







目录
4.3Local Response Normalization
一.Abstract

AlexNet训练了一个大型的深度卷积神经网络,该神经网络由5个卷积层和三个全连接层组成,有6000万个参数和65万个神经元 ,其中卷积层中部分是最大池化层,最后由1000路softmax组成。为了更好的正则化,使用了dropout,并被证明效果很好。最后在ILSVRC-2012竞赛中以15.3%的错误率远超第二26.2%。
二.Introduction


1.第一段中提到目前对象识别的主要方法是使用机器学习方法,为了更好的提高模型精度,需要更大的数据集和更好的技术。随着发展在2010年已经有了新的更大的数据集(如LabelMe,ImageNet)
2.因此在数以万计的图像中学习成千上万的物体成为重中之重,CNN是一种具有大量先验知识的模型,它通过改变深度和广度控制对图像识别的能力。
3.随着GPU的发展,GPU和高度优化的2D卷积结合可以促进CNNN训练,而且ImageNet提供了大量的数据集以保证模型不出现过拟合
4.本文在ILSVRC比赛中使用ImageNet训练了5个卷积层3个 全连接层的神经网络,并且发现去掉任何一个都会导致性能下降
5.最后,网络在GTX580 3GB的GPU训练5-6天,并且实验结果表明只要有更好的GPU和数据集训练结果就会得到显著改善
三.The DataSet

AlexNet使用ImageNet数据集训练,因为ImageNet分辨率不固定,但AlexNet需要输入256*256的图片,因此对图像进行降采样到256*256。
四.The Architecture

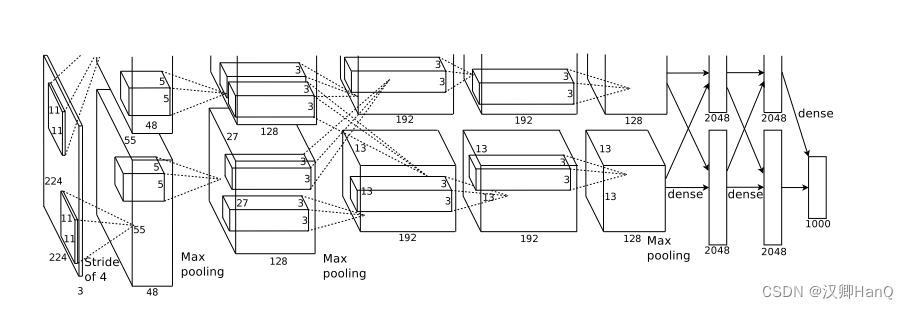
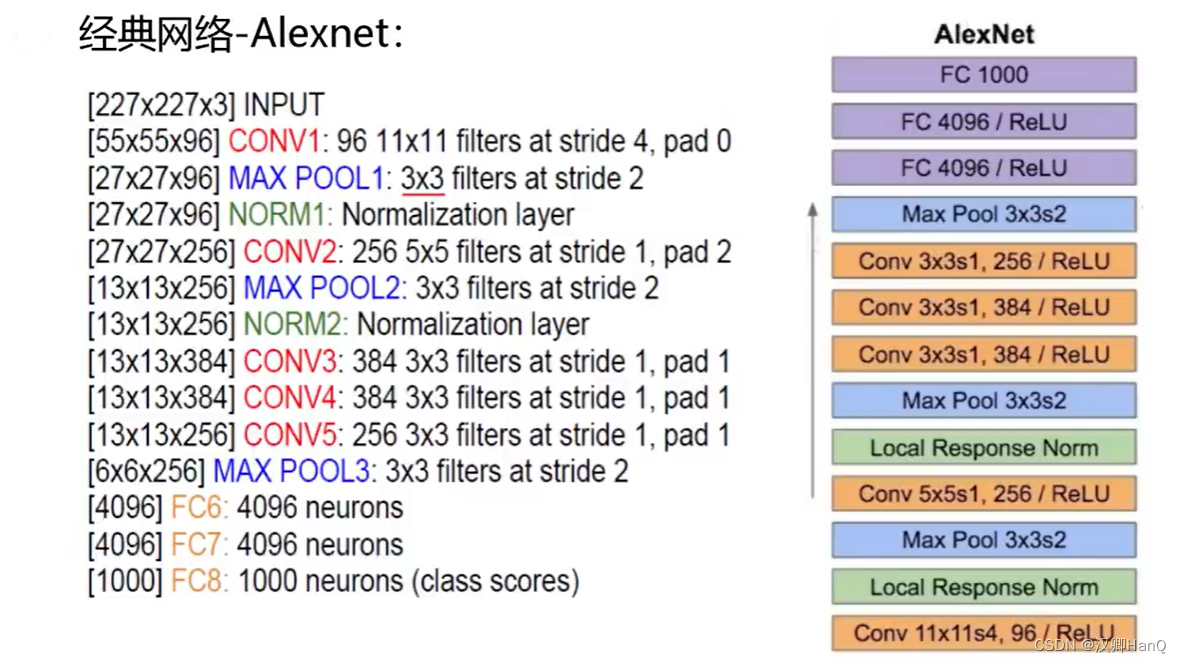
AlexNet采用了5个卷积层,3个池化层,3个全连接层和2个LR层,其中已经被淘汰的有:第一个为11*11的卷积核(淘汰),没有padding填充,LR层(淘汰)
Q:为什么使用两个卷积层?
个人理解:全连接层的作用是将之前卷积层和池化层提取的高级特征转化为对图像进行分类的概率分布,将二维特征图转化为一维向量。因此使用两个全连接层可以
1.允许网络具有更大的容量从而可以学习更复杂的特征和抽象,提高复杂度和表达能力
2.第一个FC将高级特征融合,第二个FC映射为类别概率
3.两个FC加入Dropout防止过拟合
以上为我目前所学的理解范围,如果有错误请大家在评论区指出错误,欢迎大家批评指正
4.1激活函数
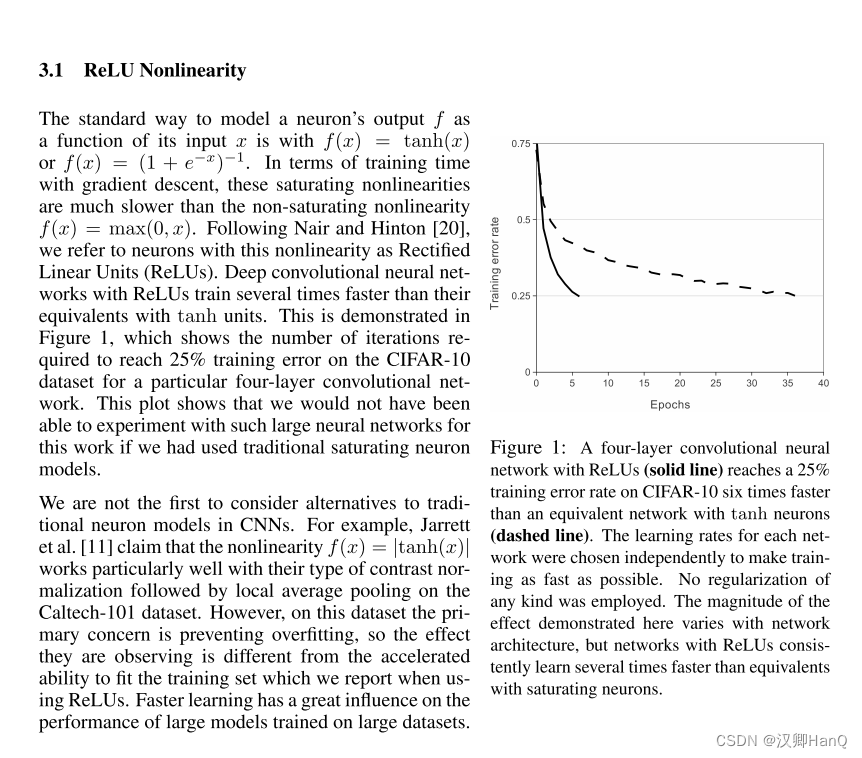
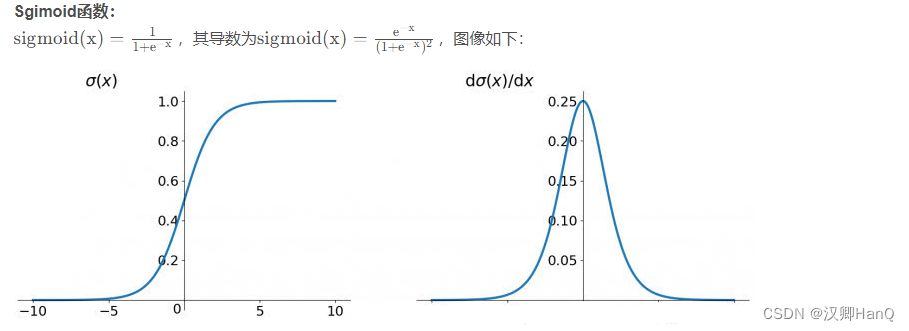
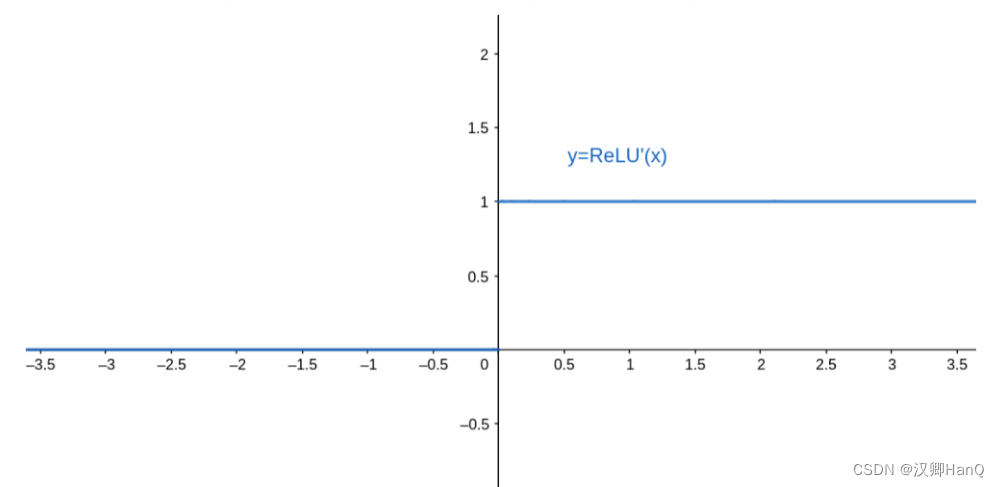
AlexNet选择了Relu激活函数,传统的sigmoid激活函数由于值越小梯度越接近0导致梯度消失已经被淘汰(后面由于relu没有负梯度也被改进)

这里扩充一下饱和函数和非饱和函数
右饱和:
当x趋向于正无穷时,函数的导数趋近于0,此时称为右饱和。
左饱和:
当x趋向于负无穷时,函数的导数趋近于0,此时称为左饱和。
饱和函数和非饱和函数:
当一个函数既满足右饱和,又满足左饱和,则称为饱和函数,否则称为非饱和函数。
常用的饱和激活函数和非饱和激活函数:
饱和激活函数有如Sigmoid和tanh,非饱和激活函数有ReLU;相较于饱和激活函数,非饱和激活函数可以解决“梯度消失”的问题,加快收敛。
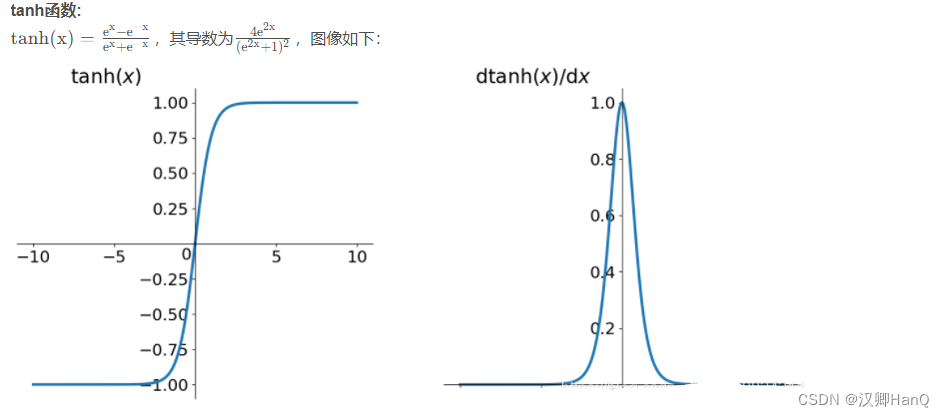
4.2Training on Mutiple GPUs

因为GTX 580只有3GB内存,作者将网络分布在两个GPU上,并且有效的降低了错误率和提升了训练速度
4.3Local Response Normalization

在Relu层之前加入了局部归一化,来使Relu避免过拟合效果更好,其公式为:
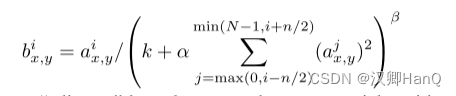
4.4Overlapping Pooling

一般来说两个pooling是不重叠的,这里通过改进方法,达到了略微提升的效果
4.5Overall Architecture

整个过程就是一张图片,经过模型处理变为了一个4096维的向量,这个向量可以把中间的语义信息表示出来,最后通过softmax实现1000分类。机器学习可以认为是一个压缩知识的过程;具体来讲就是我们原始的一个图片,文字或者视频输入到一个模型中,这个模型就会把它压缩为一个向量,这个向量机器可以识别,用来实现别的任务,例如分类等等。
五.Reducing Overfitting

由于神经网络体系有6000万参数构成,虽然1000分类增加了约束,但是还需要其他方法
5.1Data Augmentation

减少过拟合最简单那也是最常见的方法就是使用保存标签的变化,人为的扩大数据集
1.从256*256随机抽取224*224,这使得训练规模增加了2048倍(训练示例是高度依赖的)
2.采用PCA的方式对RBG的Channels进行了一些改变,使图像发生了一些变化,从而扩大了数据集
5.2Dropout
在全连接层以50%的概率神经元随机失效,实现了L^2正则化的功能,以避免模型过拟合
六.Detail of Learning

6.1SGD随机梯度下降
我们使用随机梯度下降法(SGD)训练我们的模型,批量大小为128,momentum为0.9(对传统SGD增加了动量这个观点,来解决传统SGD的一些问题,例如优化过程非常不平滑或者梯度下降很低效的时候),weight decay为0.0005(可以理解为是一个L2的正则化项,用在优化算法上而不是模型上)。我们发现,这种少量的weight decay对模型的学习很重要。换句话说,这里的weight decay不仅仅是一个正则化器:它减少了模型的训练误差。权重w的更新规则为
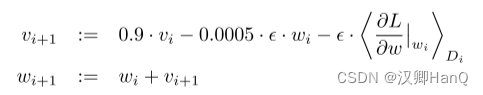
6.2参数初始化
用均值为0 ,方差为0.01的高斯随机变量去初始化了权重参数(0.01是一个非常好的数,不大也不小,如果网络过大,例如BERT ,我们才用到0.02)。然后偏置bias也进行了初始化,不过这里不太重要,因为数据平衡的话初始为0最好,但是这里初始1效果更好一些,这个地方也没有继续深入研究
6.3学习率
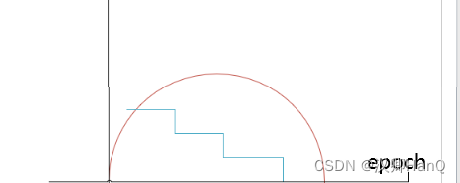
我们在所有层上使用相同的学习率,设为0.01。但验证误差不降的时候我们就手动的乘以0.1,也就是降低十倍。也有自动的方法,例如Resnet,训练120轮epoch,初始学习率也是设为0.01,每30轮降低十倍,本文是训练了90个epoch,每一次是120w张图片。当然现在我们都不采用十倍十倍去降低了,我们采用更平滑的降低方式,例如利用cos函数去降低,如下图,蓝色线为本文中的降低方式,十倍十倍去降,红色线是我们现在用的,一开始学习率设的大一些,慢慢下降,这样更高效。
七.Resuls

八.Disussion

又是一个没有结论的论文,
结果表明,神经网络使用监督学习效果很好,而且其中的卷积层都很重要
为了简化实验,没有使用无监督训练,虽然已经有所改善,但还有很多工作要做,特别是视频检测上
九.Innovation point
1.大规模神经网络:AlexNet是第一个在ImageNet数据集上采用大规模深度卷积神经网络的尝试。它有5个卷积层和3个全连接层,共计超过60百万个参数。这使得AlexNet成为当时最大和最深的神经网络,显著增加了网络的表达能力和学习能力。
2.Relu激活函数:AlexNet采用了ReLU(Rectified Linear Unit)作为激活函数,相较于传统的Sigmoid函数,ReLU在训练过程中能够更好地缓解梯度消失问题,加速网络的训练,并且有助于解决梯度爆炸的问题。ReLU的使用在后续深度学习模型中得到广泛应用。
3.Dropout:AlexNet引入了Dropout技术,即在训练过程中随机地丢弃一部分神经元,从而减少过拟合的风险,提高网络的泛化能力。Dropout的使用在深度学习中成为了一种常见的正则化方法。
4.数据增强技术:AlexNet在训练过程中采用了数据增强技术,通过对输入图像进行随机裁剪、水平翻转等操作,增加了训练数据的多样性,提高了网络的鲁棒性和泛化能力
5.GPU加速:由于AlexNet的规模庞大,其训练过程需要大量的计算资源。为了加速网络的训练,AlexNet采用了GPU(图形处理单元)来进行并行计算,这使得网络的训练速度大幅提升,成为了后续深度学习模型采用GPU进行训练的先例。
6.重叠的最大池化:此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
7.LRN层:提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型泛化能力。















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









