







YOLOv1
论文:You Only Look Once
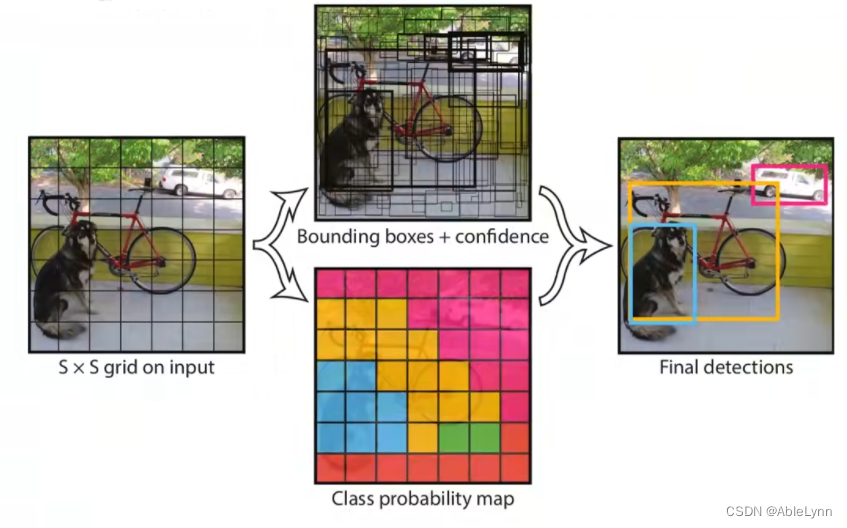
思想:
-
将一幅图像分成S*S个网格,如果某个object(bounding box)的中心落在这个网格中,则这个网格就负责预测这个object
-
每个网格要预测B个bounding box(因为每个网格中可能存在多个object),每个bounding box除了要预测位置之外,还要附带预测一个confidence值,每个网格还要预测c个类别的分数
例如:
- 将图像分成7 * 7个网格,每个网格预测2个bounding box,总共20个类别,则最终的预测是7 * 7 *30个tensor(张量)
- 其中30的由来:
- 每个网格需要预测两个bounding box,则需要两个bounding box的坐标值(x,y,w,h),然后每个bounding box还需要有各自的一个confidence值,再加上总共有20个类别,所以每个网格总共有:4+4+1+1+20=30个tensor(张量)
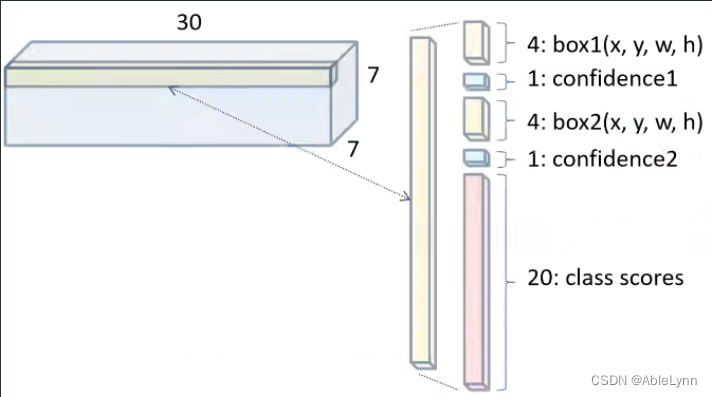
- 其中(x,y)为预测目标边界框的中心坐标(相对于网格),即横纵坐标轴为中心所在网格的长和宽,范围在(0,1)
- 其中(w,h)为预测目标的高和宽(相对于整个图像而言),范围在(0,1)
- 其中confidence为Pr(Objcet) * IOU,其中IOU为预测的目标目标边界框与所对应的真实目标边界框的交并比,Pr(Objcet)的值只能为0(网格中没有目标落入)或者1(网格中有目标落入)
-
最终给出的类别概率分数为:
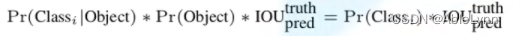
网络结构: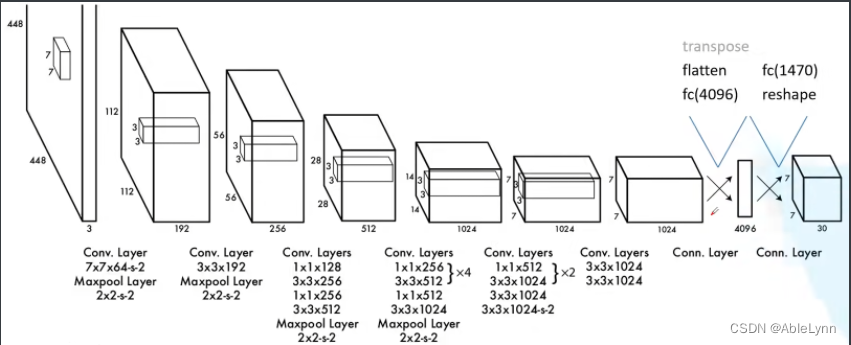
此时可以发现,最终得到的是一个图片大小为7 * 7 深度为30的图像,在YOLOv1论文中,作者把图像分成7 * 7个网格,张量为30(4+1+4+1+20),(每个网格有两个bounding box,每个bounding box有(x,y,w,h,confidence)5个张量,总共有20个类别)
















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









