







一、渲染系统的对象
首先确定渲染系统的对象。宽泛的来讲,就是确定图形的各个顶点,然后将各个顶点连成多个面,之后进行光栅化(Rasterize)将三角形对应上各个像素,进一步进行着色(Shader)对各个像素进行着色处理最终输出成为图像。
 在Rasterize之前通常要先将空间中的物体进行投影,不管是正交投影(Orthographic projection)还是透视投影(Perspective projection)得到屏幕空间中的形状,之后再进行光栅化。
在Rasterize之前通常要先将空间中的物体进行投影,不管是正交投影(Orthographic projection)还是透视投影(Perspective projection)得到屏幕空间中的形状,之后再进行光栅化。
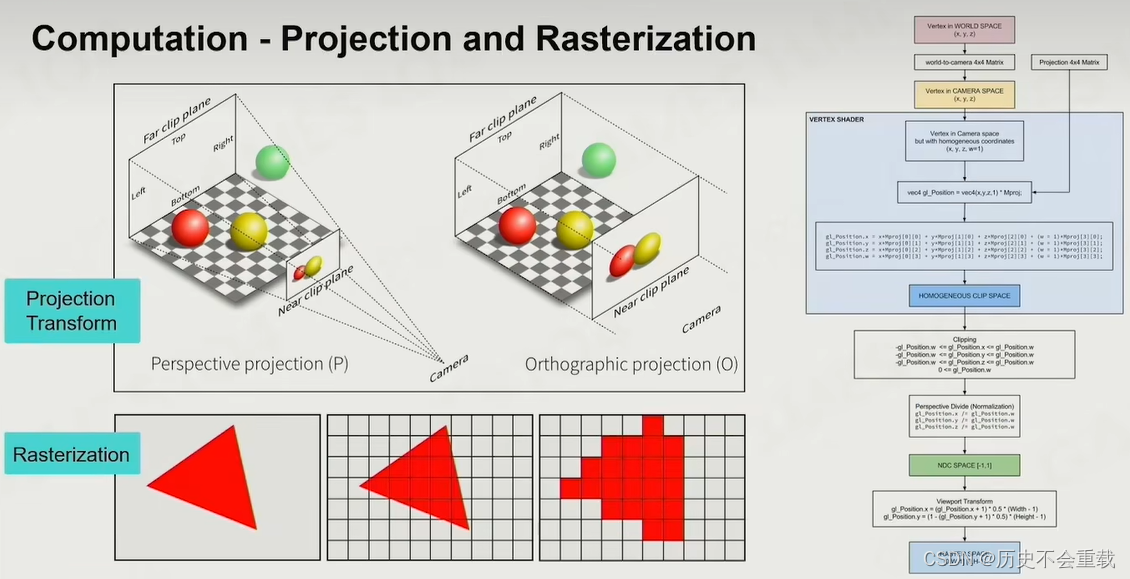
之后进行shader,不管是计算phong模型还是其他都需要进行大量的常数的访问、变量的访问、加减乘除的运算,再加上texture的访问才能得到想要的结果。其中texture采样纹理的过程可能会特别的复杂昂贵,当采样一个像素的texture需要采样两层的纹理,再进行插值(假如每层需要采样4个点,则总共需要进行7次插值),整个过程需要大量的数学运算。

二、可渲染的物体
游戏中的大部分物体都是Game Object(GO),而这只是逻辑上的表达,与这里提到的可绘制(Renderable)的物体加以区分。GO是由组件(Component)组成的,当一个组件存储Renderable,我们才能去绘制它,所以这个Renderable才是我们需要绘制的对象。
一个Renderable的构成通常包括网格(Mesh)、材质(Material) 、纹理(Texture)等。构建一个Mesh,我们通常先需要进行对每个三角形的定义,包括顶点、颜色、法线等,如果将每个三角形都进行存储这样显然是十分笨重的。当今的方法通常运用Vertex Data(存储顶点)和Index Data(存储三角索引)进行存储,由于大部分的顶点都是多三角形公用的,这种存储方式能将存储效率提升六倍以上。
这里有一点注意的是,我们在定义顶点的时候都要给顶点定义一个法线方向。这样就可以避免在生成硬表面(明显折痕,两个面的顶点重合)的时候产生错误。

除了材质和纹理,Shader的作用也十分重要。Shader是一小段代码,目的就是告诉计算机需要将哪种材质哪种纹理绘制在一起,这也是Renderable必要的数据。
之后我们会发现,一个模型不能单单由一种材质构成,现代引擎的做法是将整个模型的Mesh划分成多个Submesh,每个Submesh都能单独调用一个Shader。

当然,在庞大的GO数量下,每个模型如果都需要单独存储Submesh会大大的浪费空间。实际设计游戏我们会发现,大部分的材质都是相同的,因此现代引擎会给出一种资源池(Resource Pool) 来解决这个问题。不管是Mesh、Shader还是Texture,我们都分类存放在对应的资源池当中,在使用的时候直接调用,这样就可以以最小的空间进行存储。
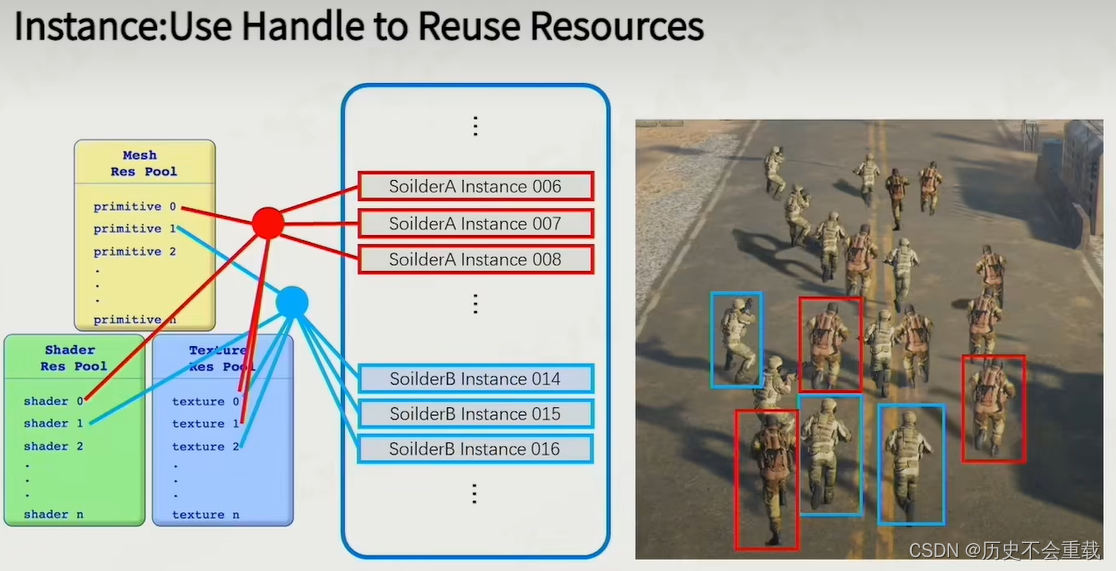
这里提到了一个细节,在使用GPU加载场景的过程中,相同材质同时加载的速度往往快于按其他顺序加载,即使计算量相同,但是按照材质进行排序加载往往会有更好的加载效果。
三、可见性裁剪
可见性裁剪(Visibility Culling)是绘制系统最基础的一个部分。我们可观察的空间是一个锥形, 实际上我们只需要加载在这个锥形之内的GO即可。现在最常用的方法是BVH,这个方法虽然并非查找最高效的,但是现在游戏会有很多运动的GO,我们要去不断构建树,所以更应该追求构建和查询相平衡的方式。

还有另一个重要是思想是PVS(Potential Visibility Set),这个思想最开始是用于作可视化的,现在很少这么做,但是对于资源加载,这个思想仍然是高效的。简单来说,我们会将一个世界分成多个区域,如果能在当前区域观察到其他区域,则同样需要加载那些区域。

随着GPU的高速发展,GPU-based往往是最高效的。这里提到了一种Occlusion Culling的做法,场景中的物体因被遮挡对于当前摄像机为不可见时,可以不对其进行渲染。要注意与视锥体剔除进行区分,视锥体剔除是不渲染摄像机视锥范围之外的物体,被其它物体遮挡但仍在视锥范围之类的物体不会被剔除。使用遮挡剔除时视锥体剔除依然有效。
四、纹理压缩
存储纹理时需要进行纹理压缩,然而这个压缩过程不能用常见的高效的压缩算法,因为那些算法得出的数据无法进行随机访问。这里提出了一个非常经典的压缩算法Block Compression,即在每个块中存储最亮的颜色和最暗的颜色,以及每个点离最大值\最小值近的比例关系,近似的去表示这个色块的颜色。这种算法是非常高效的,通常可以保证实时性。















 3217
3217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









