






引言
如图2所示,本文通过目标中心点来表示物体,然后在在中心点位置回归出目标如维度、大小、姿势等其他属性,把目标检测问题转变成一个标准的关键点估计问题,将图像传入全卷积网络,得到一个热力图,热力图峰值点即中心点,每个特征图的峰值点位置预测了目标的宽高信息。

模型训练采用标准的监督学习,推理仅仅是单个前向传播网络,不存在NMS这类后处理。运行速度与AP如图1所示:

相关工作
Object detection by region classification:RCNN系列方法枚举大量候选的对象位置,再使用深层网络进行分类,依赖于区域建议方法
Object detection with implicit anchors:Faster RCNN通过手动设置的阈值做前后景分类,会将与GT的IOU >0.7的作为前景,<0.3的作为背景,本文与anchor-based one-stage方法相近,中心点可看成形状未知的锚点,如图3所示:

但也有一些重要的差异:
①锚点仅仅是放在位置上,没有尺寸框,没有手动设置的阈值做前后景分类
②每个目标仅仅有一个正的锚点,因此不会用到NMS
③CenterNet相比传统目标检测而言(缩放16倍尺度),使用更大分辨率的输出特征图(缩放了4倍),因此无需用到多重特征图锚点;
Object detection by keypoint estimation:CornerNet将bbox的两个角作为关键点;ExtremeNet 检测所有目标的最上,最下,最左,最右,中心点,这些网络和本文的一样都建立在鲁棒的关键点估计网络之上。但是它们都需要经过一个关键点grouping阶段,这会降低算法整体速度;而本文算法仅仅提取每个目标的中心点,无需对关键点进行grouping 或者是后处理;
方法


实验
在COCO数据集上与SOTA方法的对比实验如表2:

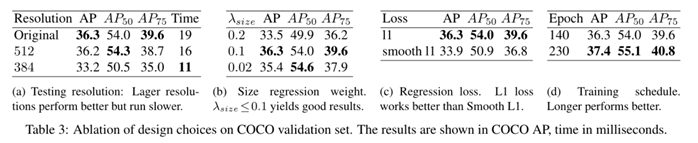
消融实验如表3:
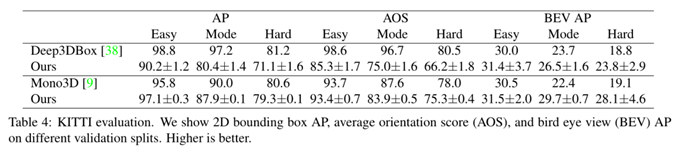
3D的实验在KITTI上效果如表4:
总结
这是我看的第一篇关于anchor-free的文章,该文章提出了CenterNet,把目标建模成一个点,然后对确立的中心点的图像特征进行回归得到目标的尺寸等信息,把图像送入一个全卷积网络,产生一个热力图,这张热力图的峰值就是目标的中心点,再利用每一个峰值位置的图像特征预测目标的宽度和高度,因此它不需要设置anchor的尺寸、阈值,也不需要NMS后处理,一定程度上减少了训练的时间和复杂度















 1771
1771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









