







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本文是针对ICCV(2021)论文:AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer的讲解。
一、文章贡献?
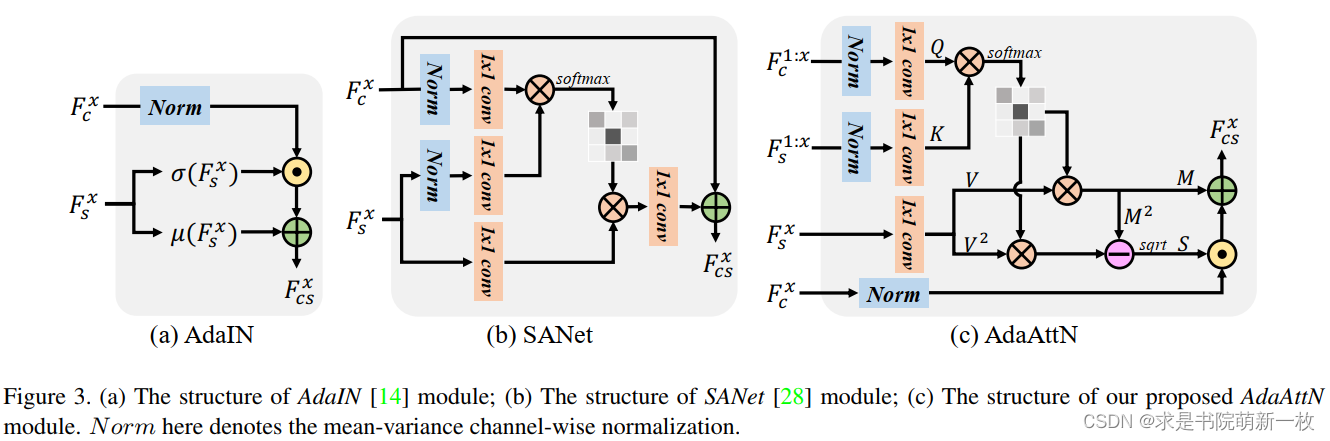
直接看图三作者提出的注意力机制的主图,和SANET基本保持一直,首先是根据风格图片和内容图片的特征计算注意力图,然后仍然是乘上一个风格特征,最后补充内容特征,但是不同的是作者提出了在这个过程中计算一个标准差。
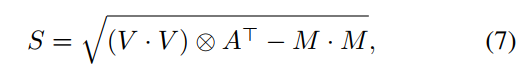
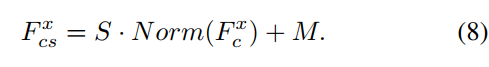
这是因为方差等于平方的期望减期望的平方,有如下推导:
Var = E[(X-μ)²] = E[X²-2Xμ+μ²] = E(X²)-2μ²+μ² = E(X²)-μ²
因此这和以往将特征乘上一个方差再加一个均值是类似的操作。
实验效果图:

总结
从实验结果来看,这篇论文的效果还是非常不错的,实测中尤其是对人脸效果更佳,简单描述一下,有什么问题再补充。















 2941
2941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









