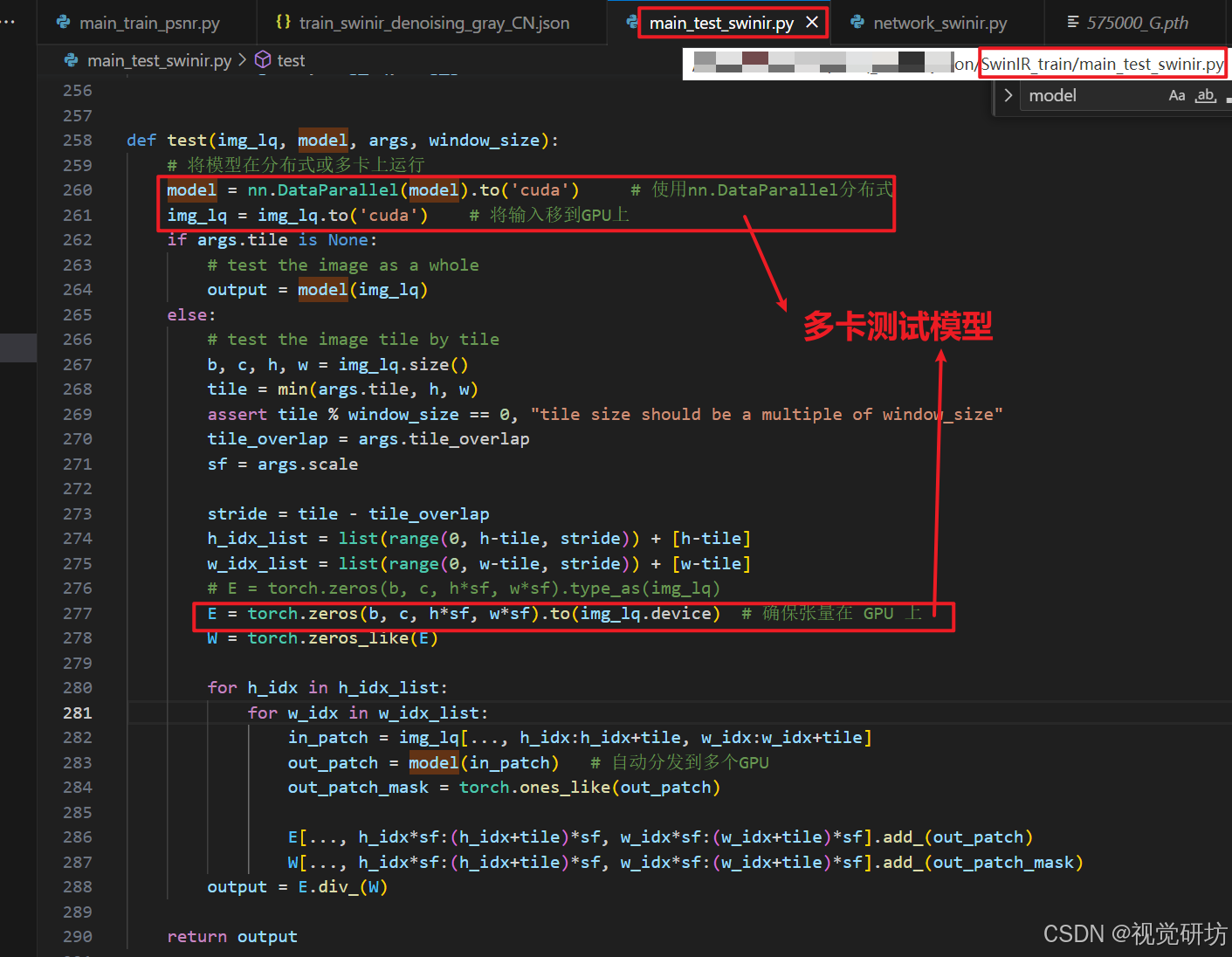
6.1.1 多卡推理测试
上面方法是单卡测试,想要多卡测试模型时,需要修改的代码见下,在main_test_swinir.py脚本中添加代码:
import torch.nn as nn
6.2 彩色图像去噪测试
在终端输入下面测试命令:
python main_test_swinir.py --task color_dn --noise 15 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/McMaster
参数解析同6.1。

6.3 客观指标对比
客观指标的评价主要是PSNR和SSIM,关于这两个指标的讲解见PSNR:峰值信噪比和SSIM:结构相似性
下面主要在两个测试集上验证。
6.3.1 real_faces测试集
下面是用官网提供的模型:004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth,测试输出见下:

下面是用我自己策略训练的模型:705000_G.pth,高斯噪声标准差为7,测试输出见下:

从上面对比可以看出PSNR值涨点3.67,SSIM值涨点0.0287。
6.3.2 Set12测试集
下面的对比结果,上面是官网提供的004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth模型,下面是用我自己模型测试结果。

从上面对比可以看出PSNR值涨点3.48,SSIM值涨点0.0375。
6.4 显存不够问题
当用模型对高分辨率图像去噪时,如果电脑显存较小会提示显存不够的问题,修改下面的tile参数,如下:表示将图像分割成512*512大小喂入模型推理,最后再将分割后的各个小块拼接合并为原来图像大小输出,关于这个操作的详解,见我另外一篇博文:超高分辨图像分块多patch处理后再拼接合并

七、去噪效果展示
7.1 set12灰度测试集
下面对比度中左上图为原始噪声图;右上图为高斯噪声标准差7去噪结果;左下图为高斯噪声标准差15去噪结果;右下图为高斯噪声标准差50去噪结果。





从上面几个对比场景中可以看出,高斯噪声标准差为50时,细节损失严重,且部分场景细节发生了畸变。标准差为7时,去除噪声的同时能够更好的保留原图细节,推荐学者高斯噪声标准差为7模型。
7.2 Real_faces灰度测试集
下面对比图中,左图为原图;中间图为高斯噪声标准差15;右图为高斯噪声标准差7。






7.3 McMaster彩色测试集
下面对比图中,左图为原噪声图,右图为使用官网提供的005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth模型去噪结果。






7.4 真实噪声彩色测试集
下面对比图中左上图为原图;右上上图为官网提供的005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth模型去噪结果;左下图为官网提供的005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth模型去噪结果;右下图为官网提供的005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth模型去噪结果。








八、总计
本博文主要讲解了SwinIR网络在去噪方面的训练和推理测试,下一期会更新SwinIR网络超分辨率重建教程。
博文中详细讲解了SwinIR网络训练噪声网络的过程及提供多组测试对比结果,希望能帮到学者快速了解此网络。
感谢您阅读到最后!😊总结不易,多多支持呀🌹 点赞👍收藏⭐评论✍️,您的三连是我持续更新的动力💖
关注公众号「视觉研坊」,获取干货教程、实战案例、技术解答、行业资讯!



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











