









隐马尔可夫模型
马尔科夫链的核心是:在给定当前知识或信息的情况下,过去对于预测将来是无关的**,未来仅与当前有关,而与历史无关.**
在观察一个系统变化的时候,他的下一个状态如何的概率只需要观察和统计当前状态即可得出
HMM: 通过统计的办法,可以去观察和认知一个事件序列上邻近事件发生的概率转换问题
P ( x 2 ∣ . . . , x t − 2 , x t − 1 , x t ) = P ( x t + 1 ∣ x t ) P(x_2|...,x_{t-2},x_{t-1},x_t) = P(x_{t+1}|x_t) P(x2∣...,xt−2,xt−1,xt)=P(xt+1∣xt)

你知道这个地区的总的天气趋势,并且平时知道你朋友会做的事情, ----> 也就是说这个隐马尔可夫模型的参数是已知的
基本概念
马尔科夫链-------状态转移矩阵
理解为所有情况下,状态转移发生的概率
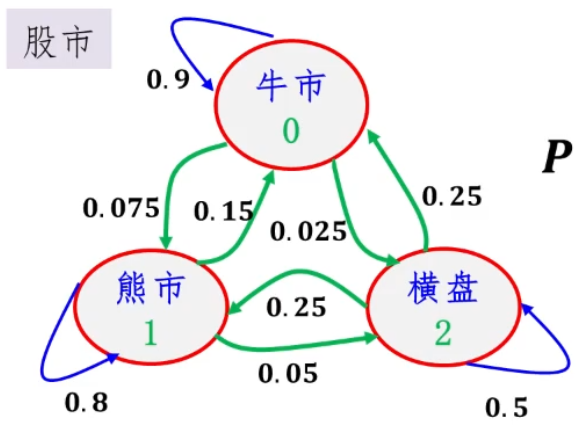
P = [ 牛 市 熊 市 横 盘 牛 市 0.9 0.075 0.025 熊 市 0.15 0.8 0.05 横 盘 0.25 0.25 0.5 ] P=\left[ \begin{matrix} \ & 牛市& 熊市& 横盘\\ 牛市&0.9 & 0.075& 0.025 \\ 熊市 & 0.15 & 0.8 & 0.05 \\ 横盘 & 0.25& 0.25 & 0.5 \\ \end{matrix} \right] P=⎣⎢⎢⎡ 牛市熊市横盘牛市0.90.150.25熊市0.0750.80.25横盘0.0250.050.5⎦⎥⎥⎤ 状态状态转移矩阵
隐马尔可夫模型
马尔科夫链 + 一般随机过程
-
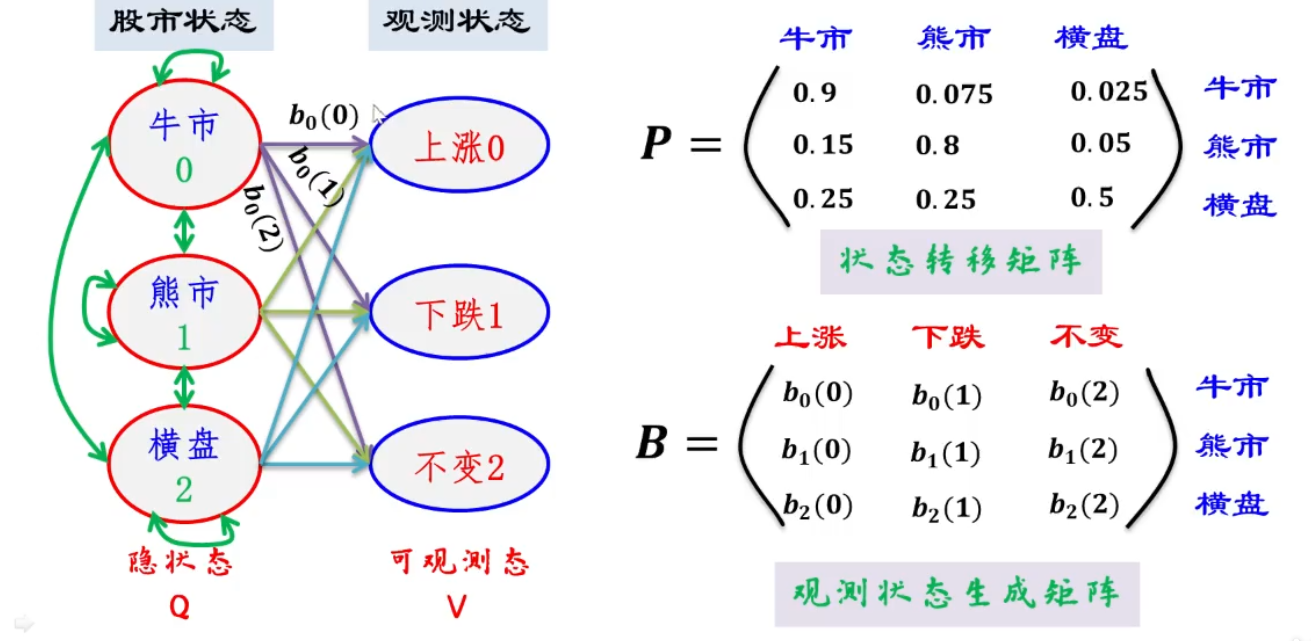
当知道隐状态,根据观测状态生成矩阵,就可以知道观测状态发生概率
-
隐状态是通过 状态转移矩阵, 通过初始状态,预测现在的状态
-
所以 只需要一个 初始状态即可.
可知, 股市状态变化的判断,就是一个马尔科夫链,股市状态到观测状态的变化就是一个一般随机过程
数学定义
定义: 隐 状 态 集 合 Q = [ q 1 , q 2 , . . . q N ] , 可 观 测 态 集 合 V = v 1 , v 2 , v 3 . . . . , v M 隐状态集合 Q= \left[ q_1,q_2,...q_N \right] , 可观测态集合 V = {v_1 , v_2 ,v_3....,v_M } 隐状态集合Q=[q1,q2,...qN],可观测态集合V=v1,v2,v3....,vM
状 态 序 列 Q = i 1 , i 2 , . . . i N , 观 测 态 序 列 V = o 1 , o 2 , o 3 . . . . , o M 状态序列 Q= { i_1,i_2,...i_N} , 观测态序列 V = {o_1 , o_2 ,o_3....,o_M } 状态序列Q=i1,i2,...iN,观测态序列V=o1,o2,o3....,oM
#####两个基本假设
-
t时刻的隐状态只依赖t-1时刻的隐状态
P ( i t ∣ t t − 1 , o t − 1 , t t − 2 , o t − 2 . . . t 1 , o 1 ) = P ( i t ∣ i t − 1 ) , t = 1 , 2 , . . . T P(i_t|t_{t-1},o_{t-1},t_{t-2},o_{t-2}...t_{1},o_{1})=P(i_t|i_{t-1}),t=1,2,... T P(it∣tt−1,ot−1,tt−2,ot−2...t1,o1)=P(it∣it−1),t=1,2,...T
-
t时刻的观测态只依赖t时刻的隐状态
P ( o t ∣ i T , o T , i T − 1 , o T − 1 . . . i t , o t , i t − 1 , o t − 1 . . . t 1 , o 1 ) = P ( o t ∣ i t ) P(o_t|i_{T},o_{T},i_{T-1},o_{T-1}...i_{t},o_{t},i_{t-1},o_{t-1}...t_{1},o_{1})=P(o_t|i_{t}) P(ot∣iT,oT,iT−1,oT−1...it,ot,it−1,ot−1...t1,o1)=P(ot∣it)
状态转移矩阵: A = [ a i j ] N × M A=\left[ \begin{matrix}\ a_{ij} \\ \end{matrix} \right]_{N×M} A=[ aij]N×M
其中 a i j = P ( i i + 1 = q j ∣ i t = q i ) a_{ij} = P(i_{i+1}=q_j|i_t =q_i) aij=P(ii+1=qj∣it=qi)
t时刻为$ q_i$ 状态下, t + 1 t+1 t+1时刻转化成 q j q_j qj的状态的概率是多少
观测状态生成矩阵: B = [ b j ( k ) ] N × M B=\left[ \begin{matrix}\ b_{j}(k) \\ \end{matrix} \right]_{N×M} B=[ bj(k)]N×M
其中 b j ( k ) = P ( o t = v k ∣ i t = q j ) b_{j}(k) = P(o_{t}=v_k|i_t =q_j) bj(k)=P(ot=vk∣it=qj)
在隐状态为 q j q_j qj的情况下,观测状态为 v k v_k vk的概 率是 多少
隐状态初始概率分布: Π = [ π i ] N \Pi = \left[ \pi_{i} \right]_N Π=[πi]N
其中 π i = P ( i 1 = q i ) \pi_i= P(i_1 = q_i) πi=P(i1=qi)
初始时刻,第 i i i个隐状态出现的概率
综上,HMM模式: λ = ( A , B , Π ) \lambda = (A,B,\Pi) λ=(A,B,Π)
用于解决 三个基本问题
观测序列概率
-
λ = ( A , B , Π ) \lambda = ( A,B, \Pi) λ=(A,B,Π) 已知模型
-
O = { o 1 , o 2 , . . . . o T } O = \{o_1,o_2,....o_T \} O={o1,o2,....oT} 预测这种序列发生的概率
====> P = ( O ∣ λ ) P = (O| \lambda ) P=(O∣λ)
那么如何求概率P:
穷举法
概述:通过列举所有长度为T的隐状态序列,然后对每种隐状态序列下出现观测序列的概率进行求和,即可得出这种观测序列出现的概率
优缺点:穷举方法直接有效,但当隐状态较多时,复杂度高
P = P ( O ∣ λ ) = ∑ I P ( O , I ∣ λ ) P =P(O| \lambda )= \sum_I P(O,I|\lambda) P=P(O∣λ)=∑IP(O,I∣λ)
,其中$ P(O,I|\lambda) 是 指 在 模 型 是指在模型 是指在模型\lambda$下,某个隐状态序列和观测态序列O同时同时发生的概率
所以把每个的隐状态序列下,当前隐状态序列和观测态序列O同时发生的概率相加求和就是模型λ下,观测态序列O的发生概率
P ( O , I ∣ λ ) = P ( I ∣ λ ) P ( O ∣ I , λ ) P(O,I|\lambda)= P(I|\lambda)P(O|I,\lambda) P(O,I∣λ)=P(I∣λ)P(O∣I,λ) 根据贝叶斯公式得来,模型λ下 当前隐状态序列I发生的概率 × 模型λ和当前隐状态序列I下 观测态序列O 的发生概率
P ( I ∣ λ ) = π i 1 a i 1 i 2 a i 2 i 3 . . . a i T − 1 i T P(I|\lambda) = \pi_{i_1}a_{i_1i_2}a_{i_2i_3}...a_{i_{T-1}i_T} P(I∣λ)=πi1ai1i2ai2i3...aiT−1iT
其中 π i 1 \pi_{i_1} πi1是指初始隐状态为 i 1 i_1 i1的概率 $ P(I|\lambda)$ 是指当前隐状态序列出现的概率
P ( O ∣ I , λ ) = b i 1 ( o 1 ) b i 2 ( o 2 ) . . . b i T ( o T ) P(O|I,\lambda)= b_{i_1}(o_1) b_{i_2}(o_2)...b_{i_T}(o_T) P(O∣I,λ)=bi1(o1)bi2(o2)...biT(oT)
前向后向算法
每次向前,都是通过计算 当前时刻 t t t,所有的N个隐状态 在 下一时刻 t + 1 {t+ 1} t+1出现隐状态 i h , h = { 1 , 2 , . . . , N } i_{h},h=\{1,2,...,N\} ih,h={1,2,...,N}且观测态为 o t + 1 o_{t+1} ot+1 的概率 (即有N个结果) ,这N个概率又用于计算下一个时刻 t + 2 t+2 t+2时,出现 隐状态 i h , h = { 1 , 2 , . . . , N } i_{h},h=\{1,2,...,N\} ih,h={1,2,...,N}且观测态为 o t + 2 o_{t+2} ot+2 的概率,直到得出 隐状态 i h , h = { 1 , 2 , . . . , N } , i_{h},h=\{1,2,...,N\}, ih,h={1,2,...,N},且观测态为 o N , o_{N}, oN, 的概率则终止
前向概率 a t ( i ) = P ( o 1 , o 2 , . . . o t , i t = q i ∣ λ ) a_t(i) = P(o_1,o_2,...o_t,i_t = q_i| \lambda ) at(i)=P(o1,o2,...ot,it=qi∣λ)
t时刻,隐状态为i 且观测序列为O的概率
(1) 初值: a 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , 3 , . . , N a_1(i)=\pi_ib_i(o_1) , i=1,2,3,..,N a1(i)=πibi(o1),i=1,2,3,..,N
t 1 t_1 t1时刻,处于各个隐状态和观测态 o 1 o_1 o1同时发生的概率 = 初始时刻,第 i i i个隐状态出现的概率 × 在这个隐状态下,观测态 o 1 o_1 o1的概率
(2) 递推: a t + 1 ( i ) = [ ∑ j = 1 N a t ( j ) a j i ] b i ( o t + 1 ) a_{t+1}(i) = \left[\sum_{j=1}^Na_t(j)a_{ji}\right]b_i(o_{t+1}) at+1(i)=[∑j=1Nat(j)aji]bi(ot+1)
中括号内的含义 :当前时刻所有的N个隐含状态与下一时刻的第i个隐状态的转变
以 a 2 ( i ) a_{2}(i) a2(i) 为例, a 2 ( i ) = [ ∑ j = 1 N a 1 ( j ) a j i ] b i ( o 2 ) a_{2}(i) = \left[\sum_{j=1}^Na_1(j)a_{ji}\right]b_i(o_{2}) a2(i)=[∑j=1Na1(j)aji]bi(o2)
-
a 1 ( j ) a j i a_1(j) a_{ji} a1(j)aji 是指 隐状态为j且观测序列为 O = { o 1 } O=\{o_1\} O={o1} 在下个时刻 t 2 t_2 t2 转变为隐状态为i且观测序列为 O = { o 1 } O=\{o_1\} O={o1} 的概率
-
∑ j = 1 N a 1 ( j ) a j i \sum_{j=1}^Na_1(j)a_{ji} ∑j=1Na1(j)aji是指 所有的隐状态且观测序列为 O = { o 1 } O=\{o_1\} O={o1} 在下个时刻 t 2 t_2 t2 转变为 隐状态为i 且 观测序列为 O = { o 1 } O=\{o_1\} O={o1} 的概率
-
a 2 ( i ) = [ ∑ j = 1 N a 1 ( j ) a j i ] b i ( o 2 ) a_{2}(i) = \left[\sum_{j=1}^Na_1(j)a_{ji}\right]b_i(o_{2}) a2(i)=[∑j=1Na1(j)aji]bi(o2) 是指 隐状态为i 且 观测序列为 O = { o 1 , o 2 } O=\{o_1,o_2\} O={o1,o2} 的概率
(3) 终止: P ( O ∣ λ ) = ∑ i = 1 N a T ( i ) P(O|\lambda) = \sum_{i=1}^Na_T(i) P(O∣λ)=∑i=1NaT(i)
求解在时刻t,所有隐状态的概率求和
-
模型参数学习
- O = { o 1 , o 2 , o 3 . . . o T } O = \{ o_1,o_2,o_3...o_T\} O={o1,o2,o3...oT} 观测到这种序列
====> λ = ( A , B , Π ) \lambda = (A,B,\Pi) λ=(A,B,Π) 尝试去找到三个参数,使得序列发生的概率最大
-
预测(接码)问题
-
λ = ( A , B , Π ) \lambda = (A,B,\Pi) λ=(A,B,Π) 通过观测状态找到了一个模型
-
O = { o 1 , o 2 , . . . . o T } O = \{ o_1,o_2,....o_T \} O={o1,o2,....oT} 观测到这种序列
====> I = { i 1 , i 2 , . . . . , i T } I = \{ i_1,i_2,....,i_T\} I={i1,i2,....,iT} 有了观测序列,有了模型,可以进行 隐状态的预测
-
前向后向算法
RNN和HMM
RNN:是一个循环递归网络,在n时刻,网络的输出误差不仅和n时刻的隐含状态有关,也与n时刻之前的所有的隐含状态有关
RNN相比传统的HMM的优势是充分考虑了历史所有时刻的状态
















 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











