







CARAFE: Content-Aware ReAssembly of FEatures
CARAFE: 轻量级通用上采样算子
其他上采样方法的不足
- 最近邻或者双线性上采样
仅通过像素点的空间位置来决定上采样核,并没有利用到特征图的语义信息,可以看作是一种“均匀”的上采样,而且感知域通常都很小(最近邻 1x1,双线性 2x2); - Deconvolution
上采样核并不是通过像素间的距离计算,而是通过网络学出来的,但对于特征图每个位置都是应用相同的上采样核,不能捕捉到特征图内容的信息,另外引入了大量参数和计算量,尤其是当上采样核尺寸较大的时候; - Dynamic filter
对于特征图每个位置都会预测一组不同的上采样核,但是参数量和计算量更加爆炸,而且公认比较难学习;
理想上采样算子的特性
- Large receptive field:需要具有较大的感受野,这样才能更好地利用周围的信息;
- Content-aware:上采样核应该和特征图的语义信息相关,基于输入内容进行上采样;
- Lightweight:轻量化,不能引入过多的参数和计算量;
CARAFE

CARAFE 分为两个主要模块,分别是上采样核预测模块和特征重组模块。假设上采样倍率为
σ
\sigma
σ,给定一个形状为
H
×
W
×
C
H\times W\times C
H×W×C的输入特征图,CARAFE首先利用上采样核预测模块预测上采样核,然后利用特征重组模块完成上采样,得到形状为
σ
H
×
σ
W
×
C
\sigma H\times \sigma W\times C
σH×σW×C的输出特征图。
上采样核预测模块

-
特征图通道压缩
对于形状为 H × W × C H\times W\times C H×W×C的输入特征图,首先用一个 1 × 1 1\times 1 1×1卷积将它的通道数压缩到 H × W × C m H\times W\times C_m H×W×Cm,这一步的主要目的是减小后续步骤的计算量。 -
内容编码及上采样核预测
假设上采样核尺寸为 k u p × k u p k_{up}\times k_{up} kup×kup(越大的上采样核意味着更大的感受野和更大的计算量),如果希望对输出特征图的每个位置使用不同的上采样核,那么需要预测的上采样核形状为 σ H × σ W × k u p × k u p \sigma H\times \sigma W\times k_{up}\times k_{up} σH×σW×kup×kup。
对于第一步中压缩后的输入特征图,利用一个 k e n c o d e r × k e n c o d e r k_{encoder}\times k_{encoder} kencoder×kencoder的卷积层来预测上采样核,输入通道数为 C m C_m Cm,输出通道数为 σ 2 k u p 2 \sigma^2 k_{up}^2 σ2kup2,然后将通道维在空间维展开,得到形状为 σ H × σ W × k u p 2 \sigma H\times \sigma W\times k_{up}^2 σH×σW×kup2的上采样核。 -
上采样核归一化
对第二步中得到的上采样核利用 softmax 进行归一化,使得卷积核权重和为 1。
特征重组模块

对于输出特征图中的每个位置,将其映射回输入特征图,取出以之为中心的
k
u
p
×
k
u
p
k_{up}\times k_{up}
kup×kup的区域,和预测出的该点的上采样核作点积,得到输出值。相同位置的不同通道共享同一个上采样核。
参数量计算
参
数
量
=
2
(
C
i
n
+
1
)
C
m
+
2
(
C
m
k
e
n
c
o
d
e
r
2
σ
2
k
e
n
c
o
d
e
r
2
+
1
)
σ
2
k
u
p
2
+
2
σ
2
k
u
p
2
C
i
n
参数量=2(C_{in}+1)C_m+2(C_mk_{encoder}^2 \sigma^2k_{encoder}^2+1)\sigma^2k_{up}^2+2\sigma^2k_{up}^2C_{in}
参数量=2(Cin+1)Cm+2(Cmkencoder2σ2kencoder2+1)σ2kup2+2σ2kup2Cin
(不太懂2是什么意思)
超参
-
C
m
C_m
Cm: 压缩通道数,论文中设为64,继续增大并不会带来性能提升
但是这里没有说明原本的通道数是多少,应该按照比例进行压缩,而不是直接定64

-
k
e
n
c
o
d
e
r
,
k
u
p
k_{encoder}, k_{up}
kencoder,kup
只有同步增加 k e n c o d e r , k u p k_{encoder}, k_{up} kencoder,kup才能提升性能,单独增加一个无法提升性能;
遵循 k e n c o d e r = k u p − 2 k_{encoder}=k_{up}-2 kencoder=kup−2
推荐 k e n c o d e r = 3 , k u p = 5 k_{encoder}=3, k_{up}=5 kencoder=3,kup=5,(性能与计算量的折中)

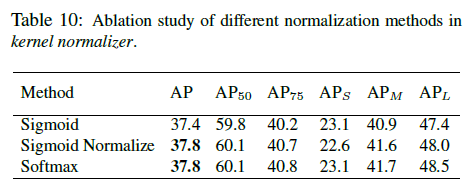
- 归一化的方法
Softmax与Sigmoid Normalized 性能相同
pytorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class CARAFE(nn.Module):
def __init__(self, inC, outC, kernel_size=3, up_factor=2):
super(CARAFE, self).__init__()
self.kernel_size = kernel_size
self.up_factor = up_factor
self.down = nn.Conv2d(inC, inC // 4, 1)
self.encoder = nn.Conv2d(inC // 4, self.up_factor ** 2 * self.kernel_size ** 2,
self.kernel_size, 1, self.kernel_size // 2)
self.out = nn.Conv2d(inC, outC, 1)
def forward(self, in_tensor):
N, C, H, W = in_tensor.size()
# N,C,H,W -> N,C,delta*H,delta*W
# kernel prediction module
kernel_tensor = self.down(in_tensor) # (N, Cm, H, W)
kernel_tensor = self.encoder(kernel_tensor) # (N, S^2 * Kup^2, H, W)
kernel_tensor = F.pixel_shuffle(kernel_tensor, self.up_factor) # (N, S^2 * Kup^2, H, W)->(N, Kup^2, S*H, S*W)
kernel_tensor = F.softmax(kernel_tensor, dim=1) # (N, Kup^2, S*H, S*W)
kernel_tensor = kernel_tensor.unfold(2, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W*S, S)
kernel_tensor = kernel_tensor.unfold(3, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W, S, S)
kernel_tensor = kernel_tensor.reshape(N, self.kernel_size ** 2, H, W, self.up_factor ** 2) # (N, Kup^2, H, W, S^2)
kernel_tensor = kernel_tensor.permute(0, 2, 3, 1, 4) # (N, H, W, Kup^2, S^2)
# content-aware reassembly module
# tensor.unfold: dim, size, step
in_tensor = F.pad(in_tensor, pad=(self.kernel_size // 2, self.kernel_size // 2,
self.kernel_size // 2, self.kernel_size // 2),
mode='constant', value=0) # (N, C, H+Kup//2+Kup//2, W+Kup//2+Kup//2)
in_tensor = in_tensor.unfold(2, self.kernel_size, step=1) # (N, C, H, W+Kup//2+Kup//2, Kup)
in_tensor = in_tensor.unfold(3, self.kernel_size, step=1) # (N, C, H, W, Kup, Kup)
in_tensor = in_tensor.reshape(N, C, H, W, -1) # (N, C, H, W, Kup^2)
in_tensor = in_tensor.permute(0, 2, 3, 1, 4) # (N, H, W, C, Kup^2)
out_tensor = torch.matmul(in_tensor, kernel_tensor) # (N, H, W, C, S^2)
out_tensor = out_tensor.reshape(N, H, W, -1)
out_tensor = out_tensor.permute(0, 3, 1, 2)
out_tensor = F.pixel_shuffle(out_tensor, self.up_factor)
out_tensor = self.out(out_tensor)
return out_tensor
if __name__ == '__main__':
data = torch.rand(4, 20, 10, 10)
carafe = CARAFE(20, 10)
print(carafe(data).size())















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









