






1. Motivation
- 传统方法要求图像中的块之间存在相似性;
- 人脸有很明显的几何特征,几何信息的先验知识很重要;
- 如何在模型中实现对人脸的编辑。
2. Approach
2.1 Network architecture

整体的网络框架如上图所示,分为三部分:面部几何信息的估计,生成器和判别器。
- Facial geometry estimator

网络的输入是待补全的图像,目标是学习出人脸的关键点和分割结果,网络的中间部分采用了 HG block【2】。
- Face completion generator
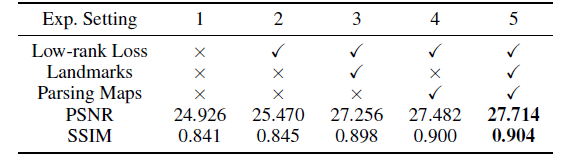
将待补全的图像和几何信息(关键点和分割结果)concat,学习出它们的特征,这是网络的编码部分。解码器有两个,输入信息中包含没用的信息(白色区域),所以提取的特征中也含有没用的信息,可能会对图像的生成产生干扰,需要分离生成的图像和噪声(mask),这个思路有点像 【3】,只不过【3】是在提取特征是就尝试剔除无用的信息,这篇文章中的模型生成器部分需要学习出补全后的图像和mask,主要是将提取的特征分为两部分,一部分包含图像信息,另一部分包含mask信息。从作者给出的结果来看,学习 mask加上低秩损失确实对实验效果有提升
- discriminators
两个判别器,局部+全局。
2.2 Loss function
- 低秩损失:mask是低秩的(核范数)
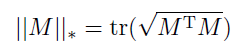
- 重构损失:图像,人脸关键点和分割结果三个重构损失
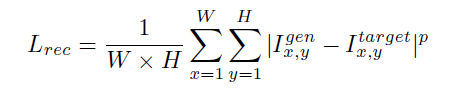
- 对抗损失:局部的损失加上全局的损失
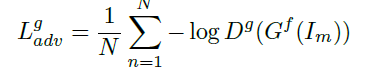
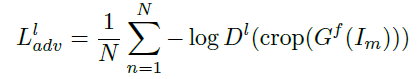
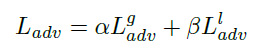
- 对称损失:人脸具有高度对称的结构
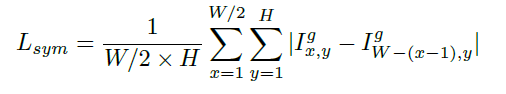
- 最终损失:
![]()
其中是正则项【4】。
3. Discussion
我认为这篇文章的创新点有以下两个:
- 采用了几何的先验知识,让网络学习几何信息,通过修改几何信息可以编辑生成的人脸;
- 从一个新的角度出发,分离图像的信息和 mask的信息。
这篇论文的代码并没有开源,所以有的细节部分我可能理解的不好,视频【5】是作者关于这篇论文的一个报告。
4. References
【1】Chen, Yu, et al. "Adversarial posenet: A structure-aware convolutional network for human pose estimation." Proceedings of the IEEE International Conference on Computer Vision. 2017.
【2】Liu, Guilin, et al. "Image inpainting for irregular holes using partial convolutions." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
【3】Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. "Perceptual losses for real-time style transfer and super-resolution." European conference on computer vision. Springer, Cham, 2016.
【4】Song, Linsen, et al. "Geometry-aware face completion and editing." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 2019.
【5】 宋林森. "图像/人脸补全问题的前世今生". 人工智能前沿讲习. 2019.















 2219
2219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









