






1. 错误现象:
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
2. 原因分析:
一般报这样的错,主要原因是torch版本和cuda版本不匹配导致的。
3. 解决办法:
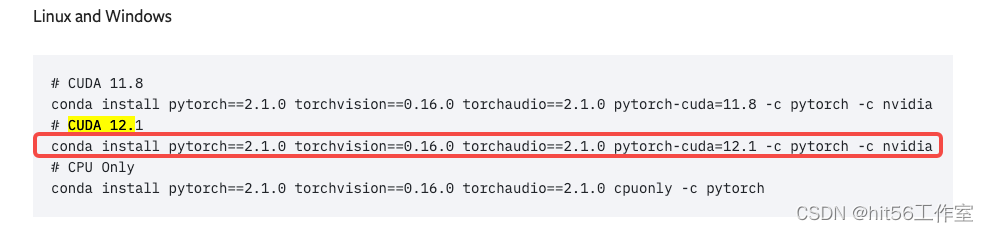
去pytorch官网,找到适合自己cuda的torch版本
例如,假设你的cuda版本是12.2,那么你可以将就着用下面的cuda12.1的torch版本


















 4212
4212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









