






Traceback (most recent call last):
File "/home/sys120-1/cy/mamba/test.py", line 205, in <module>
pred = model(inputs)
File "/home/sys120-1/miniconda3/envs/mamba/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/sys120-1/miniconda3/envs/mamba/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
File "/home/sys120-1/cy/mamba/test.py", line 138, in forward
out = mamba_split_conv1d_scan_combined(
File "/home/sys120-1/miniconda3/envs/mamba/lib/python3.10/site-packages/mamba_ssm/ops/triton/ssd_combined.py", line 930, in mamba_split_conv1d_scan_combined
return MambaSplitConv1dScanCombinedFn.apply(zxbcdt, conv1d_weight, conv1d_bias, dt_bias, A, D, chunk_size, initial_states, seq_idx, dt_limit, return_final_states, activation, rmsnorm_weight, rmsnorm_eps, outproj_weight, outproj_bias, headdim, ngroups, norm_before_gate)
File "/home/sys120-1/miniconda3/envs/mamba/lib/python3.10/site-packages/torch/autograd/function.py", line 598, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "/home/sys120-1/miniconda3/envs/mamba/lib/python3.10/site-packages/torch/cuda/amp/autocast_mode.py", line 115, in decorate_fwd
return fwd(*args, **kwargs)
File "/home/sys120-1/miniconda3/envs/mamba/lib/python3.10/site-packages/mamba_ssm/ops/triton/ssd_combined.py", line 779, in forward
causal_conv1d_cuda.causal_conv1d_fwd(rearrange(xBC, "b s d -> b d s"),
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
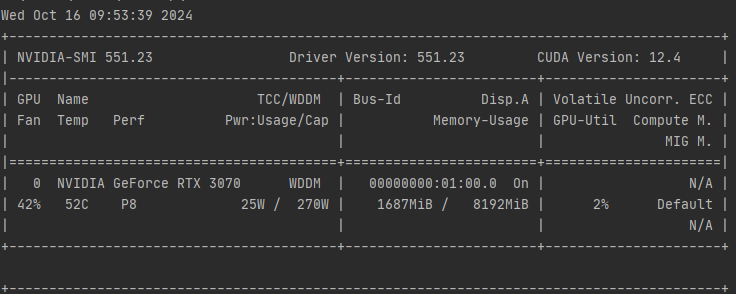
经过仔细排查,发现是GPU驱动和CUDA版本不一致,GPU驱动显示最大版本为11.4,CUDA版本为11.8,导致出现错误,需要升级GPU驱动或者降低CUDA版本。

















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









