







1 搜索迭代器
ANN Search 对单次查询可调用的实体数量有最大限制,因此仅使用基本 ANN Search 可能无法满足大规模检索的需求。对于 topK 超过 16,384 的 ANN Search 请求,建议考虑使用 SearchIterator。
1.1 概述
Search 请求返回搜索结果,而 SearchIterator 返回迭代器。您可以调用该迭代器的next()方法来获取搜索结果。具体来说,您可以如下使用 SearchIterator:
- 创建一个 SearchIterator,并设置每次搜索请求返回的实体数和返回的实体总数。
- 在循环中调用 SearchIterator 的next()方法,以分页方式获取搜索结果。
- 如果next()方法返回的结果为空,则调用迭代器的close()方法结束循环。
1.2 创建搜索迭代器
以下代码片段演示了如何创建一个 SearchIterator。
from pymilvus import connections, Collection
connections.connect(
uri="http://localhost:19530",
token="root:Milvus"
)
# create iterator
query_vectors = [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]]
collection = Collection("iterator_collection")
iterator = collection.search_iterator(
data=query_vectors,
anns_field="vector",
param={"metric_type": "L2", "params": {"nprobe": 16}},
# highlight-next-line
batch_size=50,
output_fields=["color"],
# highlight-next-line
limit=20000
)在上述示例中,您将每次搜索返回的实体数(batch_size/batchSize)设置为 50,将返回的实体总数(topK)设置为 20,000。
1.3 使用 SearchIterator
SearchIterator 就绪后,您可以调用它的 next() 方法,以分页方式获取搜索结果。
results = []
while True:
# highlight-next-line
result = iterator.next()
if not result:
# highlight-next-line
iterator.close()
break
for hit in result:
results.append(hit.to_dict())在上述代码示例中,您创建了一个无限循环,并在循环中调用next()方法将搜索结果存储到一个变量中,然后在next()没有返回任何结果时关闭迭代器。
2 使用分区密钥
分区关键字是一种基于分区的搜索优化解决方案。通过指定特定标量字段作为 Partition Key,并在搜索过程中根据 Partition Key 指定过滤条件,可以将搜索范围缩小到多个分区,从而提高搜索效率。
2.1 概述
在 Milvus 中,你可以使用分区来实现数据隔离,并通过将搜索范围限制在特定分区来提高搜索性能。如果选择手动管理分区,可以在 Collections 中创建最多 1,024 个分区,并根据特定规则将实体插入这些分区,这样就可以通过限制在特定数量的分区内进行搜索来缩小搜索范围。
Milvus 引入了分区密钥,供你在数据隔离中重复使用分区,以克服在集合中创建分区数量的限制。创建 Collections 时,可以使用标量字段作为 Partition Key。一旦集合准备就绪,Milvus 就会在集合内创建指定数量的分区。收到插入的实体后,Milvus 会使用实体的分区密钥值计算一个哈希值,根据哈希值和集合的partitions_num 属性执行求模操作,以获得目标分区 ID,并将实体存储到目标分区中。
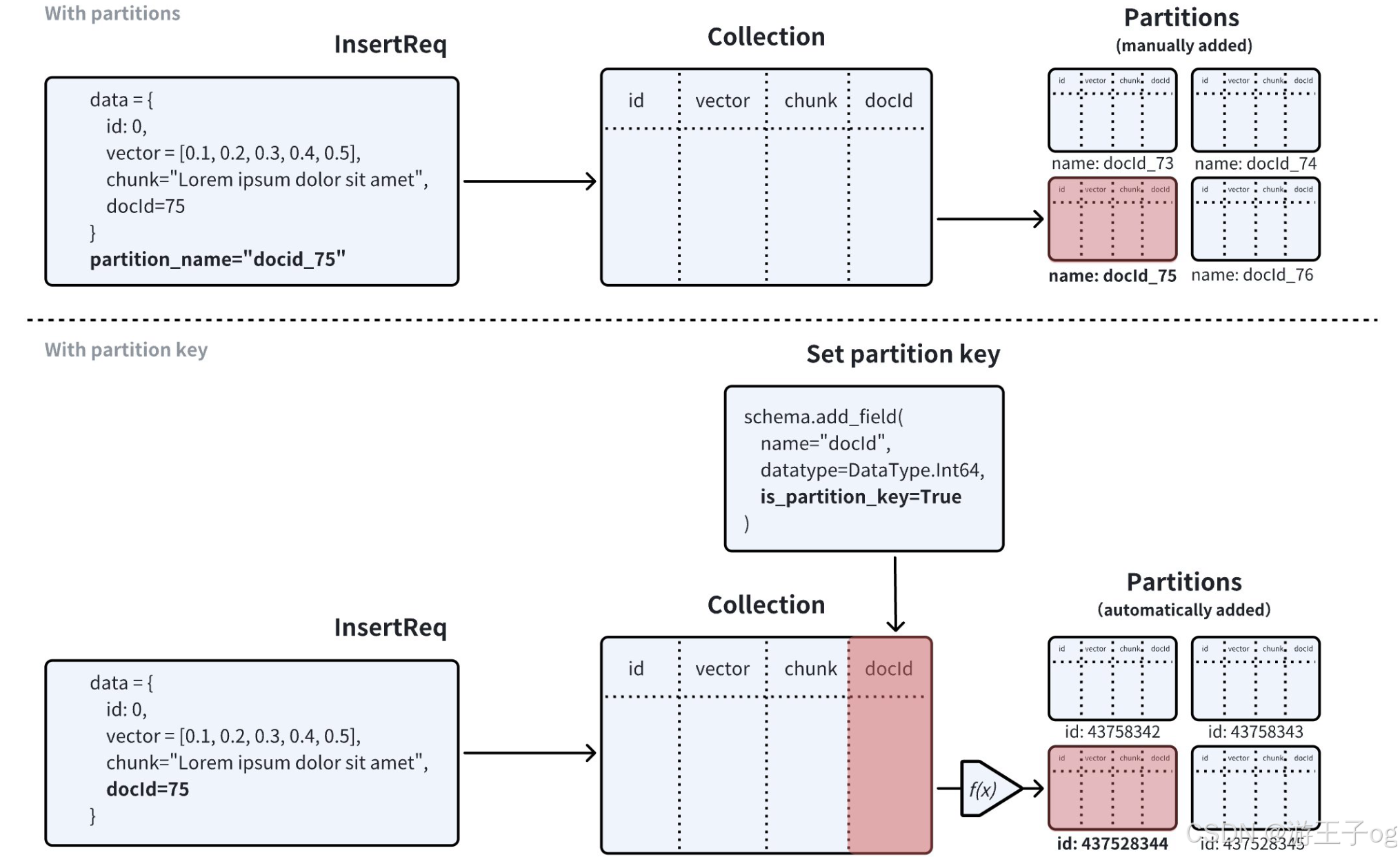
下图说明了在启用或未启用分区密钥功能的情况下,Milvus 如何处理 Collections 中的搜索请求。
- 如果禁用了 Partition Key,Milvus 会在 Collections 中搜索与查询向量最相似的实体。如果知道哪个分区包含最相关的结果,就可以缩小搜索范围。
- 如果启用了分区关键字,Milvus 会根据搜索过滤器中指定的分区关键字值确定搜索范围,并只扫描分区内匹配的实体。
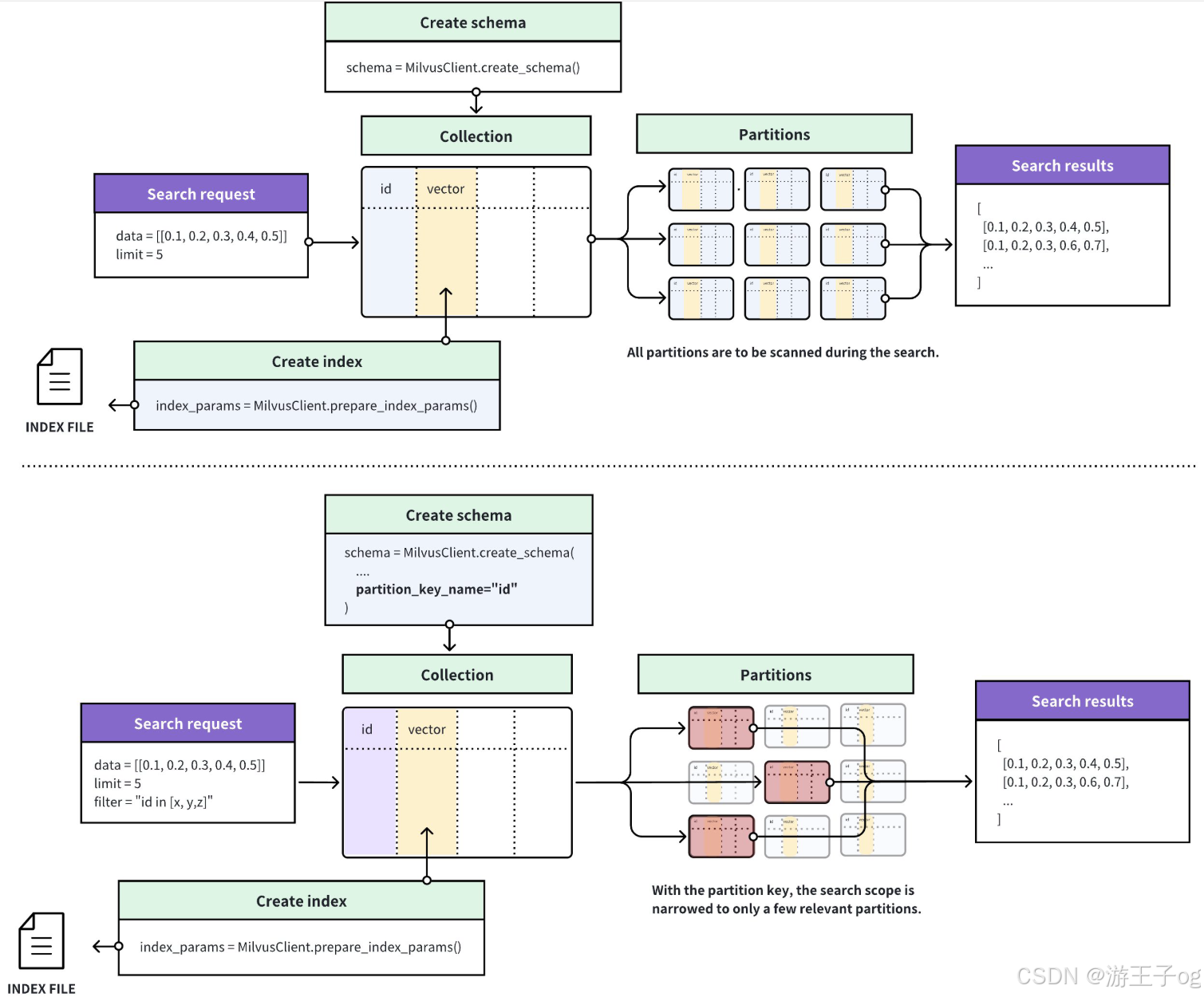
2.2 使用分区密钥
2.2.1 设置分区密钥
要将标量字段指定为分区密钥,需要在添加标量字段时将其is_partition_key 属性设置为true 。字段值不能为空或 null。
from pymilvus import (
MilvusClient, DataType
)
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema()
schema.add_field(field_name="id",
datatype=DataType.INT64,
is_primary=True)
schema.add_field(field_name="vector",
datatype=DataType.FLOAT_VECTOR,
dim=5)
# 添加分区秘钥
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512,
# highlight-next-line
is_partition_key=True,
)2.2.2 设置分区编号
当你指定一个 Collections 中的标量字段作为 Partition Key 时,Milvus 会自动在 Collections 中创建 16 个分区。在接收到一个实体时,Milvus 会根据这个实体的 Partition Key 值选择一个分区,并将实体存储在分区中,从而导致部分或全部分区持有不同 Partition Key 值的实体。您还可以确定与 Collections 一起创建的分区数量。只有将标量字段指定为 Partition Key 时,这种方法才有效。
client.create_collection(
collection_name="my_collection",
schema=schema,
# highlight-next-line
num_partitions=128
)2.2.3 创建过滤条件
在启用分区关键字功能的 Collections 中进行 ANN 搜索时,需要在搜索请求中包含涉及分区关键字的过滤表达式。在过滤表达式中,你可以将 Partition Key 的值限制在特定范围内,这样 Milvus 就会将搜索范围限制在相应的分区内。
在执行删除操作时,建议加入指定单一分区键的过滤表达式,以实现更高效的删除。这种方法将删除操作限制在特定分区内,减少了压缩过程中的写入放大,节省了用于压缩和索引的资源。下面的示例演示了基于 Partition Key 的过滤,它基于一个特定的 Partition Key 值和一组 Partition Key 值。
# 基于单个分区键值筛选,或
filter='partition_key == "x" && <other conditions>'
# 根据多个分区键值进行筛选
filter='partition_key in ["x", "y", "z"] && <other conditions>' 必须将partition_key 替换为指定为分区密钥的字段名称。
2.3 使用 Partition Key 隔离
在多租户场景中,可以将与租户身份相关的标量字段指定为分区密钥,并根据此标量字段中的特定值创建过滤器。为了进一步提高类似情况下的搜索性能,Milvus 引入了分区密钥隔离功能。
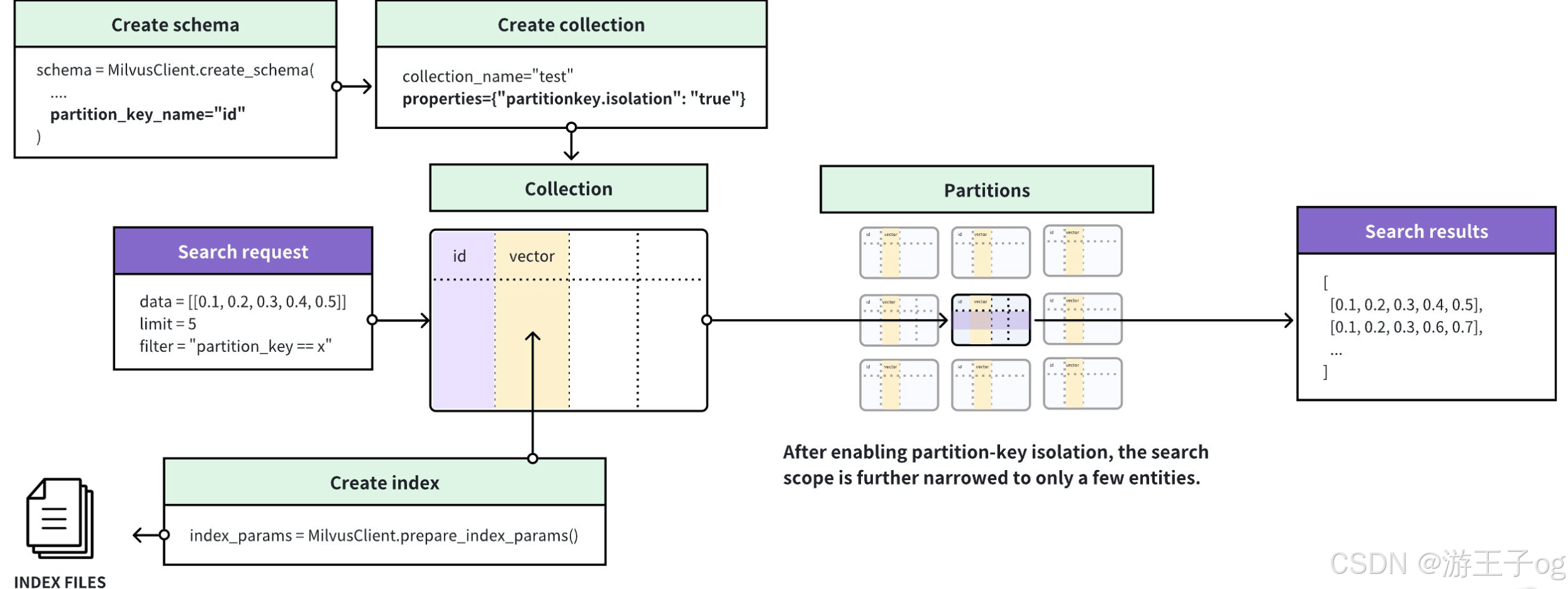
如上图所示,Milvus 根据分区键值对实体进行分组,并为每个分组创建单独的索引。收到搜索请求后,Milvus 会根据过滤条件中指定的 Partition Key 值定位索引,并将搜索范围限制在索引所包含的实体内,从而避免在搜索过程中扫描不相关的实体,大大提高搜索性能。启用 "分区密钥隔离 "后,必须在基于分区密钥的过滤条件中只包含一个特定值,这样 Milvus 才能在匹配的索引所包含的实体内限制搜索范围。
以下代码示例演示了如何启用分区键隔离。
client.create_collection(
collection_name="my_collection",
schema=schema,
# highlight-next-line
properties={"partitionkey.isolation": True}
)启用分区密钥隔离后,仍可按照设置分区编号中的说明设置分区密钥和分区数量。请注意,基于 Partition Key 的过滤器应只包含特定的 Partition Key 值。


















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











